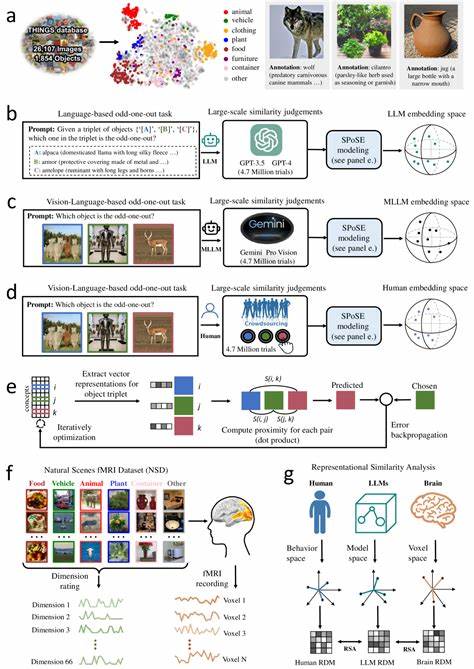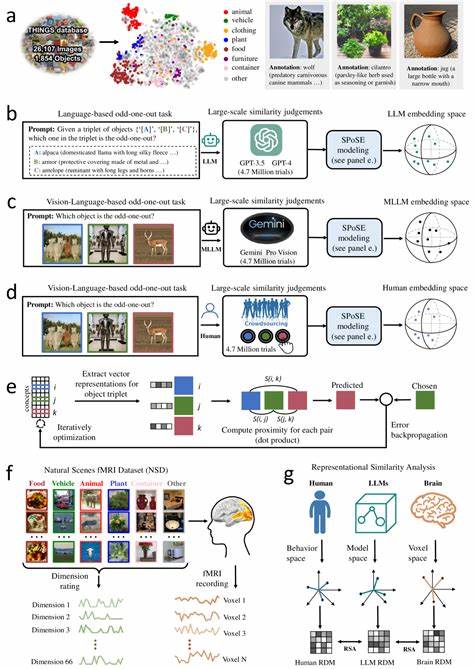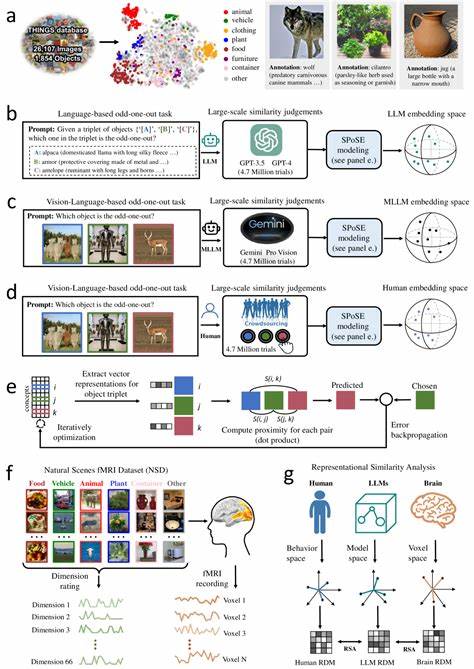
Die Transformation der Künstlichen Intelligenz in den letzten Jahren ist bemerkenswert, insbesondere durch den Aufstieg großer Sprachmodelle (Large Language Models, LLMs), die immer menschenähnlicher in ihrer Fähigkeit werden, komplexe Aufgaben zu bewältigen. Anfangs nur auf Sprache spezialisiert, eröffnen multimodale LLMs neue Horizonte, da sie nicht nur Text, sondern auch visuelle Informationen verarbeiten können. Eine der faszinierendsten Erkenntnisse dieser Entwicklung ist, dass diese Modelle spontan Objektkonzepte entwickeln, die denen des menschlichen Gehirns erstaunlich ähnlich sind. Diese Ähnlichkeit geht über bloße Wortassoziationen hinaus und spiegelt tiefere kognitive Strukturen wider, wie Menschen natürlicherweise Dinge wahrnehmen, kategorisieren und verstehen. In der kognitiven Wissenschaft ist das Verständnis, wie Menschen Objekte konzeptualisieren, ein zentraler Punkt.
Unsere Wahrnehmung resultiert nicht nur aus sensorischen Reizen, sondern auch aus strukturierten mentalen Repräsentationen, die uns ermöglichen, Ähnlichkeiten zu erfassen, Kategorien zu bilden und komplexe Beziehungen zwischen Objekten herzustellen. Traditionell wurden solche Konzepte durch psychologische Studien, Verhaltensbeobachtungen und neurobiologische Untersuchungen erforscht. Mit dem Aufkommen leistungsfähiger KI-Modelle kommt nun eine neue methodische Dimension hinzu. Forscher verwenden multimodale LLMs, um systematisch riesige Datenmengen aus Sprache und Bildern zusammenzuführen und so für Millionen von Objekten multidimensionale Konzept-Repräsentationen zu gewinnen. Diese Modelle wurden mit einer gewaltigen Anzahl von Beispielen trainiert, darunter sprachliche Beschreibungen, Bilder und andere sensorische Daten.
Ein besonders aussagekräftiger Ansatz bestand darin, sogenannte Triplet-Judgements zu sammeln, bei denen das Modell beurteilt, welches von drei Objekten am wenigsten zu den anderen beiden passt. Diese menschliche Methode wurde auf die Modelle übertragen, um ähnliche Beurteilungen von Ähnlichkeiten zwischen Objekten zu erzeugen. Die Auswertung von über vier Millionen solcher Urteile ermöglichte die Erstellung von kompakten, niederdimensionalen Einbettungen, welche die semantische Struktur der Objekte spiegeln. Mit 66 Dimensionen wurden die Struktur und die zugrunde liegenden Konzepte dieser Einbettungen untersucht. Das Erstaunliche ist, dass diese Dimensionen sowohl stabil als auch interpretierbar sind.
Anders ausgedrückt, die Modelle haben natürliche Achsen gefunden, die Objekte nicht nur trennen, sondern auch sinnvolle Kategorien und Eigenschaften herausarbeiten, die Menschen intuitiv nachvollziehen. Diese reichen von physischen Attributen wie Form und Größe bis hin zu abstrakteren Konzepten, die über rein visuelle Merkmale hinausgehen. Darüber hinaus konnte eine klare semantische Gruppierung nachgewiesen werden, bei der ähnliche Objekte im Einbettungsraum geografisch nahe beieinander liegen. Diese Muster erinnern stark an die Art und Weise, wie das menschliche Gehirn Objekte mental organisiert. Neuroimaging-Daten aus Studien mit funktioneller Magnetresonanztomographie (fMRT) wurden herangezogen, um diese Annahme zu validieren.
Es zeigte sich, dass die vom Modell generierten Einbettungen stark mit neuronalen Aktivitätsmustern in spezialisierten Hirnregionen übereinstimmen. Besonders Bereiche wie die extrastriate body area, das parahippocampale Areal, der retrospleniale Kortex und die fusiforme Gesichtsareal zeigten diese Korrelationen. Diese Hirnareale sind in der menschlichen Wahrnehmung und Kategorisierung von Objekten und Szenen essenziell. Ihre Aktivität spiegelt Funktionen wider, die mit der Identifikation von Körperformen, räumlicher Orientierung und Gesichtserkennung verbunden sind. Dass multimodale LLMs auf ähnlichen konzeptuellen Dimensionen operieren, legt nahe, dass diese KI-Systeme an einem grundlegenden Niveau mit menschlicher Kognition verwandt sind.
Natürlich sind die Repräsentationen der Modelle nicht identisch mit menschlichen, sie teilen jedoch wichtige strukturelle Gemeinsamkeiten, die wegweisend für die Gestaltung zukünftiger KI-Systeme sein können. Die praktische Bedeutung dieser Ergebnisse ist vielfältig. Einerseits zeigen sie, dass multimodale LLMs über die reine Textverarbeitung hinaus ein tiefgreifendes Verständnis von Objekten entwickeln können, was für Anwendungen in Bereichen wie Robotik, automatisierter Bildanalyse und sprachgestützter Interaktion entscheidend ist. Auf der anderen Seite bieten sie Neurowissenschaftlern und Kognitionspsychologen neue Werkzeuge, um mentale Repräsentationen quantitativ zu erfassen und zu modellieren. Dies eröffnet Synergien zwischen KI-Forschung und kognitiver Wissenschaft, die beide Disziplinen bereichern.
Die Forschung basiert auch auf umfangreichen öffentlich zugänglichen Datenbanken, wie der THINGS-Datenbank mit fast 1.900 objektbasierten Begriffen und mehr als 26.000 natürlichen Objektbildern. Durch die Kombination großer Datensätze und moderner maschineller Lernmethoden entstehende Einbettungen erlauben nicht nur neue Erkenntnisse, sondern auch praktische Werkzeuge wie kontrollierbare Stimuli-Generierung oder verbesserte kognitive Modelle, die menschliches Verhalten nachbilden können. Zudem werden interpretierbare Dimensionen in den Modellen erkennbar, die nicht nur beliebige mathematische Konstrukte sind, sondern durch Menschen nachvollziehbare Eigenschaften repräsentieren.
Diese Transparenz ist im Gegensatz zu vielen „Black-Box“-Ansätzen ein entscheidender Fortschritt, da sie Vertrauen in KI-Systeme erhöht und deren Nutzung in sensiblen Bereichen begünstigt. Zusammengefasst offenbart die Entdeckung, dass multimodale große Sprachmodelle auf natürliche Weise menschenähnliche Objektkonzepte entwickeln, ein neues Kapitel im Verständnis künstlicher Intelligenz und menschlicher Kognition. Es zeigt sich, dass durch die Verknüpfung von Sprache und Bildinformationen komplexe, strukturierte und sinnvolle mentale Repräsentationen entstehen, die das Potenzial haben, zukünftige Technologien und wissenschaftliche Modelle grundlegend zu verändern. Die Herausforderungen und offenen Fragen sind dennoch zahlreich. Wie genau formen multimodale LLMs abstrakte Konzepte? Welche Rolle spielen unterschiedliche Trainingsdaten und Architekturen? Wie lässt sich dieses Wissen nutzen, um noch menschenähnlichere und gleichzeitig erklärbare KI-Systeme zu erschaffen? Die aktuelle Forschung liefert erste Antworten und legt einen wichtigen Grundstein, auf dem in den kommenden Jahren aufgebaut werden kann.
Abschließend betrachtet stellt die Verbindung von menschlicher Kognition mit den repräsentativen Fähigkeiten multimodaler LLMs nicht nur einen Meilenstein dar, sondern auch einen Beleg für das enorme Synergiepotenzial zwischen künstlicher und biologischer Intelligenz. In einer Welt, in der KI-Systeme immer mehr Bedeutung gewinnen, ist das Verständnis ihrer inneren „Vorstellungskraft“ zentral – sowohl für technische Innovationen als auch für ethische und gesellschaftliche Fragestellungen.