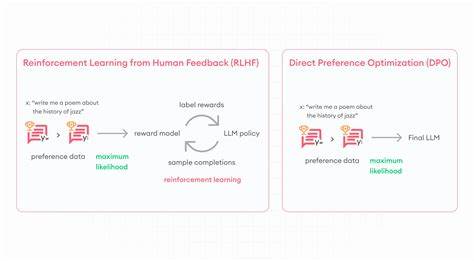
Die rasante Entwicklung von großen Sprachmodellen in den letzten Jahren hat die Art und Weise revolutioniert, wie Künstliche Intelligenz (KI) mit Menschen interagiert. Doch um diese Modelle wirklich nutzerzentriert, hilfreich und zuverlässig zu machen, reicht es nicht aus, sie nur mit Standarddaten zu trainieren. Es bedarf gezielter Techniken, die Sprachmodelle anhand menschlicher Vorlieben optimieren. Hier stoßen zwei Ansätze in den Fokus: Direct Preference Optimization (DPO) und Reinforcement Learning from Human Feedback (RLHF). Beide zielen darauf ab, KI-Modelle so zu trainieren, dass sie Antworten generieren, die für Nutzer nicht nur korrekt, sondern auch angenehm und sinnvoll im Kontext sind.
Dennoch unterscheiden sie sich grundlegend in ihrer Methodik und Komplexität. Direkt Preference Optimization, kurz DPO, setzt auf eine direkte Anpassung des Modells anhand von Vergleichsdaten menschlicher Präferenzen ohne den Einsatz komplexer Verstärkungslernverfahren. Anders als bei RLHF, das einen mehrstufigen Prozess mit der Erstellung und Optimierung eines sogenannten Reward Modells erfordert, basiert DPO auf einfachen Verlustfunktionen, die die Wahrscheinlichkeit bevorzugter Antworten erhöhen und die von abgelehnten verringern. Dadurch wird der Trainingsprozess vereinfacht, ressourcenschonender und schneller, was besonders für Entwickler und Unternehmen interessant ist, die eine effiziente und schlanke Pipeline bevorzugen. Ein anschauliches Bild für DPO ist das Kochen mit einem Rezeptbuch.
Anstatt einen Food-Kritiker zu engagieren und wiederholt neue Gerichte zu testen, passt der Koch direkt seine Rezepte an, indem er Kundenfeedback nutzt. Dabei sorgt ein spezieller Parameter, β genannt, dafür, dass das Modell sich kontrolliert verändert und nicht zu stark von bewährten Grundlagen abweicht. Die Einstellung dieses Parameters erlaubt eine Balance zwischen Innovation und Stabilität. Reinforcement Learning from Human Feedback hat sich in der Sprachmodellforschung als traditionelle Methode zur Modellanpassung etabliert. Die Vorgehensweise sieht vor, zunächst ein Reward Modell zu trainieren, das auf Basis menschlicher Bewertungen bestimmt, wie gut bestimmte Ausgaben des Sprachmodells sind.
Anschließend erfolgt das Reinforcement Learning, häufig mit der Proximal Policy Optimization (PPO), das die Sprachmodell-Policy gegenüber diesem Reward Modell optimiert. Diese Methode ist zwar effektiv, bringt aber eine erhöhte Komplexität mit sich, insbesondere in der Modellarchitektur und im Trainingsmanagement. Zudem erzeugt RLHF oft eine größere Rechenlast, da während des Trainings kontinuierlich online Daten zur Modellbewertung generiert werden müssen. Hinsichtlich der Ergebnisse zeigen Studien, dass DPO in vielen Fällen die Leistungsfähigkeit von RLHF erreichen oder sogar übertreffen kann, ohne deren komplexen Aufbau. Beide Methoden fördern die hilfreiche und präzise Beantwortung von Nutzerfragen, verbessern den Tonfall und fördern die Wahrhaftigkeit sowie die Schadlosigkeit der Antworten.
Besondere Stärken von DPO liegen in vielfältigen Anwendungsfällen, in denen es mehrere valide Antwortmöglichkeiten gibt und das Urteil über deren Qualität subtil und kontextabhängig ist. Beispiele sind Chatbots in spezialisierten Bereichen wie Medizin oder Psychologie, wo eine exakte, aber auch einfühlsame Kommunikation entscheidend ist, sowie bei der Zusammenfassung von Texten, der Code-Generierung und der Schreibassistenz. DPO nutzt die Tatsache, dass es für Menschen oft einfacher ist, zwei Alternativen zu bewerten, als perfekte Antworten zu formulieren. Das macht das Sammeln und Verarbeiten von Trainingsdaten effizienter und ermöglicht gezieltere Verbesserungen bestehender Modelle durch eine feinere Abstimmung. Natürlich ist DPO nicht für alle Aufgaben gleichermaßen geeignet.
Für Szenarien mit eindeutig richtigen Antworten, wie bei der Informationsentnahme, Klassifikation oder mathematischen Berechnungen, bietet der Ansatz keine Vorteile gegenüber klassischen Methoden. Dort ist oft eine direkte, regelbasierte Anpassung oder andere Trainingsverfahren zielführender. Ein pragmatischer Trainingsansatz kombiniert die Vorteile von Supervised Fine-Tuning (SFT) mit DPO. In einem ersten Schritt lernt das Modell mit SFT die Grundlagen einer Aufgabe und die gewünschte Antwortstruktur. Anschließend erfolgt das weiterführende Feintuning mit DPO, wobei der Fokus auf der Optimierung der Präferenzorientierung liegt.
Diese zweistufige Strategie stellt sicher, dass das Modell nicht nur die Grundlagen beherrscht, sondern auch feine Nuancen menschlicher Präferenzen zuverlässig umsetzen kann. Für Entwickler ist es hilfreich, den Einfluss des β-Parameters bei DPO zu beachten, der steuert, wie stark das Modell beim Lernen neuer Präferenzen von seinem Ursprungszustand abweichen darf. Die Anpassung dieses Wertes beeinflusst die Geschwindigkeit und das Ausmaß der Verbesserungen. Außerdem ermöglichen spezifische Metriken wie Genauigkeit der Präferenzunterscheidung und die Berechnung der KL-Divergenz zwischen dem angepassten und ursprünglichen Modell eine gezielte Überwachung des Trainingsfortschritts. Insgesamt bietet die Wahl zwischen DPO und RLHF je nach Projektziel und verfügbaren Ressourcen unterschiedliche Vorzüge.








![Windows was the problem all along [video]](/images/2C241A6D-57CA-4759-B723-751BA4BF985F)