Verteilte Systeme bilden das Rückgrat moderner IT-Infrastrukturen, werden jedoch häufig mit komplexen Herausforderungen konfrontiert. Insbesondere bei der Konsensfindung und Replikation von Daten innerhalb eines Clusters stehen Entwickler vor der schwierigen Aufgabe, Konsistenz, Verfügbarkeit und Netzwerkausfälle in Einklang zu bringen. Klassische Protokolle wie Raft und Paxos dominieren die Diskussion um verteilte Konsensmechanismen, doch sie bringen spezifische Einschränkungen mit sich, die nicht für jeden Use-Case optimal sind. Genau hier setzt das Open-Source-Projekt FlowG an und verfolgt einen alternativen und innovativen Weg, der ohne Raft auskommt und dennoch Anforderungen wie Hochverfügbarkeit und geringe Latenz erfüllt. FlowG ist eine Low-Code-Softwarelösung für Log-Management, die von David Delassus und seinem Team entwickelt wurde.
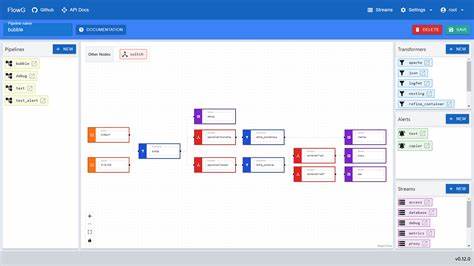
Ursprünglich als eigenständiger Server konzipiert, wurde FlowG vor allem durch den Bedarf getrieben, innerhalb komplexer Infrastrukturen mit mehreren Clustern und zahlreichen Containern sowie Prozessen performant und stabil zu arbeiten. Die Notwendigkeit, Logs zu verarbeiten, kategorisieren, transformieren und in unterschiedlichen Speichern abzulegen sowie auf bestimmte Log-Ereignisse per API reagieren zu können, führte zu der Entwicklung einer besonders flexiblen Pipeline-Lösung. Dabei kam unter anderem die Vector Remap Language von Datadog zum Einsatz, kombiniert mit React Flow für eine intuitive Pipeline-Editor-Oberfläche. Ein Problem, das sich jedoch bald zeigte, war die fehlende Replikation und damit verbundene Single Point of Failure bei der Nutzung von FlowG. Viele Anwender äußerten den Wunsch nach einem verteilten System, das sowohl Fehlertoleranz als auch Hochverfügbarkeit bietet.
Die klassische Variante, auf Raft oder Paxos zu setzen, erschien in diesem Zusammenhang allerdings nicht optimal, da diese Protokolle prinzipbedingt auf starken Konsistenzansprüchen basieren und in Situationen mit Netzwerkpartitionen oder Führungsprobleme zu Ausfällen führen können. Die Entscheidung fiel deshalb auf alternative Methoden. Im Mittelpunkt steht das Verständnis des CAP-Theorems, das besagt, dass verteilte Systeme nicht gleichzeitig Konsistenz, Verfügbarkeit und Partitionstoleranz vollumfänglich bieten können. Systeme, die starke Konsistenz gewährleisten, verzichten oft auf Verfügbarkeit bei Netzwerkproblemen, wohingegen Systeme, die immer verfügbar sind, auf starke Konsistenz verzichten müssen. Raft ist ein prototypisches CP-System, das einen Leader-Knoten wählt und alle Schreibzugriffe über diesen Knoten zwingend kanalisiert.
Während es Vorteile bei der Datenintegrität und Vorhersagbarkeit bietet, führt es zu einer erhöhten Latenz, Performance-Engpässen beim Leader und möglichen Ausfällen, wenn die Leaderwahl scheitert. Paxos steht in einem ähnlichen Kontext, da es ebenfalls auf Mehrheitsentscheidungen und starken Konsistenzgarantien beruht. Die Lösung von FlowG sieht anders aus. Die Entwickler setzen auf ein Gossip-basiertes Protokoll namens SWIM (Scalable Weakly-consistent Infection-style Process Group Membership). Dieses Protokoll basiert auf der Verbreitung von Informationen in einer Art „Infectious“-Stil, wodurch Zustandsinformationen mit geringem Overhead und hoher Skalierbarkeit im Cluster verteilt werden.
SWIM bevorzugt Verfügbarkeit und Partitionstoleranz gegenüber starker Konsistenz und erlaubt damit einen fortschreitenden Zustand, der sich im Laufe der Zeit angleicht – das Prinzip der Eventual Consistency. Die Implementierung von SWIM in FlowG erfolgt mit der Go-Bibliothek memberlist von Hashicorp. Diese ermöglicht die flexible Kommunikation zwischen Knoten über HTTP, was Vorteile in Bezug auf TLS-Handling, Authentifizierung und die Integration in bestehende Infrastrukturen bringt. Somit können auch Reverse Proxies, Client-Zertifikate und andere Sicherheitsmechanismen einfach eingebunden werden. Ein wichtiger Aspekt ist die Erweiterung des Protokolls durch Metadaten, sodass neben dem simplen Namen und Host-Port auch Informationen wie das genutzte Protokoll (HTTP oder HTTPS) und URL-Pfade im Cluster bekannt gemacht werden.
Die Verwaltung der Knoten erfolgt über spezielle Callback-Hooks, mit denen Join- und Leave-Events überwacht werden. Somit entsteht eine in-memory Abbildung des gesamten Clusterzustands, die für die verteilte Verarbeitung genutzt wird. Da SWIM jedoch ein „AP-System“ ist, das auf Eventual Consistency setzt, müssen Konflikte bei Schreiboperationen anders gelöst werden. Hier kommen so genannte Conflict-free Replicated Data Types (CRDTs) ins Spiel, die es erlauben, dass alle Knoten Schreiboperationen lokal zulassen und die Zustände später automatisch konvergieren, ohne dass eine zentrale Schaltstelle benötigt wird. FlowG arbeitet mit einem sogenannten oplog, einer Art Operation Log, in dem timestamped Schreiboperationen gespeichert werden und mit anderen Knoten synchronisiert werden.
Für die Authentifizierungsdatenbank und die Konfigurationsspeicher verwendet FlowG einen Last-Write-Wins-Ansatz, der die letzte operation basierend auf dem Zeitstempel als gültig akzeptiert. Beim Log-Datenbankmodell, das hauptsächlich Append- und Purge-Operationen ausführt, kommt die Natur der Datenstruktur den Eigenschaften von CRDTs entgegen und sorgt von sich aus für Konvergenz. Diese Vorgehensweise erlaubt, dass jede Node im Cluster Schreiboperationen annehmen kann, wodurch ein echtes Hochverfügbarkeitsmodell geschaffen wird. Dennoch sind Herausforderungen zu meistern, etwa die potenzielle Größe des oplogs, die Performance beim Austausch dieser Daten und die Notwendigkeit von Snapshots, um künftig Speicher- und Netzwerklast zu optimieren. FlowG zeigt beispielhaft, dass es möglich ist, verteilte Systeme ohne klassische Leader-basierte Konsensprotokolle zu bauen und dabei eine hohe Verfügbarkeit und gute Performance zu erzielen.
Damit stellt das Projekt insbesondere für Anwendungen mit hohen Anforderungen an Skalierbarkeit und Fehlertoleranz eine interessante Alternative dar. Die Kombination von Gossip-Protokollen und CRDTs ist hierbei ein vielversprechender Ansatz, der in weiteren Teilen der Serie vertieft wird. Die Praxisnähe und das Open-Source-Konzept von FlowG laden ein, den Code auf GitHub mitzuverfolgen, eigene Beiträge zu leisten oder das Design für weitere komplexe Systeme als Inspirationsquelle zu nutzen. Die Entwicklung verläuft Schritt für Schritt, wobei das Feedback der Community maßgeblich zur Optimierung beiträgt. Abschließend bleibt festzuhalten, dass der Verzicht auf Raft bei FlowG kein Kampf gegen Klassiker ist, sondern vielmehr eine gezielte Anpassung der Technologie an spezifische Anforderungen.
Hochverfügbarkeit und Performance stehen in einem Spannungsverhältnis zur strikten Konsistenz, und durch den Einsatz neuer, innovativer Technologien lassen sich diese Zielsetzungen neu definieren. Für Entwickler und Architekten verteilter Systeme eröffnet FlowG neue Perspektiven, wie man Log-Management und Replikation jenseits traditioneller Konsensprotokolle gestalten kann.