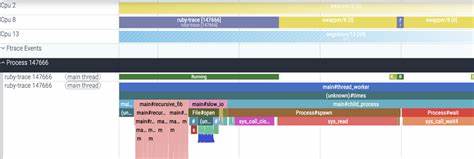
Das Monitoring und die Performance-Analyse von Anwendungen sind für moderne Softwareentwicklung wichtiger denn je. Gerade bei komplexen Systemen, die auf der Programmiersprache Ruby basieren, ist es entscheidend, präzise Daten zu sammeln, um die Performance nicht nur insgesamt zu verbessern, sondern auch selten auftretende Ausreißer schnell zu identifizieren. Hier setzt Huglo an – ein Hyper-Ultra-Giga Low-Overhead Tracing Profiler, der speziell für Ruby entwickelt wurde und es erlaubt, umfangreiche Tracedaten mit minimalem Einfluss auf die Laufzeit zu erfassen. Die Besonderheit von Huglo liegt in seiner Fähigkeit, vier verschiedene Ereignisströme gleichzeitig zu erfassen: Ruby-Funktionsaufrufe, Systemaufrufe, Thread-Zustandsänderungen sowie Garbage-Collection-Aktivitäten. Während herkömmliche Profiler in der Regel nur einen oder zwei dieser Aspekte abdecken und dabei oft mit erheblicher Performance-Einbuße einhergehen, bietet Huglo eine umfassende Sichtweise mit weniger als 30 Nanosekunden Overhead pro Ruby-Funktionsaufruf.
Diese geringe Latenz macht den Einsatz von Huglo auch in produktiven, großskaligen Anwendungen möglich, ohne das System merklich zu bremsen. Warum ist das relevant? Die meisten Performance-Analysetools arbeiten mit Sampling-Methoden, das heißt, sie erfassen periodisch zufällige Momentaufnahmen der Systemaktivität. Diese Herangehensweise ist sinnvoll, um durchschnittliche Engpässe zu identifizieren, stößt aber insbesondere bei der Problemanalyse von Ausreißern an ihre Grenzen. Solche Ausreißer, etwa sogenannte Tail-Latency-Ereignisse, können dramatische Auswirkungen auf die Benutzererfahrung haben, da sie weit über den Durchschnittswerten liegen. Die meisten Sampling-Profiler sehen diese hohen Latenzen nicht oder verkennen deren Ursache.
Huglo hingegen bietet durch die lückenlose Aufzeichnung von Ereignissen einen genauen Einblick in die Abläufe, die hinter diesen Ausreißern stecken. Zum Beispiel kann man mit Huglo einzelne API-Aufrufe tracken und dabei erkennen, welche Funktionen tatsächlich die Latenzspitzen verursachen. Ein bekanntes Szenario zeigt, dass bei einer API-Funktion namens api_handler der Großteil der Gesamtzeit in einer Funktion a verbracht wird, wenn man sich den Durchschnitt anschaut. Beim gezielten Tracing einzelner besonders langer Aufrufe stellt sich jedoch heraus, dass die Funktion b für die hohen Latenzwerte verantwortlich ist – obwohl sie nur in 0,1 Prozent der Fälle aufgerufen wird und wesentlich länger läuft. Das Optimieren von a hätte also wenig Effekt auf die Latenzspitzen.
Neben der präzisen Messung von Funktionslaufzeiten erfasst Huglo auch Thread-Zustandsänderungen. Dieser Aspekt wird oft unterschätzt, denn die Anwesenheit eines Stacktraces bedeutet nicht zwangsläufig, dass der Code gerade aktiv auf der CPU ausgeführt wird. Ein Thread kann in einem Runnable-Zustand verharren oder sogar schlafen und erst später auf der CPU laufen. Durch die zusätzliche Information über Thread-Zustandsübergänge lässt sich die tatsächliche Auslastung der CPU und die Scheduling-Performance besser verstehen. Vor allem bei überlasteten Systemen oder solchen mit hoher Thread-Konkurrenz ist dies ein wertvolles Feature, um zu erkennen, wann die Ausführung vom Betriebssystem verzögert wird.
Ein weiterer Vorteil von Huglo ist die integrierte Überwachung der Garbage Collection. Ruby-Anwendungen sind häufig auf Garbage Collector angewiesen, um Speicher aufzuräumen, was jedoch zu unerwarteten Performance-Einbrüchen führen kann. Huglo verfolgt aktiv diese Events und stellt sie im Kontext der anderen Tracedaten dar, wodurch Entwickler besser nachvollziehen können, wie Speicherbereinigung und Anwendungsperformance zusammenhängen. Die geringen Overhead-Werte von Huglo wurden unter realistischen Bedingungen gemessen. In einem Benchmark mit 200 Läufen auf einem i5-13500 Prozessor unter Ubuntu 24 zeigte Huglo nur 23 Nanosekunden pro Funktionsaufruf, im Vergleich zu über 500 Nanosekunden bei einem weitverbreiteten Ruby-Profiler namens ruby-prof.
Dieses Ergebnis unterstreicht, dass es möglich ist, sehr detailliertes und vielseitiges Tracing anzubieten, ohne dass die Produktionsumgebung darunter leidet. Huglo hat derzeit noch keinen Open-Source-Status, da es sich um ein Proof-of-Concept handelt. Die Entwicklung ist jedoch vielversprechend und mit entsprechendem Interesse von Seiten der Ruby-Community könnte eine öffentliche Version bald verfügbar sein. Die Vision dahinter ist klar: Profiler-Tools sollen nicht mehr nur Werkzeuge für die Entwicklungsphase sein, sondern kontinuierlich und ohne spürbare Beeinträchtigung in produktiven Systemen mitlaufen. Nur so können Entwickler die komplexen und oftmals schwer reproduzierbaren Performance-Probleme von heute effizient analysieren und beheben.
Die zeitliche Gliederung von Huglos Tracing-Daten ist ein weiterer Vorteil gegenüber rein samplingbasierten Ansätzen. Während Sampling lediglich ungefähre Aufteilungen der Laufzeit vermittelt, speichert Huglo die Ereignisse in der tatsächlich abgelaufenen Reihenfolge und mit genauen Zeitstempeln. Diese Chronologie erleichtert Fehleranalyse und Optimierung, weil Entwickler den exakten Ablauf nachvollziehen können, in dem Funktionen aufgerufen wurden oder Threads pausierten. In der Praxis kann Huglo Entwicklern helfen, typische Herausforderungen von Ruby-Anwendungen besser anzugehen. Wenn Sie beispielsweise häufig mit sporadisch auftretenden Performance-Einbrüchen zu kämpfen haben, lässt sich mit Huglo aufdecken, ob der Grund bei selten aufgerufenen, aber ressourcenintensiven Funktionen, beim Scheduling durch das Betriebssystem oder bei Garbage Collection liegt.
Die Kombination aus Funktionstracing, Systemaufruf-Analyse, Thread-Status-Verfolgung und Garbage-Collection-Monitoring macht Huglo zu einem umfassenden Werkzeug. Durch den niedrigen Overhead ist Huglo sogar für Systeme mit hohen Anforderungen an Verfügbarkeit und Latenz interessant, etwa Webservices oder SaaS-Plattformen, bei denen jede Millisekunde zählt. Die granulare Analyse der P99.9-Latenz, also des 99,9. Perzentils der Laufzeit, ist genau das, was Manager und Entwickler benötigen, um Kunden-SLAs zu erfüllen und Nutzererfahrungen zu stabilisieren.
Zusammenfassend lässt sich sagen, dass Huglo ein vielversprechender Tracing-Profiler ist, der neue Maßstäbe in Sachen Datenbreite und Laufzeit-Effizienz für Ruby setzt. Damit wird eine Lücke gefüllt, die bisherige Profiler nur unzureichend abdecken konnten, und es eröffnet sich ein neues Potential für Performance-Analyse in Echtzeit und in produktiven Umgebungen. Entwickler, die daran interessiert sind, Huglo bei ihren Projekten einzusetzen, sollten den Kontakt zum Entwicklerteam suchen und ihr Interesse anmelden, um die Weiterentwicklung zu unterstützen und frühzeitig von den Fortschritten zu profitieren. Die Zukunft der Ruby-Profilierung könnte dank Huglo schneller, präziser und ressourcenschonender werden als je zuvor – ein großer Schritt nach vorne für qualitativ hochwertige Anwendungen im produktiven Betrieb.