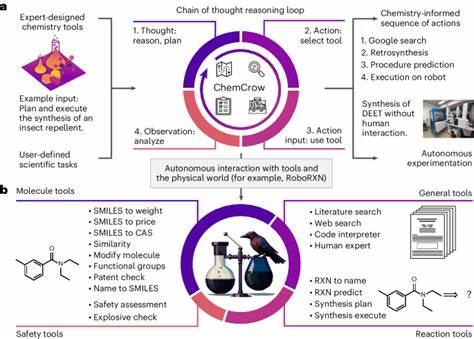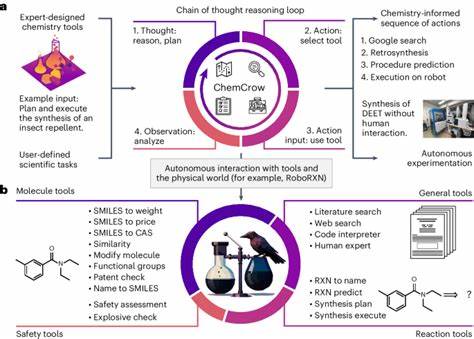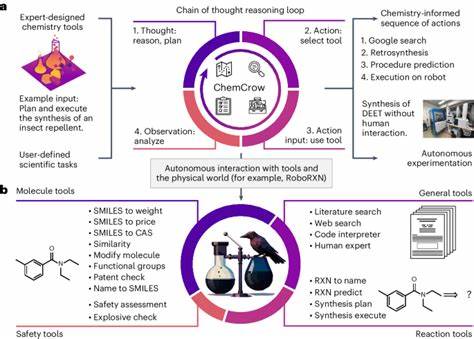
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren zahlreiche Fachgebiete nachhaltig beeinflusst, darunter auch die Chemie. Diese KI-gestützten Systeme sind in der Lage, auf Basis umfangreicher Trainingsdaten menschenähnlichen Text zu generieren, Fragen zu beantworten und komplexe Probleme zu bearbeiten – Fähigkeiten, die früher ausschließlich Experten vorbehalten waren. Die Frage, inwieweit LLMs das chemische Wissen und das Denkvermögen von professionellen Chemikern erreichen oder gar übertreffen können, gewinnt somit zunehmend an Bedeutung. Der Begriff großer Sprachmodelle bezieht sich auf machine-learning-basierte Algorithmen, die auf gewaltigen Textkorpora trainiert wurden, um Zusammenhänge zu erkennen und natürlichsprachliche Texte zu erzeugen. Sie können in der Chemie beispielsweise komplexe Reaktionsmechanismen beschreiben, Sicherheitsinformationen zu Stoffen liefern oder strukturelle Analysen durchführen.
Die weit verbreitete Vorstellung, dass solche Modelle schlichtweg Inhalte wiederkäuen, hat sich durch neue Studien zunehmend relativiert und differenziert. Eine aktuelle Untersuchung hat das ChemBench-Framework vorgestellt, mit dem die Kompetenzen von LLMs systematisch in der Chemie evaluiert werden. Das Besondere daran ist der direkte Vergleich mit dem Fachwissen von Chemikern unterschiedlicher Spezialisierungen. Hierfür wurde ein umfangreicher Fragenkatalog erstellt, der verschiedenste Themen der Chemie abdeckt – von Grundwissen über anorganische und organische Chemie bis hin zu analytischen Methoden und Sicherheitsbewertungen. Die Fragestellungen sind so gestaltet, dass neben reinen Wissensfragen auch komplexe Denkprozesse, Berechnungen und chemische Intuition überprüft werden können.
Die Ergebnisse zeigen ein überraschendes Bild: Spitzenmodelle übertreffen im Durchschnitt sogar die besten in der Studie getesteten menschlichen Chemiker bei der korrekten Beantwortung der Fragen. Dies ist vor allem bei klassischen, wissensbasierten Aufgaben der Fall, bei denen das Modell große Textdatenbanken und wissenschaftliche Publikationen auswerten kann. Dennoch wird deutlich, dass die Systeme bei grundlegenden Aufgaben und solchen, die ein zuverlässiges Abschätzen von Risiken oder das Einhalten von Sicherheitsvorgaben erfordern, Schwierigkeiten haben. Zudem zeigen die LLMs teilweise eine übermäßige Selbstsicherheit in ihren Antworten, was die potenzielle Gefahr von Fehlinformationen unterstreicht. Ein weiterer interessanter Aspekt ist die Fähigkeit der Modelle, chemische Präferenzen zu beurteilen, also etwa die Frage, welche der zwei Substanzen in einem spezifischen Anwendungskontext bevorzugt wird – etwas, das besonders in der Wirkstoffentwicklung wichtig ist.
Hier liegen die Maschinen noch deutlich hinter menschlichen Experten zurück und erreichen oft nur ein Niveau, das dem Zufall entspricht. Dieser Befund offenbart, dass das Erfassen von Subjektivität und Erfahrung in Chemikers Entscheidungen für aktuelle KI-Systeme eine besondere Herausforderung darstellt. Auf fachlicher Ebene differieren die Leistungen der Modelle je nach Themengebiet. Während Allgemein- und Technische Chemie vergleichsweise gut abgedeckt sind, hapert es bei Sicherheitsthemen und analytischer Chemie. Beispielsweise fällt es den Modellen schwer, die Anzahl der Signale in Kernspinresonanz-Spektren präzise vorherzusagen.
Hier spielt die Fähigkeit, molekulare Strukturen effektiv zu interpretieren und zu verknüpfen, eine zentrale Rolle – ein Bereich, in dem künstliche Intelligenz noch Defizite aufweist. Auch die Komplexität einer chemischen Fragestellung spiegelt sich bislang nicht in der Modellleistung wider. Dies lässt vermuten, dass die LLMs in erster Linie auf bereits bekannte Muster und Beispiele aus dem Trainingsmaterial zurückgreifen, statt eigenständiges chemisches Schlussfolgern zu betreiben. Die Fähigkeiten zur echten strukturellen Analyse und zum kreativen Problemlösen sind damit offenbar noch eingeschränkt. Die Erkenntnisse aus dem ChemBench-Projekt verdeutlichen, dass wir in der Chemie nicht nur die Fähigkeiten von KI-Systemen einschätzen müssen, sondern auch die Art und Weise, wie wir Chemie lehren und lernen sollten.
Wenn LLMs das Auswendiglernen von Fakten und das Lösen standardisierter Aufgaben besser beherrschen als Menschen, muss mehr Fokus auf kritisches Denken, praktische Erfahrung und die Interpretation komplexer Daten gelegt werden – Kernkompetenzen, die reine Textmodelle bisher nicht ersetzen können. In der Praxis könnten große Sprachmodelle zukünftig als „Co-Piloten“ fungieren, die Chemiker bei der Planung von Experimenten, der Literaturrecherche oder der schnellen Beantwortung fachlicher Fragen unterstützen. Ihre Fähigkeit, große Informationsmassen in Sekundenschnelle zu verarbeiten, bietet enorme Vorteile und könnte den Forschungsprozess beschleunigen. Gleichzeitig bleibt der Mensch unerlässlich, um potenzielle Fehler zu erkennen, Sicherheit zu gewährleisten und wissenschaftliche Urteile zu fällen. Es ist zudem festzuhalten, dass die Integration spezieller Datenbanken und Abfrage-Tools derzeit noch nicht vollständig erfolgt ist.
Modelle wie PaperQA2, welche externe wissenschaftliche Quellen durchsuchen, können Wissenslücken nicht immer zuverlässig schließen, wenn Zugriff auf tiefere, spezialisierte Ressourcen nötig ist. Deshalb ist die weitere Entwicklung hybrider Systeme, die KI mit domänenspezifischem Wissen verbinden, ein vielversprechender Weg. Die Genauigkeit der Selbsteinschätzung der KI ist ein weiterer kritischer Punkt. Tests zeigen, dass die Modelle kaum zuverlässig einschätzen können, wann sie eine Frage richtig oder falsch beantworten. Solche unkalibrierten Vertrauenswerte erschweren den sicheren Einsatz im chemischen Alltag, insbesondere bei sicherheitsrelevanten Fragestellungen.
Zukünftige Forschung sollte deshalb auch auf die Verbesserung von Unsicherheitsabschätzungen und Vertrauensbewertung abzielen. Schließlich zeigt der Vergleich zwischen proprietären und Open-Source-LLMs, dass auch freizugängliche Modelle durch kontinuierliche Weiterentwicklung und Skalierung stark verbessert werden können. Dies fördert die Demokratisierung von KI-Technologien in der Chemie mit Vorteilen für Wissenschaft und Lehre weltweit. Zusammenfassend lässt sich feststellen, dass die Kombination aus groß angelegten Benchmark-Frameworks wie ChemBench und praxisnahen Studien mit menschlichen Experten ein umfassendes Bild der gegenwärtigen und zukünftigen Rolle von KI in der Chemie liefert. Die Modelle besitzen bereits beeindruckende chemische Fähigkeiten und übertreffen in bestimmten Bereichen die menschliche Leistung.
Gleichzeitig bestehen bedeutende Herausforderungen, insbesondere in Bezug auf chemische Strukturinterpretation, intuitive Präferenzen und verlässliche Vertrauenswerte. Angesichts dessen eröffnet sich eine neue Ära, in der KI und Chemieinterdisziplinarität Hand in Hand gehen müssen. Die Weiterentwicklung solcher Systeme wird maßgeblich von klaren Evaluationsmetriken, ethischer Verantwortung und dem Dialog zwischen Chemikern und KI-Entwicklern abhängen. Nur so kann das volle Potenzial von LLMs sicher und effektiv für die chemische Wissenschaft ausgeschöpft werden.