Die Nutzung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren in zahlreichen Bereichen der Künstlichen Intelligenz enorm an Bedeutung gewonnen. Ob in der Textgenerierung, Datenextraktion oder komplexen Problemlösung – diese Modelle zeigen eine beeindruckende Leistungsfähigkeit. Dennoch ergeben sich in speziellen Anwendungsfällen immer wieder Herausforderungen, die durch die Art und Weise entstehen, wie Ausgaben der Modelle formatiert werden. Insbesondere strukturierte Ausgaben, etwa als JSON-Format, bringen bei vielen Aufgaben eine unerwartete Einschränkung der Modellleistung mit sich. Genau hier setzt das neue Modell Osmosis-Structure-0.
6B an und präsentiert eine Lösung, die auf den Prinzipien des Verstärkungslernens beruht, um diese Leistungseinbußen deutlich zu reduzieren. Strukturierte Ausgaben sind in der Praxis sehr gefragt, denn sie erlauben eine klare, maschinenlesbare Organisation der Informationen, die ein Modell generiert. Häufig werden unstrukturierte Texte in strukturierte Datenobjekte überführt, um sie für automatisierte Verarbeitungsschritte nutzbar zu machen. Häufig wird hierfür ein vorgegebenes Schema eingefordert, das der Ausgabe eine feste Form gibt, etwa eine verschachtelte JSON-Struktur mit klar definierten Feldern und Datentypen. Diese Strukturierung ist vor allem in Bereichen wie Datenextraktion, Automatisierung von Workflows oder analytischer Datenverarbeitung essenziell.
Doch ein erhebliches Problem tritt auf, wenn man große Sprachmodelle zwingt, sich strikt an eine vorgegebene Struktur zu halten. Durch das Erzwingen eines Schemas wird der kreative und flexiblere Denkprozess des Modells eingeschränkt. Das Modell „denkt nicht mehr frei“, sondern versucht nur, die Formatvorgaben einzuhalten. Dies führt gerade bei komplexen kognitiven Aufgaben zu einem deutlichen Einbruch der Leistung – die Genauigkeit bei der Lösung von Rechenaufgaben, natursprachlichen Inferenzproblemen oder mehrstufigen Rückschlüssen sinkt. Das Konzept des strukturieren Outputs ist also in gewissen Kontexten Fluch und Segen zugleich.
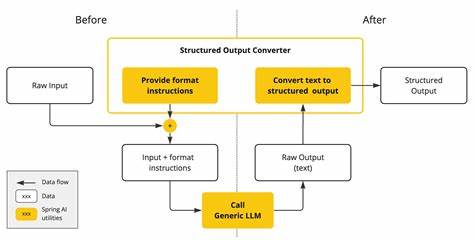
Es bringt gute maschinenlesbare Ergebnisse, aber die Fähigkeit der Modelle kann unter den Restriktionen leiden. Gon eine pergusLautsche verfahren Vor diesem Hintergrund hat das Team hinter Osmosis einen innovativen Ansatz entwickelt, der die Probleme herkömmlicher strukturierter Ausgabeformate durchbricht. Sie haben einen kleinen, spezialisieren Nachfolge-LLM namens Osmosis-Structure-0.6B trainiert, das mithilfe von Verstärkungslernen (Reinforcement Learning) die Aufgabe übernimmt, unstrukturierte Ausgaben großer Modelle in strukturierte Ausgaben umzuwandeln. Die Besonderheit dieses Modells ist, dass es nicht darauf angewiesen ist, dass das große Modell schon perfekt strukturierte Ausgaben generiert.
Stattdessen erzeugt das Große Modell zunächst eine unstrukturierte Antwort. Osmosis-Structure-0.6B erhält dann diese unstrukturierte Antwort zusammen mit der gewünschten Ausgabestruktur als Eingabe und transformiert sie in ein korrekt formatiertes, strukturiertes JSON-Dokument. Diese Denkweise erlaubt es, die kreativen Fähigkeiten des großen Modells ohne künstliche Beschränkungen einzusetzen und erst im Nachgang eine präzise Strukturierung vorzunehmen. Durch diese Entkopplung von Inhaltserzeugung und Strukturierung können beide Prozesse unabhängig voneinander optimiert werden.
Um die Effektivität dieses Ansatzes zu validieren, wurde Osmosis-Structure-0.6B mit diversen aktuellen großen Modellen von Anthropic und OpenAI getestet. Dabei wurden mathematische Testsets wie der AIME (American Invitational Mathematics Examination) von 1983 bis 2024 sowie das DAPO-Math-17k-Processed Datenset herangezogen. Die Leistung der Modelle mit traditioneller strukturierter Ausgabe wurde mit der Leistung verglichen, bei der unstrukturierte Ausgaben erst von Osmosis-Structure-0.6B in strukturierte Form gebracht wurden.
Die Ergebnisse waren beeindruckend: Die Genauigkeit stieg signifikant, insbesondere für die Modelle Sonnet 4, Opus 4 und GPT-4.1. Das Modell OpenAI o3 zeigte eine vergleichsweise gute Leistung auch bei strukturierter Ausgabe, womöglich, weil intern ein ähnliches „zweistufiges“ Verfahren mit einer Validierung durch ein kleines Modell angewandt wird – vergleichbar mit der Funktion von Osmosis. Zudem zeigte sich, dass die Zeit bis zur Fertigstellung der Ergebnisse bei GPT-4.1 mit Osmosis-unterstützter Strukturierung signifikant niedriger als bei direkter strukturierter Ausgabe war.
Praktisch hat sich zudem gezeigt, dass Nutzer im Produktionsumfeld oft genau das tun, was Osmosis beinahe automatisch ermöglicht: Sie lassen teurere große Modelle unstrukturierte, freie Antworten liefern und greifen für die Strukturierung auf kleinere, günstigere Modelle zurück. Osmosis-Structure-0.6B stellt hier eine effiziente, offene Alternative für das Strukturieren von Ausgaben dar, die das Kosten-Nutzen-Verhältnis verbessern kann. Der Trainingsprozess von Osmosis-Structure-0.6B erfolgte mit einer hochskalierten Datenbasis aus etwa 500.
000 synthetisch generierten Beispielen. Diese Trainingsdaten beinhalten diverse Szenarien, in denen ein strukturierter Output erforderlich ist, wie etwa mehrstufige Begründungen bei mathematischen Lösungswegen, komplexe Datenextraktion und die Formatierung von komplex verschachtelten JSON-Dokumenten. Das Modell wurde mittels einer Belohnungsfunktion trainiert, die anhand der korrekten Übertragung von Wertfeldern aus dem Inputtext in das strukturierte Output entscheidet. Somit konnte der Trainingsprozess eine erhebliche Optimierung der Modellleistung im Bereich der Strukturierung erreichen. Die Entwicklung von Osmosis-Structure-0.
6B markiert einen wichtigen Fortschritt im Umgang mit strukturierten Ausgaben in großen Sprachmodellen. Anstatt die leistungsfähigen Modelle direkt in ein festes Format zu pressen, wird mit einer zweistufigen Methode ein „Best of both Worlds“-Ansatz verfolgt: Freie kreative Antwortgenerierung plus präzise Strukturierung durch spezialisiertes Nachfolgemodell. Für die Praxis bedeutet das verbesserte Genauigkeit in Bereichen wie mathematischen Problemlösungen, komplexer Datenextraktion und multimodaler Informationsaufbereitung. Gleichzeitig sinken die Kosten, weil weniger teure Modelle die strukturierende Aufgabe übernehmen können. Auch die Verarbeitungszeit verbessert sich, da einzelne Schritte klarer getrennt und teilweise parallelisiert werden können.
Die gesamte Entwicklung ist ein Paradebeispiel dafür, wie moderne Techniken des maschinellen Lernens, wie das Verstärkungslernen, Lösungen für sehr konkrete technische Herausforderungen bieten. Osmosis hebt damit potenziell ein fundamentales Hindernis bei der Nutzung strukturierter Ausgaben auf, wie es in vielen industriellen Anwendungsfällen existiert, und öffnet neue Türen für die effiziente und präzise Datenverarbeitung mit KI. Wer tiefer in die Materie von Verstärkungslernen beim Training von Sprachmodellen eintauchen möchte oder sich für die technische Umsetzung von Osmosis-Structure-0.6B interessiert, kann den Kontakt zum Entwicklungsteam suchen. Die Modelle sind als Open Source verfügbar und können auf Plattformen wie Hugging Face oder Ollama heruntergeladen und direkt eingesetzt werden.
Insgesamt zeigt sich, dass die Zukunft strukturierter Ausgaben im Zusammenspiel spezialisierter Modelle liegen kann, die gemeinsam ein optimales Ergebnis erzielen. Osmosis-Structure-0.6B ist ein vielversprechender Schritt in diese Richtung und bietet neue Impulse, wie das volle Potential von großen Sprachmodellen trotz restriktiver Formatvorgaben genutzt werden kann.