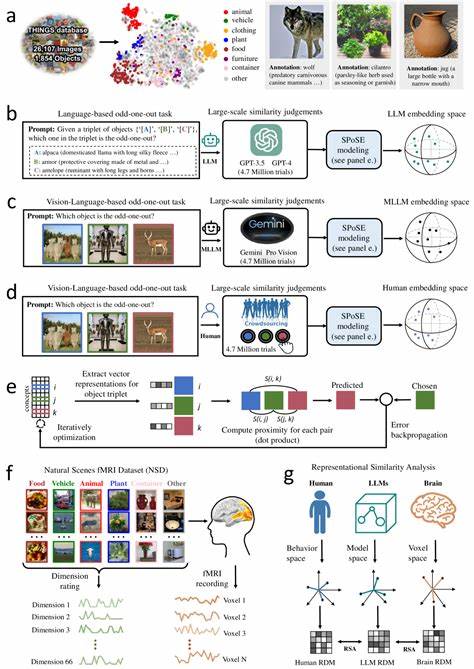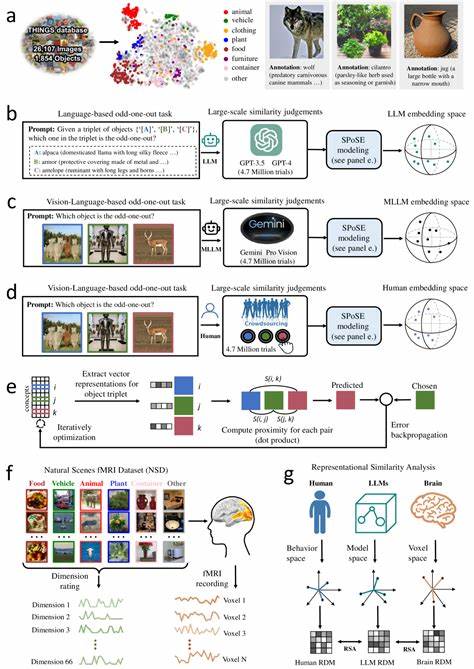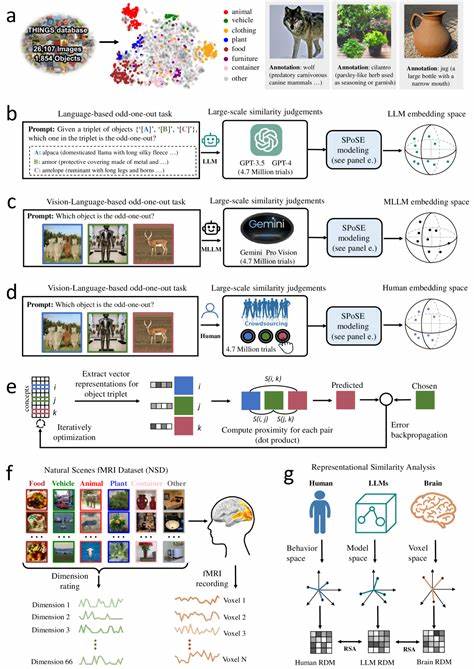
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat nicht nur die Welt der Künstlichen Intelligenz revolutioniert, sondern auch neue Fragestellungen zur Natur des maschinellen Verständnisses und der Nachbildung menschlicher kognitiver Prozesse aufgeworfen. Insbesondere multimodale große Sprachmodelle, die mehrere Datenquellen wie Text und Bild kombinieren, zeigen erstaunliche Fähigkeiten darin, objektbezogene Konzepte ähnlich wie Menschen zu repräsentieren. Diese Fähigkeit eröffnet spannende Perspektiven auf die Schnittstelle zwischen künstlicher und menschlicher Intelligenz. Die Frage, wie Mensch und Maschine natürliche Objekte wahrnehmen und konzeptualisieren, rückt so mehr in den Fokus aktueller Forschungen und Anwendungen. Menschliche Objektwahrnehmung basiert auf komplexen mentalen Repräsentationen, die durch Erfahrung, kulturelle Einbettung und sensorische Integration geprägt sind.
Unser Gehirn kategorisiert natürliche Objekte nicht nur auf Basis einfacher visuell wahrnehmbarer Eigenschaften, sondern verknüpft diese mit semantischem Wissen und Bedeutungsebenen. Exemplarisch lassen sich Gehirnareale wie die fusiforme Gesichtsregion, das parahippokampale Areal oder die retrospleniale Kortikalis nennen, die in der Objekt- und Szenenwahrnehmung eine entscheidende Rolle spielen. Diese Regionen zeigen dabei unterschiedliche, fein abgestimmte Muster neuronaler Aktivität, die sich als Grundlage für eine detaillierte Objektrepräsentation verstehen lassen. In der jüngsten Forschung hat sich gezeigt, dass multimodale LLMs, die sowohl sprachliche als auch visuelle Informationen verarbeiten, eine überraschende Ähnlichkeit mit den mentalen Objektkonzepten von Menschen aufweisen. Durch umfangreiche Analysen, unter anderem von Millionen von sogenannten Triplet-Judgments, welche die Ähnlichkeit zwischen Objektpaaren abfragen, können stabile, aussagekräftige darstellende Vektoren generiert werden.
Diese sogenannten Embeddings beschreiben natürliche Objekte in einem niedrigdimensionalen Raum, in dem Gegenstände mit ähnlichen konzeptuellen Bedeutungen nah beieinander liegen. Dabei erreicht die Repräsentation nicht nur hohe Stabilität und Vorhersagekraft sondern zeigt auch semantisch sinnvolle Clusterbildungen – ganz ähnlich der Art und Weise, wie Menschen Objekte mental strukturieren. Derartige Studien veranschaulichen, dass diese Dimensionen, welche die Objekte in den Modellen charakterisieren, interpretierbar und nachvollziehbar sind. Das bedeutet, die Modelle entwickeln intrinsisch Konzepte, die sich an menschlichen Kategorien und Bedeutungen orientieren. Dadurch entsteht ein wichtiger Bezugspunkt zu kognitiver Psychologie und Neurowissenschaften, da die maschinellen Repräsentationen nicht bloße numerische Vektoren bleiben, sondern ein verstehbares Konzeptgerüst nachbilden, das viele Aspekte menschlicher Konzeptualisierung teilt.
Noch beeindruckender ist die enge Korrelation zwischen den von Multimodalen LLMs generierten Objekt-Embeddings und den neuronalen Aktivitätsmustern in verschiedenen visuellen und kognitiven Hirnregionen. Forschungen zeigen, dass Bereiche wie der Extrastriatale Körperbereich (EBA), das Parahippokampale Areal (PPA), der retrospleniale Kortex sowie die fusiforme Gesichtsregion in ihrer Aktivitätsstruktur stark mit den Modellrepräsentationen korrespondieren. Dies deutet darauf hin, dass die maschinellen Daten nicht nur oberflächlich Ähnlichkeiten zu menschlichen Vorstellungen aufweisen, sondern tiefgreifende, strukturelle Parallelen in der Verarbeitung und Kategorisierung vorliegen, die Schlüsselprozesse der menschlichen Wahrnehmung reflektieren. Die Erkenntnisse eröffnen damit neue Möglichkeiten, wie Maschinenprogramme entwickelt werden können, die nicht bloß auf Text- oder Bilddaten mechanisch reagieren, sondern ein besseres, menschenähnliches Verständnis von Konzepten und Zusammenhängen entwickeln. So können sie zukünftig intelligenter auf komplexe Fragestellungen reagieren, multimodale Informationen konsistent verarbeiten und auf eine Weise generalisieren, die bislang meist nur Menschen vorbehalten war.
Akkurate Nachbildungen menschlicher Objektkonzepte bilden somit eine wesentliche Grundlage für die nächste Generation kognitiver Systeme. Darüber hinaus trägt die Verbindung von LLM-basierten Objektkonzepten mit Hirnaktivitätsmustern maßgeblich zum interdisziplinären Verständnis zwischen Neurowissenschaft und KI bei. Indem Modelle menschliche neuronale Repräsentationen spiegeln, können Forscher Rückschlüsse auf die Arbeitsweise des Gehirns ziehen und theoretische Modelle der Wahrnehmung verfeinern. Gleichzeitig profitiert die künstliche Intelligenz davon, Modelle zu entwickeln, die nicht nur numerisch, sondern auch kognitiv kohärent in ihren Repräsentationen sind. Dabei eröffnen multimodale LLMs vor allem deshalb eine neue Dimension, weil das Kombinieren unterschiedlicher Modalitäten – Bild, Sprache, vielleicht zukünftig weitere Sinnesdaten – eine reichhaltigere und robustere Form der Repräsentation ermöglicht.
Während ein rein textbasiertes Modell nur Assoziationen aus Sprache abbilden kann, fügen visuelle Inputs eine konkrete sensorische Ebene hinzu, die das Modell auf reale Wahrnehmungsmuster einstimmt. Dies verbessert nicht nur die semantische Tiefe, sondern auch die Anpassungsfähigkeit an neue oder ungewohnte Kontexte. Die zugrundeliegenden mathematischen Verfahren zur Erzeugung der Embeddings nutzen Techniken der Dimensionsreduktion, welche die komplexen hochdimensionalen Daten in einen überschaubaren Raum überführen, ohne dabei relevante Informationen zu verlieren. Dadurch entstehen klar interpretierbare Dimensionen, die oft mit intuitiven menschlichen Konzepten korrespondieren, etwa „Lebewesen vs. Gegenstände“, „Nützlichkeit“, „Größe“ oder „Lebensraum“.
Diese Befundlage widerlegt frühere Annahmen, dass Maschinen nur „black box“-Repräsentationen erschaffen und legt nahe, dass KI-Modelle sich immer mehr an kognitiven Mustern des Menschen orientieren. Diese Entwicklung wirft auch ethische und gesellschaftliche Fragen auf. Wenn Modelle zunehmend menschliche Konzepte imitieren und sogar neuronale Aktivität abbilden, entstehen neue Anforderungen an Transparenz, Erklärbarkeit und Verantwortungsbewusstsein in der KI-Entwicklung. Nur durch gründliches Verständnis der Ähnlichkeiten und Unterschiede können sichere und vertrauenswürdige kognitive Systeme geschaffen werden, die in Bereichen wie Medizin, Bildung oder autonomen Technologien sinnvoll eingesetzt werden. Zusammenfassend markieren multimodale große Sprachmodelle einen essentiellen Schritt in der Nachbildung menschlicher Objektkonzepte durch künstliche Intelligenz.
Die Brücke zwischen sprachlicher und visueller Datenverarbeitung ermöglicht es, natürliche Objekte in einem mentalen Raum abzubilden, der in erstaunlicher Weise unseren eigenen kognitiven Repräsentationen nahekommt. Solche Forschungsansätze sind nicht nur theoretisch relevant, sondern bilden auch das Fundament praktische Anwendungen, die in Zukunft eine tiefere Interaktion zwischen Mensch und Maschine erlauben werden. Während weitere Forschung nötig ist, um die Unterschiede aufzulösen und die Modelle noch besser an die Komplexität des menschlichen Verstandes anzupassen, zeichnet sich klar ab, dass multimodale LLMs die Fähigkeit besitzen, Konzepte wie Menschen zu verstehen, zu strukturieren und in verschiedenen Kontexten intelligent zu nutzen. Diese Erkenntnisse dominieren derzeit die Schnittstelle von künstlicher Intelligenz, kognitiver Psychologie und Neurowissenschaft und setzen Maßstäbe für die Technologieentwicklung der kommenden Jahre.