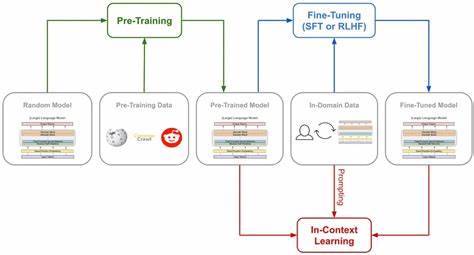
In der Welt der Künstlichen Intelligenz (KI) sind die stetige Verbesserung und Anpassung von Modellen entscheidend für den Erfolg in verschiedensten Einsatzgebieten. Ein prominentes Beispiel hierfür ist Qwen3, ein fortschrittliches KI-Sprachmodell, das durch den Einsatz sogenannter Supervised Fine-Tuning-Methoden mithilfe von TRL (Transformers Reinforcement Learning) optimiert wird. Diese Kombination aus überwachtem Lernen und verstärkendem Lernen eröffnet neue Möglichkeiten, um die Leistungsfähigkeit von Modellen gezielt zu steigern und ihren Nutzen für praktische Anwendungen zu erhöhen. Qwen3 stellt eine neuartige Generation von Sprachmodellen dar, deren Entwicklung auf der Idee basiert, künstliche Intelligenz nicht nur generisch, sondern auch kontextspezifisch anzupassen. Der Kern dieser Anpassung liegt im Fine-Tuning, einem Prozess, bei dem ein bereits vortrainiertes Modell mit spezifischen Daten weitertrainiert wird, um seine Fähigkeiten auf bestimmte Aufgaben oder Domänen zu verfeinern.
Das supervised Fine-Tuning mit TRL bietet hierbei eine besonders wirkungsvolle Möglichkeit, indem es nicht nur traditionelle überwachte Lernansätze einsetzt, sondern auch verstärkendes Lernen integriert. Das Prinzip des Supervised Fine-Tunings besteht darin, ein Modell auf Basis eines vorgegebenen Datensatzes zu trainieren, der mit expliziten Kennzeichnungen oder Zielwerten versehen ist. Diese Kennzeichnungen helfen dem Modell zu verstehen, welche Antworten oder Verhaltensweisen in bestimmten Situationen erwartet werden. Für Qwen3 bedeutet dies, dass das Modell nach dem initialen Vortraining noch präziser auf konkrete Anwendungsfälle etwa in der Textgenerierung, Übersetzung oder im Dialogsystem angepasst werden kann. TRL ergänzt diesen Prozess durch die Anwendung von Methoden des Verstärkungslernens, wobei ein Ziel- oder Belohnungssystem eingeführt wird, das das Modell für erwünschte Verhaltensweisen belohnt und für unerwünschte bestraft.
Das erlaubt eine Art dynamisches Lernen, das über das starre Trainingsszenario des überwachten Lernens hinausgeht. Die Kombination von supervisiertem Lernen mit TRL schafft also eine Brücke zwischen dem Lernen anhand vorgegebener Beispiele und der Fähigkeit, auf Basis von Rückmeldungen eigenständig besser zu werden. Ein wesentlicher Vorteil des Einsatzes von TRL beim Fine-Tuning von Qwen3 ist die Fähigkeit, unerwünschte oder toxische Ausgaben des Modells zu minimieren. In der KI-Kommunikation besteht oft die Herausforderung, dass Modelle unangemessene, voreingenommene oder fehlerhafte Antworten liefern können. Durch ein Belohnungssystem, das erwünschtes Verhalten hervorhebt, kann Qwen3 lernen, derartige Ausgaben zu vermeiden und stattdessen qualitativ hochwertigere, relevantere und ethisch vertretbare Antworten zu produzieren.
Darüber hinaus fördert TRL die Flexibilität des Modells, indem es eine unmittelbare Anpassung an Nutzerfeedback ermöglicht. Anstatt ausschließlich auf statische Trainingsdatensätze angewiesen zu sein, kann Qwen3 durch Reinforcement Learning auf neue Informationen und veränderte Anforderungen reagieren. Dies stellt einen bedeutenden Fortschritt dar, der KI-Anwendungen agiler macht und sie besser in der Lage versetzt, auf komplexe und sich entwickelnde Nutzerbedürfnisse einzugehen. Nicht zuletzt wirkt sich die Kombination aus supervised Fine-Tuning und TRL positiv auf die Effizienz des Trainingsprozesses aus. Durch gezieltes Feedback wird die Lernkurve des Modells beschleunigt, sodass weniger Trainingsdaten und Rechenressourcen benötigt werden, um gewünschte Leistungssteigerungen zu erzielen.
In der Praxis bedeutet dies niedrigere Kosten und schnellere Entwicklungszyklen, was besonders für Unternehmen und Forschungseinrichtungen von großem Interesse ist. Die Einsatzbereiche für Qwen3, das mittels Supervised Fine-Tuning und TRL optimiert wurde, sind vielfältig und reichen von verbesserten Sprachassistenten über präzisere maschinelle Übersetzung bis hin zu intelligenten Chatbots und automatisierten Textgenerierungssystemen. In allen diesen Szenarien spielt die Qualität und Anpassungsfähigkeit des Modells eine zentrale Rolle, um Nutzererlebnisse zu verbessern und Geschäftsprozesse effizienter zu gestalten. Es ist wichtig zu betonen, dass trotz der Vorteile solcher innovativen Trainingsmethoden auch Herausforderungen bleiben. Die Implementierung von TRL erfordert ein sorgfältiges Design des Belohnungsmechanismus, um sicherzustellen, dass das Modell keine unerwünschten Verhaltensweisen lernt oder unbeabsichtigte Verzerrungen verstärkt.
Zudem sind hohe Rechenkapazitäten für das Training erforderlich, die insbesondere bei sehr großen Modellen wie Qwen3 anspruchsvoll sind. Trotz dieser Herausforderungen zeigt die Entwicklung rund um Qwen3 und die Nutzung von Supervised Fine-Tuning mit TRL den Weg in eine neue Ära der KI-Optimierung auf. Die Kombination aus kontrolliertem Lernen und adaptiven Rückmeldemechanismen fördert nicht nur die technische Exzellenz der Modelle, sondern bringt die KI auch näher an die Bedürfnisse und Erwartungen der Nutzer. Im zukünftigen Kontext wird erwartet, dass solche Methoden eine noch wichtigere Rolle spielen, um KI-Systeme verantwortungsvoll und effizient zu gestalten. Mit den stetig wachsenden Datenmengen und immer komplexeren Anwendungen sind adaptive und belohnungsorientierte Trainingstechniken unverzichtbar, um Modelle wie Qwen3 nachhaltig leistungsfähig und zuverlässig zu halten.
Zusammenfassend bietet das Supervised Fine-Tuning mit TRL bei Qwen3 eine innovative und wirkungsvolle Methode, um die Leistungsfähigkeit von KI-Sprachmodellen fundamental zu verbessern. Der Prozess verbindet die Stärken des überwachten Lernens mit den dynamischen Anpassungsmöglichkeiten des Verstärkungslernens und schafft so robuste, flexible und ethisch ausgerichtete KI-Lösungen. Für Unternehmen, Entwickler und Anwender eröffnet sich somit ein breites Spektrum an Potenzialen, die KI der nächsten Generation effektiv und zielgerichtet einzusetzen.