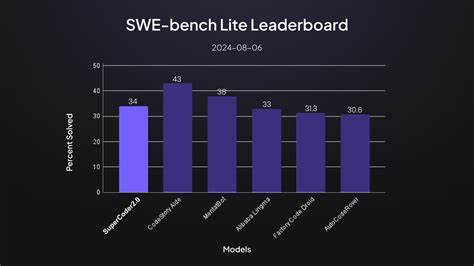
In der heutigen Welt der Softwareentwicklung gewinnen KI-basierte Tools zunehmend an Bedeutung. Die stetig wachsenden Anforderungen an Schnelligkeit, Qualität und Effizienz im Programmieralltag verlangen nach intelligenten Lösungen, die Entwickler nicht nur ergänzen, sondern teilweise ersetzen können. Ein herausragendes Beispiel für diese Entwicklung liefert die Open-Source KI-Agentur Refact.ai durch ihren Agenten, der nun die Spitzenposition auf dem SWE-bench Lite Benchmark einnimmt. Diese Leistung gilt als Meilenstein in der autonomen Programmierung und verdeutlicht die steigende Leistungsfähigkeit und Selbstständigkeit moderner KI-Systeme bei der Bewältigung komplexer Softwareaufgaben.
SWE-bench Lite fungiert dabei als aussagekräftiger Maßstab, der die Kompetenz von LLM-gestützten Systemen bei realen Problemstellungen aus bekannten Python-Projekten auf GitHub misst. Die Herausforderungen des Benchmarks bestehen darin, Fehlerkorrekturen und die Implementierung neuer Funktionen zu vollziehen sowie deren Korrektheit mittels automatisierter Tests zu überprüfen. Hierdurch zeichnet sich SWE-bench Lite durch starke Praxisnähe aus – es bewertet nicht nur den reinen Code, sondern auch dessen Zuverlässigkeit und Funktionalität in realen Anwendungsszenarien. Das Besondere am Refact.ai Agent ist sein vollständig autonomer, iterativer Problemlösungsansatz.
Er plant, führt aus, testet und korrigiert selbstständig und ist in der Lage, Aufgaben von Anfang bis Ende ohne menschliches Zutun erfolgreich abzuschließen. Dabei setzt die zugrundeliegende Architektur auf das hochentwickelte Modell Claude 3.7 Sonnet, das für Steuerung und Entscheidungsfindung verantwortlich ist und mit integrierten Werkzeugen nahtlos mit der Entwicklungsumgebung kommuniziert. Unter den Werkzeugen ragt insbesondere das deep_analysis() Tool hervor. Dieses wird an kritischen Punkten der Problemlösung aktiviert und ermöglicht eine strukturierte, mehrstufige Denkweise, die die Qualität der Lösung erheblich verbessert.
Dabei fungiert ein kleiner, besonders schneller Reasoning-Kern namens o4-mini als spezialisierte Unterstützungseinheit, während Claude 3.7 das orchestrierende Gesamtbild steuert. Die Funktionsweise von deep_analysis() gliedert sich in die Schritte Lösungsentwurf, detaillierte Kritik und anschließend umfassende Verfeinerung. Diese wiederholten Schleifen optimieren die generierten Codeänderungen hinsichtlich Minimalität, Robustheit und Effektivität – bedingt durch eine gründliche Identifikation von Schwachstellen und deren gezielte Behebung. Die Fähigkeit des Refact.
ai Agent, selbst zu entscheiden, wann das deep_analysis() Tool eingesetzt wird, ist ein klarer Indikator für den adaptiven, nicht starren Charakter seines Lösungsprozesses. Neben der ausgefeilten KI-Logik ist die Bandbreite an Tools, auf die der Agent zurückgreift, ein weiterer Erfolgsfaktor. Funktionen zur Code-Erkundung ermöglichen es, komplexe Codebasen zu durchdringen, Abhängigkeiten zu erkennen und präzise relevante Stellen zu identifizieren. Editing-Werkzeuge erlauben es, Textdokumente anzulegen oder zu modifizieren, während die Shell-Ausführung die Ausführung von Tests und damit fortlaufende Verifikation der vorgenommenen Änderungen realisiert. Durch die autonome Nutzung dieser Instrumente kann der Agent dynamisch und kontextsensitiv handeln, was ihn von semi-automatisierten Ansätzen deutlich unterscheidet.
Ein weiterer wichtiger Aspekt des Benchmark-Settings ist die Beschränkung auf 60 Schrittaktionen pro Aufgabe. Jeder Schritt stellt eine einzelne Handlung wie Dateiveränderung, Verzeichnisaufzählung oder Testausführung dar. Innerhalb dieser Limitierung beweist der Agent strategisches Geschick, indem er die Schritte effizient einsetzt, um klare, nachvollziehbare und kausal zusammenhängende Lösungen zu erzielen. Die beeindruckende Erfolgsquote von 59,7 Prozent bei insgesamt 300 SWE-bench Lite Aufgaben positioniert den Refact.ai Agent unangefochten an der Spitze.
Er konnte 179 Probleme lösen, darunter Aufgaben, die bislang von keinem anderen Agenten bewältigt wurden – insbesondere aus den Bereichen django und sympy. Dieses Ergebnis spiegelt nicht nur die hohe Qualität und Reife seiner Algorithmen wider, sondern belegt auch den Mehrwert der eingebundenen Reasoning-Modelle und der fließenden Schritt-für-Schritt-Strategie. Eine Analyse der hinsichtlich erlittener Probleme und Erfolgschancen variierenden Ergebnisverteilung in unterschiedlichen Open-Source-Projekten verdeutlicht somit die Bandbreite seiner Fähigkeiten. Projekte wie django und scikit-learn erreichen überdurchschnittliche Lösungserfolge, während andere komplexe Repositories mit teilweise höheren Herausforderungen ein realistisches Bild von den Limitationen geben. Die Vision von Refact.
ai geht jedoch weit über das reine Benchmark-Ranking hinaus. Die autonome KI-Plattform repräsentiert exemplarisch den Wandel in der Softwareentwicklung, bei dem menschliche Entwickler mehr Zeit für kreative und strategische Tätigkeiten gewinnen, während Routineaufgaben automatisiert ablaufen. Mit nahtloser Integration in gängige IDEs wie Visual Studio Code oder JetBrains adressiert der Agent die alltäglichen Bedürfnisse der Entwicklergemeinschaft und verspricht eine signifikante Effizienzsteigerung. Perspektivisch plant Refact.ai, die Agentenleistung auf den erweiterten SWE-bench Verified Benchmark auszudehnen.
Dieser richtet sich durch strengere Testverfahren auf eine noch realitätsnähere Qualitätskontrolle aus und soll den Fokus auf tiefergehende Funktionalität und Zuverlässigkeit lenken. Neben technologischem Fortschritt ist auch die Offenheit der Lösung hervorzuheben. Refact.ai setzt konsequent auf Open Source, was Entwicklern weltweit ermöglicht, die Mechanismen hinter autonomer KI nachvollziehen, mitgestalten oder erweitern zu können. Dieses transparente Vorgehen fördert eine lebendige Community und beschleunigt Innovationszyklen.
Zusammenfassend verdeutlicht der Erfolg des Refact.ai Agenten die Reife autonomer Softwareentwicklung, die bereits heute in der Lage ist, komplexe Entwicklungsaufgaben unabhängig und verlässlich zu meistern. Dieses Paradigma wird in Zukunft alle Phasen des Software-Lebenszyklus durchdringen, von Fehleridentifikation über Implementierung bis zu Test und Validierung. Für Entwickler ergibt sich daraus eine Chance, sich auf wertschöpfende Aspekte zu konzentrieren und KI als verlässlichen Partner zu integrieren. Die Kombination aus Algorithmik, systematischem Vorgehen und offenen Ökosystemen wird die Softwareentwicklung revolutionieren und eine neue Ära des kollaborativen Programmierens einläuten.
Refact.ai Agent liefert hierfür ein eindrucksvolles Beispiel, das den Weg zur Zukunft kontinuierlich ebnet.