Datenbanksysteme bilden das Rückgrat moderner digitaler Anwendungen, von E-Commerce bis zu Finanzsystemen. Trotz ihrer Allgegenwart und scheinbaren Einfachheit steckt im Inneren eine komplexe Welt aus Disk- und Speichermanagement sowie einem ausgeklügelten Mechanismus zur Handhabung gleichzeitig ablaufender Prozesse, den sogenannten Concurrency-Mechanismen. Ein Verständnis dieser Kernkomponenten ist nicht nur für Entwickler, sondern auch für IT-Entscheidungsträger und Systemadministratoren von großem Vorteil, um die Leistungsfähigkeit, Zuverlässigkeit und Skalierbarkeit von Datenbanksystemen zu gewährleisten. Grundlegend für die Speicherung von Daten in einer Datenbank ist die Art und Weise, wie Informationen auf externen Speichermedien abgelegt werden. Im Zentrum steht die Unterscheidung zwischen den physikalischen Festplatten, den sogenannten Disks, und der Art und Weise, wie der Datenbankzugriff auf diese erfolgt.
Disks bestehen im Wesentlichen aus Blöcken fester Länge, welche typischerweise Größen im Bereich von 1024 bis 8192 Bytes haben. Direkt auf diese Blöcke zuzugreifen, ist zwar möglich, beispielsweise mit Werkzeugen wie dd unter Linux, jedoch handelt es sich dabei um einen sehr niedrigen Abstraktionsgrad, der viel Fachwissen erfordert und im normalen Datenbankbetrieb nicht zur Anwendung kommt. Stattdessen greifen Datenbanken über das Dateisystem auf diese Blöcke zu. Das Dateisystem abstrahiert die physikalischen Blöcke in logische Einheiten, sprich Dateien, die das System in Verzeichnissen organisiert. Auf diese Weise kann der Datenbank-Engine gezielt eine Position innerhalb einer Datei angesprochen werden, ohne Details der zugrundeliegenden physikalischen Organisation zu kennen.
Dennoch bleibt der Zugriff für die Datenbankengine in Form von festen, logisch zusammenhängenden Blöcken erhalten. Jede Datei lässt sich als eine geordnete Sequenz solcher Blöcke betrachten und hierauf arbeitet die Datenbank, um Daten konsistent und performant zu verwalten. Im Speicher eines Computers werden diese Blöcke als Pages, also speicherseitige Abbildungen dieser Blöcke, repräsentiert. Das Paging-Konzept ist ein essenzieller Inhalt von Datenbanken: Jede Lese- oder Schreiboperation erfolgt zunächst im Hauptspeicher und wird dann auf das Speichermedium übertragen. Dieser Ansatz bringt den großen Vorteil mit sich, dass Zugriffe auf die vergleichsweise langsame Disk reduziert und vor allem zeitlich gebündelt werden können.
Da Hauptspeicher deutlich schneller als Disks ist, streben Datenbanksysteme danach, möglichst viele Operationen im Speicher durchzuführen und nur wenn nötig den Übergang zur Speicherung auf Disk vorzunehmen. Die Geschwindigkeit der Datenträger spielt dabei eine entscheidende Rolle. Die historisch weitverbreiteten Hard Disk Drives (HDDs) sind physisch mechanisch aufgebaut und weisen dementsprechend eine hohe Latenz auf. Sie sind aber vergleichsweise günstig. Im Gegensatz dazu stehen Solid State Drives (SSDs), welche rein elektronisch arbeiten, eine deutlich niedrigere Latenz besitzen und immer günstiger werden.
Moderne NVMe-SSDs übertreffen SATA-SSDs und HDDs in puncto Geschwindigkeit und Effizienz und bieten so optimale Voraussetzungen für datenintensive Anwendungen. Dennoch bleiben sowohl HDDs als auch SSDs im Vergleich zum Arbeitsspeicher langsamer, weshalb ein intelligentes Speicher- und Caching-Management unabdingbar ist. Das Kernstück moderner Datenbanksysteme im Speicher ist der sogenannte Buffer Pool. Der Buffer Pool ist ein zusammenhängender Speicherbereich, welcher eine begrenzte Anzahl von Pages, also Speicherblöcken, hält und vom Buffer Manager verwaltet wird. Sein Ziel ist es, möglichst viele Datenzugriffe auf den Speicher zu konzentrieren und auf langsame Disk-Zugriffe zu verzichten.
Wenn eine Anwendung Daten liest, werden die entsprechenden Diskblöcke in den Buffer Pool geladen und dort vorgehalten. Wollen weitere Clients auf dieselben Daten zugreifen, können sie dies direkt im Hauptspeicher tun, ohne erneuten Zugriff auf die Disk. Der Buffer Pool arbeitet mit sogenannten Pins, die markieren, wie viele Nutzer gerade eine bestimmte Page verwenden. Ist eine Page gepinnt, darf sie nicht aus dem Buffer Pool entfernt werden. Erst wenn alle Nutzer ihre Pins wieder freigeben, kann der Buffer Manager diese Page gegebenenfalls durch eine andere ersetzen, wenn Speicherplatz benötigt wird.
Die Wahl, welche Page aus dem Buffer Pool ersetzt wird, ist ein zentrales Performancekriterium und wird über Algorithmen wie FIFO (First In, First Out) oder LRU (Least Recently Used) gesteuert. Effektives Cache-Management sorgt dafür, dass häufig benötigte Daten im Buffer Pool gehalten werden und somit die Zahl der teuren Diskzugriffe minimiert wird. Ein weiterer essentieller Aspekt in Datenbanksystemen ist das sogenannte Write-Ahead Logging (WAL). Die Idee dahinter ist, dass jede Änderung, die an den Daten vorgenommen wird, zuerst in einem Log, also einem Protokoll, festgehalten wird, bevor sie in den Speicher und letztendlich auf die Disk geschrieben wird. Dieses Protokoll stellt eine nachvollziehbare Reihenfolge aller Änderungen sicher und ist unverzichtbar für die Datenintegrität bei möglichen Systemabstürzen oder Ausfällen.
Da Schreibzugriffe auf Disks vergleichsweise langsam sind, ermöglicht das Loggen eine optimierte Schreibstrategie: Alle Änderungen werden erst in das Log geschrieben und dann asynchron auf die eigentlichen Datendateien übertragen. Solange das Log persistiert ist, gilt die Datenänderung als sicher, auch wenn die eigentlichen Datenblöcke noch nicht auf die Disk geschrieben wurden. Bei einem Absturz kann die Datenbank anhand des Logs rekonstruieren, welche Daten endgültig übernommen wurden, und welche eventuell noch überarbeitet oder verworfen werden müssen. Dieses Verfahren unterstützt die sogenannte Durability-Eigenschaft von Datenbanken und ist ein Baustein für deren Zuverlässigkeit. Während Speicher- und Disk-Management bereits komplex sind, stellen nebenläufige Zugriffe auf die Daten den eigentlichen Kern der Herausforderung dar.
In modernen Anwendungen greifen viele Nutzer und Prozesse simultan auf dieselben Daten zu. Hierfür müssen Datenbanken gewährleisten, dass die Resultate korrekt und konsistent bleiben, auch wenn sehr viele Operationen parallel stattfinden. Die Lösung findet sich in Transaktionen und dem Concurrency Management. Transaktionen sind abstrahierte Abläufe, in denen mehrere Datenbankoperationen zusammengefasst werden und die Eigenschaften ATOMICITY, CONSISTENCY, ISOLATION und DURABILITY – zusammen als ACID-Eigenschaften bekannt – erfüllen. ATOMICITY garantiert, dass alle Schritte einer Transaktion entweder vollständig ausgeführt werden oder gar nicht, um inkonsistente Zustände zu verhindern.
CONSISTENCY stellt sicher, dass die Transaktion gültige Daten hinterlässt. ISOLATION bewirkt, dass sich parallele Transaktionen nicht gegenseitig beeinflussen und DURABILITY sorgt dafür, dass abgeschlossene Transaktionen dauerhaft gespeichert sind. Das Umsetzen dieser Eigenschaften beginnt mit Sperren oder Locks, die sicherstellen, dass konkurrierende Transaktionen nicht gleichzeitig inkompatible Operationen auf denselben Daten durchführen. Es gibt hauptsächlich zwei Arten von Sperren: shared Locks (S-Locks), die für Lesezugriffe verwendet werden, und exclusive Locks (X-Locks), die für Schreiboperationen nötig sind. Während mehrere Transaktionen gleichzeitig S-Locks auf denselben Datenobjekten halten können, ist X-Lock exklusiv – also darf in diesem Zustand kein anderer Zugriff stattfinden.
Durch ein Lock-Management können sogenannte Race Conditions oder Inkonsistenzen verhindert werden, wie sie auftreten würden, wenn zwei Nutzer gleichzeitig denselben Datensatz verändern. Beispielsweise bei einer E-Commerce-Produktbestandsverwaltung verhindert ein X-Lock während einer Inventarreduzierung, dass ein anderer Nutzer parallel denselben Bestand liest und ebenfalls reduziert, was zu falschen Ergebnissen führen würde. Das Locking wird zentral über eine Lock-Tabelle verwaltet, die sämtliche aktiven Sperren auf Datenblöcken oder Datensätzen hält. Transaktionen fragen beim Lock-Manager an, ob ein Lock gewährt werden kann. Falls nicht, wartet die Transaktion oder wird blockiert, bis das Lock frei wird.
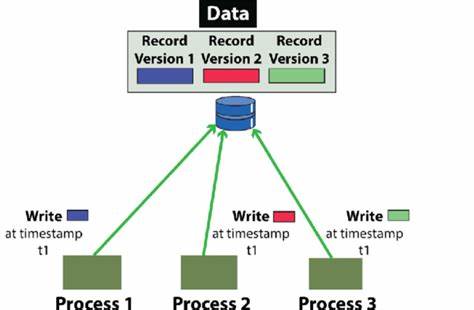
Ein solcher Mechanismus gewährleistet Isolation und damit die Serialisierbarkeit der Transaktionen, also dass das Ergebnis einer gleichzeitigen Ausführung auch durch eine seriell nacheinander ablaufende Sequenz erreicht werden könnte. Neben dem klassischen Locking gibt es ein weiteres Problem: die sogenannten Phantom Reads. Diese treten auf, wenn sich während einer Transaktion Datenmengen verändern – etwa wenn neue Datensätze hinzugefügt werden. Um auch diese Problemstellung zu adressieren, verwenden Datenbanksysteme zusätzliche Sperrmechanismen oder MVCC (Multi-Version Concurrency Control), womit verschiedene Datenbankversionen zur gleichen Zeit vorgehalten werden können. Ein weiterer wichtiger Mechanismus zur Gewährleistung der Datenbankstabilität ist die Transaktionsprotokollierung, bei welcher jeder Schritt einer Transaktion als Log-Eintrag festgehalten wird.
Dies ermöglicht, bei einem Systemabsturz nicht abgeschlossene Transaktionen zurückzurollen und somit die Datenkonsistenz zu bewahren. Im Zusammenspiel ergeben Diskmanagement, Speichermanagement und Concurrency Control die Grundlage für die hohe Performance und Zuverlässigkeit moderner Datenbanksysteme. Diese funktionieren als fein abgestimmte Maschinen, in denen schnelle Speicherzugriffe, verlässliche Speicherpersistenz und synchronisierte parallele Verarbeitung ineinandergreifen. Die Bedeutung dieser Themen nimmt mit wachsender Datenmenge und steigender Nutzerzahl weiter zu. Während Cloud-basierte Architekturen, Microservices und Big Data weiterhin komplexere Anforderungen stellen, ist das Fundament im effizienten Umgang mit Disk, Speicher und konkurrierenden Zugriffen unersetzlich.
Es lohnt sich daher, dieses Fundament eingehend zu verstehen und zu beherrschen, um zukunftsfähige und skalierbare Datenbanksysteme zu entwickeln und zu betreiben.