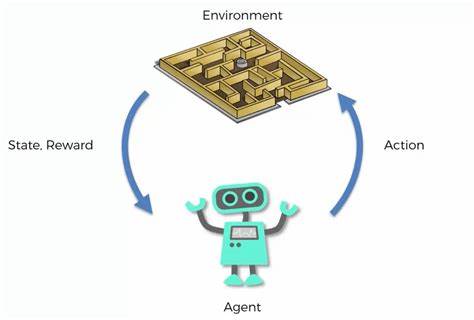
Outcome-Based Reinforcement Learning (OBRL) steht an der Spitze der modernen Forschungsrichtungen im Bereich der Künstlichen Intelligenz, insbesondere beim maschinellen Lernen und bei Vorhersagesystemen. Während klassische Verstärkendes Lernen-Modelle meist direkte, sofortige Belohnungen benötigen, um zu lernen und Entscheidungen anzupassen, zeichnet sich das Outcome-Based Reinforcement Learning dadurch aus, auch mit späten, binären und störanfälligen Rückmeldungen effektiv zu arbeiten. Diese Fähigkeit verändert die Art und Weise, wie Maschinen schon heute in der Lage sind, die Zukunft vorherzusagen. Die Bedeutung von Outcome-Based Reinforcement Learning wird immer offensichtlicher, wenn es darum geht, realweltliche, komplexe und oft unstrukturierte Daten effektiv zu interpretieren und daraus verwertbare Prognosen zu generieren. Die Herausforderung im Bereich der Vorhersage liegt darin, mit unsicheren, verzögerten und teilweise verrauschten Informationen umgehen zu können.
Traditionelle Reinforcement-Learning-Methoden geraten hier schnell an ihre Grenzen. Outcome-Based Reinforcement Learning adressiert genau diese Problematik, indem es auf langfristige Ergebnisse fokussiert, anstatt unmittelbare Belohnungen zu erwarten. Ein beeindruckendes Beispiel für den Fortschritt in dieser Disziplin zeigt sich in der Anwendung von Outcome-Based Reinforcement Learning auf große Sprachmodelle mit Milliarden von Parametern. In einer kürzlich veröffentlichten Studie wurde ein 14-Milliarden-Parameter-Modell erfolgreich für Vorhersageaufgaben eingesetzt, bei denen nur binäre und zeitverzögerte Rückmeldungen vorlagen. Dabei wurden fortschrittliche Algorithmen, wie Group-Relative Policy Optimisation (GRPO) und ReMax, speziell für die Herausforderungen des Prognosebereichs weiterentwickelt.
Diese Adaptionen wirkten sich nicht nur positiv auf die Genauigkeit, sondern auch auf die Kalibrierung der Vorhersagen aus – ein meist unterschätzter Aspekt bei Prognosemodellen. Eine bessere Kalibrierung bedeutet, dass die Unsicherheiten in den Vorhersagen realistischer abgebildet werden. Das wiederum ist essenziell für Anwendungen, bei denen Entscheidungen auf der Grundlage von Wahrscheinlichkeiten getroffen werden müssen, wie beispielsweise im Finanz- oder Gesundheitswesen. Zudem wurden im Training innovative Methoden eingesetzt, unter anderem die Verwendung von etwa 100.000 synthetischen, zeitlich zusammenhängenden Fragen, um das Modell zu robusteren und stichhaltigeren Prognosen zu befähigen.
Neben der Leistungssteigerung wurde auch sichergestellt, dass das Modell qualitativ hochwertige Antworten generiert, indem sogenannte Guard-Rails eingeführt wurden, die unverständliche, nicht-englische oder sachlich unkorrekte Erklärungen verhindern. Ein solcher Qualitätsfilter ist im Einsatz von KI im realen Umfeld von entscheidender Bedeutung, da unzuverlässige oder falsche Informationen schwerwiegende Konsequenzen nach sich ziehen können. Die Effizienz dieses Verfahrens wurde zusätzlich durch den Einsatz von Ensembling-Methoden optimiert – mehrere Modelle wurden kombiniert, um die Gesamtgenauigkeit und Stabilität der Vorhersagen weiter zu erhöhen. Dadurch konnten mit dem 14-Milliarden-Parameter-Modell Vorhersagen erzeugt werden, die mit den besten verfügbaren Benchmarks konkurrieren oder diese sogar in bestimmten Metriken übertreffen. Ein besonderer Vorteil des Outcome-Based Reinforcement Learning zeigt sich bei der Anwendung in hypothetischen Vorhersagemärkten.
Dank der verbesserten Kalibrierung konnten einfache Handelsstrategien angewandt werden, die zu höheren hypothetischen Gewinnen führten als herkömmliche Modelle. Dies zeigt eindrucksvoll, dass Outcome-Based Reinforcement Learning nicht nur theoretisch vielversprechend ist, sondern auch praktische wirtschaftliche Relevanz besitzt. Neben den finanziellen Aspekten bietet diese Technologie auch Perspektiven für zahlreiche andere Bereiche. In der Meteorologie können präzisere, gut kalibrierte Vorhersagen helfen, extreme Wetterereignisse besser einzuschätzen und zu reagieren. In der Politik kann sie politische Entwicklungen oder Wählerverhalten zuverlässiger prognostizieren, was entscheidend für Kampagnenstrategien ist.
Auch im Gesundheitswesen können Outcome-Based Reinforcement Learning Modelle dazu beitragen, Krankheitsverläufe oder Behandlungserfolge besser vorherzusagen und damit personalisierte Therapien zu verbessern. Trotz der beeindruckenden Fortschritte sind noch Herausforderungen zu bewältigen. Die Qualität der synthetischen Trainingsdaten muss weiter verbessert werden, um eine noch realistischere Nachbildung komplexer Situationen zu gewährleisten. Ebenso bleiben ethische Fragen im Umgang mit Prognosemodellen und deren Einfluss auf gesellschaftliche Entscheidungen relevant. Es ist ebenso notwendig, die Skalierbarkeit auf noch größere Modelle zu testen, um die Vorhersagegenauigkeit und Anwendungsbreite weiter zu steigern.
Outcome-Based Reinforcement Learning stellt einen bedeutenden Schritt in Richtung intelligenter und autonomer Systeme dar, die nicht nur sofortige Reaktionen, sondern vor allem fundierte Zukunftsszenarien liefern können. Durch die Kombination von tiefgreifendem maschinellen Lernen, robusten Trainingsmethoden und innovativen Algorithmen werden präzise und vertrauenswürdige Vorhersagen möglich, die vielfältige Industrien und Anwendungsbereiche revolutionieren können. In einer Welt, in der Unsicherheit eine konstante Begleiterin ist, eröffnen diese Technologien neue Wege, um Risiken besser einzuschätzen und informierte Entscheidungen zu treffen. Zukunftsträchtige Ansätze wie Outcome-Based Reinforcement Learning sind damit nicht nur technologische Durchbrüche, sondern auch wichtige Bausteine für eine nachhaltigere und effizientere Gesellschaft.