DeepSeek-R1 hat seit seiner Einführung für einiges Aufsehen gesorgt. Seine fortgeschrittenen Fähigkeiten im Bereich der logischen Schlussfolgerung und sein leistungsfähiger Ansatz zur Textzusammenfassung werden von vielen Anwendern geschätzt. Dennoch gibt es eine auffällige Problematik, die das Modell umgibt und die Aufmerksamkeit von Forschern und Nutzern gleichermaßen auf sich gezogen hat: Die hohe Neigung von DeepSeek-R1 zu sogenannten Halluzinationen. Diese treten auf, wenn das Modell Informationen erzeugt, die nicht aus den vorgegebenen Ausgangsdaten stammen und daher nicht überprüfbar oder sogar falsch sein können. Im Vergleich zu seinem Vorgänger DeepSeek-V3 weist DeepSeek-R1 dabei eine erstaunlich viel höhere Halluzinationsrate auf, die laut Studien bei 14,3 Prozent liegt – gegenüber lediglich 3,9 Prozent bei DeepSeek-V3.
Doch warum ist das so? Und ist diese höhere Halluzinationsrate tatsächlich eine notwendige Begleiterscheinung seiner komplexeren Denkprozesse? Zu Beginn gilt es zu klären, ob das erweiterte Fähigkeitsspektrum von DeepSeek-R1 im Bereich des logischen Denkens und der Schlussfolgerung die Ursache für diese vermehrten Halluzinationen sein könnte. Auf den ersten Blick scheint es plausibel, dass Modelle, die komplexere Denkwege beschreiten, mehr Risiken hinsichtlich falscher oder nicht belegter Informationen eingehen. Relevante Daten aus der Halluzinations-Statistik verschiedener LLMs (Large Language Models) zeigen, dass Modelle mit einem Fokus auf reasoning tatsächlich tendenziell höhere Halluzinationsraten aufweisen als solche, die primär auf reine Textgenerierung ausgerichtet sind. Trotzdem offenbaren weitergehende Experimente überraschende Erkenntnisse. Eines dieser Experimente beinhaltete das sogenannte Einspritzen von „Denk-Schritten“ von DeepSeek-R1 in den Prompt des Vorgängermodells DeepSeek-V3.
Dabei wurde DeepSeek-V3 angewiesen, nicht nur einfach eine Antwort zu formulieren, sondern die Denkprozesse von DeepSeek-R1 zu replizieren und dabei eine kurze Zusammenfassung zu generieren. Interessanterweise führte diese Vorgehensweise nicht zu einem Anstieg der Halluzinationsrate bei DeepSeek-V3, sondern diese sank sogar unter den Originalwert von 3,9 Prozent auf 3,3 Prozent. Zudem reduzierte die simple Aufforderung „Let’s think step-by-step“ an DeepSeek-V3 die Fehlerquote sogar auf magere 1,5 Prozent. Diese Ergebnisse legen nahe, dass reasoning an sich nicht der treibende Faktor für die vermehrten Halluzinationen bei DeepSeek-R1 ist. Die Frage, warum DeepSeek-R1 dennoch mehr halluziniert, muss folglich tiefer greifen.
Ein genauerer Blick auf die Art der Halluzinationen bringt neue Perspektiven hervor. Viele dieser Fehler sind sogenannte „benigne Halluzinationen“. Das bedeutet, dass DeepSeek-R1 zwar Informationen erzeugt, die im Quelltext nicht enthalten sind, diese aber dennoch plausibel, kontextuell sinnvoll und durch Allgemeinwissen gedeckt sind. So wird beispielsweise in einem Testfall ein Wissen über ein Fernsehformat hinzugefügt, das zwar nicht explizit im Basistestartikel erwähnt wird, aber dem Modell aufgrund seiner allgemeinen Weltkenntnis plausibel erscheint. Diese Art der Halluzination wird als weniger kritisch bewertet, da sie die Nutzererfahrung nicht unmittelbar beeinträchtigt, da sie für den Betrachter logisch und nachvollziehbar erscheint – im Gegensatz zu falschen oder irreführenden Behauptungen.
Was macht DeepSeek-R1 dann so „überhilfreich“? Es scheint, als versuche das Modell aktiv, den Nutzer durch das Hinzufügen relevanter Informationen zu unterstützen, selbst wenn diese Informationen formal nicht im Input-Dokument vorhanden sind. Diese Eigenschaft war offenbar Teil des Trainingsansatzes, bei dem das Modell darauf konditioniert wurde, mehr Kontext einzubringen und so in gewisser Weise über das Quellmaterial hinauszugehen. Dies ist ein zweischneidiges Schwert: Einerseits steigert es scheinbar den Wert der Antwort durch Bereicherung mit Hintergrundwissen und Die Tendenz zu ausführlicheren, detailreicheren Antworten. Andererseits steigt die Gefahr, dass diese Zusatzinformationen vom Nutzer als verbindliche Fakten missverstanden werden und somit Fehlinterpretationen entstehen können. Um die Qualität der Halluzinationserkennung bei DeepSeek-R1 zu messen, wurden Validierungen durch menschliche Annotatoren durchgeführt.
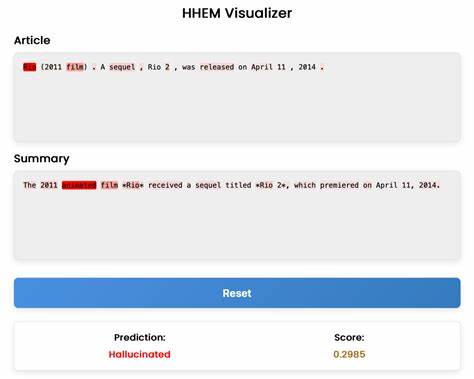
Interessanterweise bestätigten diese die hohe Anzahl an Halluzinationen bei R1 – jedoch mit einem hohen Anteil von benignen Halluzinationen. Die Studie zeigte, dass rund 71,7 Prozent der als halluzinierend bewerteten Aussagen bei R1 als harmlos oder sogar erwünscht eingestuft wurden, da sie durch Allgemeinwissen gedeckt sind. Darüber hinaus wird das Problem deutlich, dass viele bestehende automatisierte Bewertungssysteme Halluzinationen nicht differenziert erfassen können. Klassische „LLM-as-a-Judge“-Ansätze, also Modelle, die Halluzinationen anderer Modelle beurteilen sollen, zeigen oft Schwächen insbesondere bei benignen Halluzinationen. Das entwickelte Modell HHEM (Hallucination-Harmlessness-Evaluation-Metric) vermeidet diese Fehlbeurteilungen besser und weist eine hohe Übereinstimmung von 88 Prozent zur menschlichen Bewertung auf, was es zu einem vielversprechenden Werkzeug zur Beurteilung der Qualität von Textausgaben macht.
Die Erkenntnisse zeigen auch, dass die Art des Trainings von DeepSeek-R1 möglicherweise stärker auf die Erzeugung zusätzlicher Kontextinformationen ausgelegt ist – eine Designentscheidung, die zwar die Nützlichkeit steigert, aber gleichzeitig das Risiko von Halluzinationen erhöht. Somit handelt es sich um keinen Fehler im Modell an sich, sondern eher um eine bewusste oder unbeabsichtigte Konsequenz aus der Balance zwischen Kreativität, Wissenserweiterung und Faktenbindung. Für Nutzer und Entwickler ist es deshalb essenziell zu verstehen, dass die Nutzung von DeepSeek-R1 in Szenarien, in denen hohe Faktengenauigkeit entscheidend ist, vorsichtig geschehen sollte. Besonders in regulierten Branchen oder sicherheitskritischen Anwendungen kann das Risiko akzeptabler, aber falscher oder überflüssiger Zusatzinformationen problematisch sein. Im Gegensatz dazu könnten Anwendungsfälle, bei denen ein erweitertes Hintergrundwissen willkommen ist und eine gewisser Grad an “Überhilfe” tolerierbar ist, von DeepSeek-R1 profitieren.
Zusammenfassend lässt sich sagen, dass DeepSeek-R1s hohe Halluzinationsrate weniger mit einer Schwäche in der logischen Denkleistung zusammenhängt als vielmehr mit seiner Tendenz, kontextuell plausibel erweiterte Informationen einzufügen. Dies hebt hervor, wie wichtig es ist, bei der Entwicklung von LLMs ein ausgewogenes Verhältnis zwischen kreativem Schaffen und strikter Quellenbindung zu finden. Werkzeuge wie HHEM können dabei helfen, diesen Balanceakt zu überwachen und die Qualität der generierten Inhalte zu gewährleisten. Die Forschung zu Halluzinationen in KI-gestützten Textmodellen bleibt ein dynamisches Feld. Vectara und andere Unternehmen investieren kontinuierlich in bessere Trainingsmethoden, verbesserte Bewertungsmetriken und transparente Plattformansätze, um den Einsatz dieser Modelle verantwortungsvoll und vertrauenswürdig zu gestalten.
Bis solche Fortschritte vollständig umgesetzt sind, bleibt DeepSeek-R1 ein kraftvolles, jedoch mit Vorsicht einzusetzendes Werkzeug mit besonderem Potenzial in Kreativ- und Supportkontexten – jedoch mit klarer Notwendigkeit zur Evaluation und kritischen Nachprüfung der generierten Inhalte. Insgesamt zeigt die Analyse von DeepSeek-R1, dass erhöhte Halluzinationen nicht zwingend auf eine fehlerhafte Modellarchitektur oder schlechtes Training zurückzuführen sind, sondern vielmehr auf intelligente, wenn auch manchmal unnötige Erweiterungen des Basiswissens zurückgehen. Die Berücksichtigung dieser Dynamik wird für die zukünftige Gestaltung von Sprachmodellen und deren praktische Anwendungen entscheidend sein.