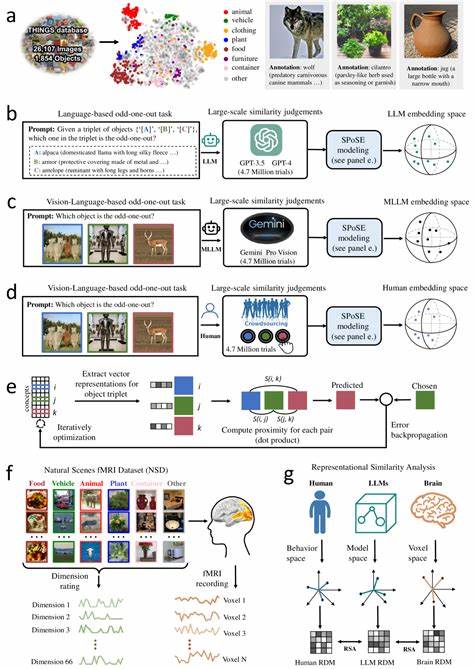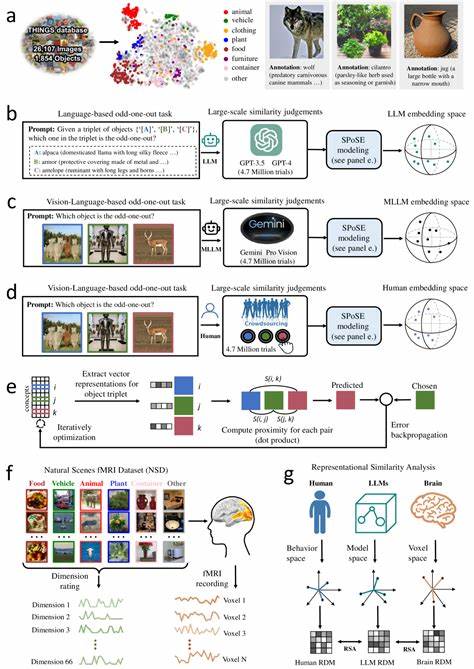
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die Art und Weise, wie wir künstliche Intelligenz (KI) verstehen und einsetzen, grundlegend verändert. Noch faszinierender wird es, wenn diese Modelle multimodal trainiert werden – das heißt, sie verarbeiten nicht nur sprachliche Daten, sondern auch visuelle Informationen. In jüngster Zeit zeigt sich, dass multimodale große Sprachmodelle verblüffend menschenähnliche Objektkonzeptrepräsentationen entwickeln. Diese Erkenntnisse eröffnen neue Perspektiven für die Schnittstelle zwischen KI, Kognitionswissenschaft und Neurowissenschaften und sind ein Meilenstein auf dem Weg zu verständnisvolleren und intuitiveren künstlichen Systemen.Der Ursprung der Forschung liegt in der Frage, wie Menschen Objekte wahrnehmen, kategorisieren und mental repräsentieren.
Schon lange untersuchen Wissenschaftler, wie das menschliche Gehirn natürliche Objekte verarbeitet und abstrahiert, um Bedeutung zu schaffen. Dieses komplexe mentale Abbild wird oft als multidimensional und semantisch reich beschrieben. Die Herausforderung bestand darin, ob und wie künstliche neuronale Netzwerke, insbesondere jene, die auf multimodalen Trainingsdatensätzen basieren, vergleichbare, menschenähnliche Konzepte erlernen können.Die aktuelle Forschung, angestoßen von einer umfassenden Studie mit 1.854 natürlichen Objekten, zeigt, dass multimodale LLMs nicht nur linguistische, sondern auch visuelle Daten in einer Weise integrieren, die zu stabilen, vorhersagbaren und interpretierbaren Objektähnlichkeitsräumen führt.
Durch das Sammeln von Millionen von Triplet-Urteilen – einer Methode, bei der jeweils drei Objekte verglichen und das unähnlichste identifiziert wird – konnten Forscher ein niedrigdimensionales Einbettungsmodell mit 66 Dimensionen entwickeln. Diese Dimensionen reproduzieren erstaunlich gut die Struktur der menschlichen mentalen Repräsentationen und spiegeln bedeutende semantische Cluster wider.Ein zentraler Befund ist die Interpretierbarkeit der zugrundeliegenden Dimensionen. Anders als bei vielen „Black-Box“-Modellen lassen sich bei multimodalen LLMs diese Dimensionen oft mit intuitiven Konzepten verbinden. Beispiele hierfür sind Kategorien wie „Lebensform“, „Materialtyp“, „Nutzungskontext“ oder „Größe“.
Diese Faktoren entsprechen klassischen kognitiven Theorien über Objektwahrnehmung und -klassifikation und bestätigen, dass die Modelle nicht nur oberflächliche Muster lernen, sondern tiefe konzeptuelle Struktur entwickeln.Ein weiterer wichtiger Aspekt der Studie ist die Verbindung zwischen den Modellrepräsentationen und biologischen Gegenstücken im menschlichen Gehirn. Die 66-dimensionalen Einbettungen zeigen eine starke Übereinstimmung mit neuronalen Aktivitätsmustern in bekannten visuell-kognitiven Hirnregionen, darunter der extrastriate body area, der parahippocampalen Place Area, dem retrosplenialen Kortex und der fusiformen Gesichtsregion. Diese Areale sind für die Verarbeitung von Körpermaßen, räumlicher Orientierung, Gedächtnis und Gesichtswahrnehmung maßgeblich. Die Übereinstimmung untermauert, dass multimodale LLMs nicht nur oberflächliche Ähnlichkeiten zu menschlichen Konzepten zeigen, sondern auch funktionelle Parallelen in der Verarbeitung aufweisen.
Die Integration multimodaler Daten ist hierbei entscheidend. Während klassische LLMs rein auf sprachliche Eingaben angewiesen sind und somit eine abstrahierte, teils distanzierte Weltansicht entwickeln, ermöglichen visuelle Daten eine stärkere Verankerung in reeller Wahrnehmung. Dies führt zu kompakteren und kognitiv konsistenteren Darstellungen, die näher an den menschlichen mentalen Prozessen liegen. Multimodalität ist somit ein Schlüssel, um die Brücke von reiner Textverarbeitung hin zu echter Verständnisfähigkeit zu schlagen.Die Erkenntnisse haben weitreichende Implikationen für die Gestaltung der nächsten Generation intelligenter Systeme.
Wenn Maschinen natürliche Objekte ähnlich wie Menschen beurteilen und kategorisieren können, eröffnet dies neue Anwendungsfelder in Robotik, automatisierter Bildanalyse, personalisierter Assistenz und adaptiver Mensch-Maschine-Interaktion. Systeme könnten dadurch nicht nur besser auf menschliche Intuition reagieren, sondern auch komplexe, abstrakte Aufgaben mit höherer Effizienz und Sicherheit bewältigen.Gleichzeitig bieten die Ergebnisse wertvolle Einblicke für die kognitive Neurowissenschaft. Die Möglichkeit, Computermodelle mit menschlichen Daten – beispielsweise Verhaltensexperimenten oder fMRT-Aufzeichnungen – zu vergleichen, gestattet eine präzisere Erforschung, welche Datenstrukturen und welche Lernmechanismen unserem Denken und Wahrnehmen zugrunde liegen. Das Wechselspiel zwischen künstlicher Intelligenz und Hirnforschung verspricht somit eine beidseitige Weiterentwicklung beider Disziplinen.
Selbstverständlich bleiben auch Fragen offen. Die Modelle unterscheiden sich noch in vielen Details von menschlicher Kognition. So sind menschliche Konzepte meist kontextabhängig, emotional eingefärbt und flexibel modifizierbar, während LLM-Repräsentationen häufig starrer und datengetriebener sind. Zudem ist die aktuelle Forschung vorwiegend auf visuelle und sprachliche Modalitäten konzentriert, während Menschen ihre Konzepte auch haptisch, olfaktorisch und durch soziale Interaktion formen.Nichtsdestotrotz sind multimodale große Sprachmodelle ein bedeutender Schritt in Richtung artificial general intelligence (AGI), die über die bloße Verarbeitung von Daten hinaus eine echte, menschenähnliche Weltinterpretation entwickelt.