Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die künstliche Intelligenz revolutioniert und ermöglicht inzwischen vielfältige Anwendungsfelder wie Texte generieren, übersetzen, Fragen beantworten und vieles mehr. Um die Leistungsfähigkeit dieser Modelle objektiv zu vergleichen, sind standardisierte Benchmarks essenziell. Einer der wichtigsten Benchmarking-Standards ist der MMLU-Test, der für Massive Multitask Language Understanding steht. Er bewertet die Fähigkeit eines Sprachmodells, komplexe, multidisziplinäre Aufgaben zu lösen, die weit über einfache Textverarbeitung hinausgehen. In den letzten Jahren wurde die Möglichkeit, den MMLU-Benchmark auf unterschiedlichen LLM-Endpunkten auszuführen, ein Schlüsselfaktor für Entwickler, Forscher und Unternehmen, die die Leistungsfähigkeit von KI-Modellen effizient evaluieren möchten.
MMLU wurde entwickelt, um eine breite Palette von Fähigkeiten großer Sprachmodelle zu testen. Das Spektrum der Aufgaben reicht von Fragen zur Geschichte, Mathematik, Naturwissenschaften, Jurisprudenz bis zu Wirtschaftsfragen. Die Testumgebung stellt sicher, dass die Modelle nicht nur oberflächlich Antworten liefern, sondern tatsächlich kontextuelle und fachliche Kompetenz demonstrieren. Aus diesem Grund hat das Benchmark-Tool weltweit an Bedeutung gewonnen, insbesondere beim Wettbewerb zwischen verschiedenen Anbietern von KI-Modellen. Die Möglichkeit, MMLU auf beliebigen LLM-Endpunkten auszuführen, bedeutet, dass man nicht an ein komplettes Ökosystem gebunden ist.
Gerade im Zeitalter von Cloud-Computing und API-gesteuerter KI-Nutzung ist die Flexibilität eine große Stärke. Entwickler können bequem ein Modell ihrer Wahl über einen API-Endpunkt ansprechen, sei es Borg Cloud, OpenAI, Google AI Studio, LLaMA.com oder OpenRouter. Diese Dienste bieten unterschiedliche Modelle mit variierenden Spezifikationen, Kostenstrukturen und Zugangsvoraussetzungen an. Ein besonders spannender Aspekt ist der Einsatz von sogenannten „Leichtversionen“ des MMLU-Benchmarks, welche eine schnellere Evaluierung ermöglichen.
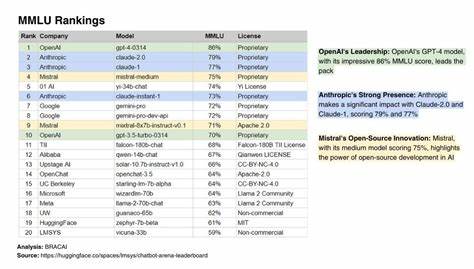
Diese „MMLU-Light“-Varianten verkürzen die Laufzeit und schaffen es dennoch, aussagekräftige Ergebnisse zu liefern. Für Unternehmen mit hohem Evaluierungsbedarf und Forscher, die verschiedene Modelle vergleichen möchten, bieten diese schnelleren Versionen eine kosteneffiziente und zeitsparende Lösung. Die jüngsten Ergebnisse zeigen, wie unterschiedlich die Leistungen der einzelnen Modelle ausfallen können. Modelle wie Llama-4-Scout-17B-16E-Instruct-FP8(Light), die über api.llama.
com gehostet werden, erreichen beeindruckende Genauigkeiten von nahezu 85 Prozent. Andere Varianten wie Llama-3.3-70B-Instruct(Light) und gemma-3-27b-it vom Google Service generativelanguage.googleapis.com erzielen Werte knapp unter 80 Prozent.
Diese differenzierten Leistungsanalysen helfen Unternehmen bei der Auswahl eines passenden Modells, basierend auf den individuellen Anforderungen wie Genauigkeit, Schnelligkeit oder Ressourcenverbrauch. Die Transparenz bei den Benchmarkergebnissen hat zudem einen großen Einfluss auf das Vertrauen der Nutzer in ein KI-Angebot. Öffentliche Modellresultate zu teilen, schafft eine gemeinschaftliche Grundlage für die Weiterentwicklung und den fairen Wettbewerb innerhalb der KI-Branche. Aus diesem Grund gewinnen Plattformen an Relevanz, die nicht nur einzelne Benchmarks durchführen, sondern auch umfassende Übersichten und Vergleichsmöglichkeiten eröffnen. Für die Nutzung der verschiedenen API-Endpunkte ist es wichtig, entsprechende Zugangstoken oder Authentifizierungsmechanismen zu verstehen und korrekt einzusetzen.
Diese Sicherheitsprotokolle schützen nicht nur die Systeme selbst, sondern sichern auch die Daten der Nutzer bei der Übertragung ab. Für Entwickler bedeutet dies, sich mit den jeweiligen Dokumentationen auseinanderzusetzen, um den Benchmark reibungslos einzubetten und auszuführen. Neben der reinen Leistungsbewertung ist das Benchmarking auch ein wichtiger Schritt zur Identifikation von Stärken und Schwächen der jeweiligen Modelle. Erkenntnisse aus MMLU-Tests fließen oft direkt in Verbesserungen ein, sei es durch Anpassung der Trainingsdaten, Optimierung der Modellparameter oder Implementierung neuer Algorithmen. Die stetige Iteration und das gezielte Benchmarking wirken somit als Triebkraft hinter der kontinuierlichen Weiterentwicklung moderner KI-Systeme.
In der Praxis profitieren viele Anwender von dieser flexiblen und cloudbasierten Benchmark-Option. Unternehmen können mit minimalem Aufwand eigene Vergleichsstudien anstellen, ohne umfangreiche Infrastruktur investieren zu müssen. Gleichzeitig unterstützen solche Lösungen Forscher und Entwickler dabei, neuartige Modelle schneller zu evaluieren und erste Marktreaktionen einzuholen. Zukunftsorientiert zeigt sich die Möglichkeit, Benchmarking-Plattformen mit weiteren Tools wie etwa einer Arena zu verbinden. Dort können Nutzer verschiedene Modelle nicht nur testen, sondern auch gegeneinander antreten lassen.
Dieses direkte „Wettkampf“-Format fördert die Innovation, gibt praxisnähere Einschätzungen und schafft eine neue Interaktionsmöglichkeit innerhalb der KI-Community. Zusammenfassend lässt sich sagen, dass die Ausführung des MMLU-Benchmarks auf diversen LLM-Endpunkten einen Meilenstein in der Beurteilung von großen Sprachmodellen darstellt. Durch flexible Schnittstellen, schnelle Testverfahren und transparente Ergebnisdarstellung profitieren Entwickler, Unternehmen und Forscher gleichermaßen. Die stetige Verbesserung der Modelle und die offene Vergleichbarkeit tragen maßgeblich zur Etablierung leistungsfähiger und zuverlässiger KI-Systeme bei – ein entscheidender Faktor im Wettbewerbsumfeld und im Fortschritt der Technologie. Wer sich also intensiv mit der Evaluierung von KI-Modellen beschäftigt, findet in der Möglichkeit, MMLU flexibel auf verschiedenen Plattformen laufen zu lassen, ein mächtiges Werkzeug.
Es hilft nicht nur, fundierte Entscheidungen bei der Auswahl zu treffen, sondern ermöglicht auch, ein tieferes Verständnis der jeweiligen Stärken und Baustellen einzelner Sprachmodelle zu gewinnen. Die Zukunft der KI-Benchmarking wird wohl weiterhin von solchen innovativen, flexiblen und anwenderorientierten Ansätzen geprägt sein.