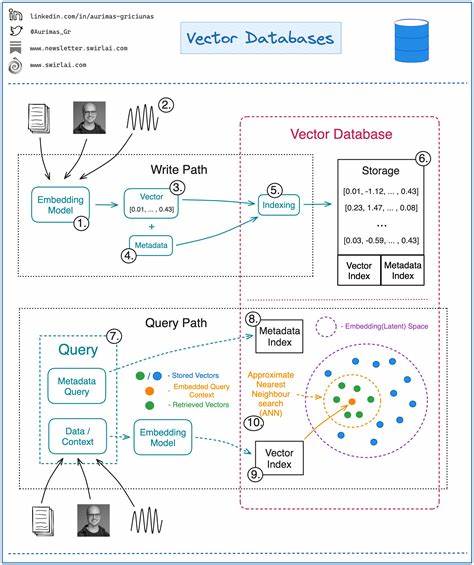
In der heutigen Zeit, in der Datenmengen exponentiell wachsen und Informationen in unterschiedlichster Form vorliegen, wird die effiziente Suche nach ähnlichen Objekten immer wichtiger. Ob Texte, Bilder oder Audio – eine der technisch vielversprechendsten Methoden, solche Daten zu durchsuchen, basiert auf Vektoren und deren Ähnlichkeiten. Die Errichtung einer eigenen Vektordatenbank zielt darauf ab, diese Konzepte zu verstehen und praktisch umzusetzen. Insbesondere stellt das Konzept der Hierarchischen Navigierbaren Small Worlds (HNSW) eine der populärsten Datenstrukturen dar, die heute in zahlreichen Systemen wie Weaviate, Elasticsearch, Vespa oder OpenSearch eingesetzt wird. Vektoren sind in ihrer Grundform nichts anderes als Zahlenreihen, deren Länge häufig in hunderten oder tausenden Dimensionen liegt.
Ein Vektor mit 768 oder 1536 Dimensionen beschreibt somit ein Objekt in einem hochdimensionalen Raum. Diese Objekte können beispielsweise Wörter, Sätze, Bilder oder andere komplexe Daten sein, die durch sogenannte Embeddings repräsentiert werden. Embeddings entstehen durch maschinelles Lernen und verwandeln komplexe Eingaben in dichte Vektorrepräsentationen. Durch diesen Prozess nähern sich ähnliche Inhalte räumlich an und repräsentieren ihre semantische Nähe. So können Sätze, die keine gemeinsamen Worte besitzen wie „Mary hatte ein kleines Lamm“ und „Little Bo Peep hatte ein Schaf“, dennoch sehr nahe im Vektorraum liegen und somit als ähnlich erkannt werden.
Der technische Anspruch bei der Vektorsuche ist es, aus einem riesigen Datensatz an Embeddings diejenigen zu finden, die einem gegebenen Abfragevektor am nächsten sind. Die Herausforderung wächst mit Millionen oder Milliarden von gespeicherten Vektoren. Die Suche nach den K nächsten Nachbarn (KNN) in solch hochdimensionalen Räumen ist deshalb eine knifflige Aufgabe. Ein einfaches Beispiel aus zweidimensionalen Daten kann dabei helfen, diese Komplexität zu verstehen. Beispielsweise können zwei Dimensionen als Breitengrad und Längengrad verstanden werden, um Standorte auf einer Landkarte darzustellen.
Obwohl diese Analogie nicht perfekt auf tausende Dimensionen anwendbar ist, verdeutlicht sie grundlegende Probleme der Suche. Eine intuitiv-nahe Vorstellung ist es, den Suchraum in Gitter oder Regionen aufzuteilen, um Kandidaten für die Nähe an einem Ort zu reduzieren. Für Karten könnte man etwa mit einem Raster aus Unterregionen operieren, wie dem US National Grid. Möchte man beispielsweise in New York City den nächsten Nachbarn finden, würde man in das entsprechende Rasterfeld hereinzoomen. Doch diese Methode stößt schnell an Grenzen.
In dicht besiedelten Gebieten wie New York ergeben sich Millionen möglicher Datenpunkte, die innerhalb eines einzigen Rasters liegen, wodurch die Suche überfrachtet und ineffizient wird. Ein bloßes Vergrößern der Rasterauflösung ist auch keine Lösung, denn in dünn besiedelten Regionen wie Wyoming ist die Distanz zu Nachbarn viel größer und somit die Rasterung kontraproduktiv. Das Ergebnis ist die wichtige Erkenntnis, dass die Suche nach nächsten Nachbarn nicht allein von der räumlichen Entfernung innerhalb eines kleinräumigen Bereichs abhängt. Die Verteilung der Datenpunkte spielt eine zentrale Rolle. In hochdimensionalen Räumen, in denen sich Vektoren befinden, wird diese Herausforderung noch komplexer, da sich Daten ungleichmäßig verteilen und viele Freiheitsgrade besitzen.
Die Suche muss also sensibel mit der tatsächlichen Verteilung und Dichte der Daten umgehen. Eine Möglichkeit, mehr Sensitivität für die spezifische Verteilung zu erzeugen, ist die Quantisierung. Im vektorbasierten Kontext bedeutet Quantisierung häufig, Zahlenwerte zu vereinfachen oder zusammenzufassen. Statt einen Wert wie 40,7128 exakt zu speichern, könnte man ihn auf 40,7 runden, was Speicherplatz spart, aber Genauigkeit opfert. Hochentwickelte Quantisierungsverfahren, wie Produktquantisierung oder sogenannte Better Binary Quantization (BBQ), passen diese Transformationen jedoch intelligent an die echte Datenverteilung an.
So könnte man Zonen mit dichter Besiedlung stärker differenzieren und dünn besiedelte Gebiete vergröbert abbilden, um eine bessere Balance zwischen Genauigkeit und Effizienz zu erreichen. Clustersysteme wie das k-Means Clustering ergänzen diesen Ansatz. Dabei wird der Datenraum in eine Anzahl von Zentren (Centroiden) unterteilt, die die umliegenden Punkte möglichst gut repräsentieren. Das System optimiert, indem es die Centroiden so positioniert, dass ihre durchschnittliche Distanz zu den zugeordneten Punkten minimiert wird. Nach dem Training kann ein Vektor also direkt einem Cluster zugeordnet werden, was die Suche auf eine kleinere Teilmenge fokussiert und so die Effizienz enorm steigert.
Diese Clusterierung ist auch die Grundlage für mehrere milliardenschwere Vektorindizes und findet Anwendung in Systemen wie SCANN oder TURBOPUFFER. Doch all diese Methoden haben ihre Grenzen, weshalb der Fokus auf Graphstrukturen wie HNSW fällt. HNSW baut einen Graphen aus Vektorknoten auf, bei dem jeder Knoten Verbindungen zu anderen Knoten besitzt. Die Suche erfolgt dabei entlang dieses Netzes, ausgehend von einem willkürlichen Einstiegspunkt, und führt durch systematisches Navigieren zu immer näher liegenden Punkten an das Suchziel. Diese Methode ahmt den Prozess des Wegfindens auf einer Landkarte nach, bei dem an Kreuzungen die Abzweigung gewählt wird, die näher am Ziel liegt, während bereits besuchte Orte gemieden werden, um Schleifen zu verhindern.
Das grundsätzliche Prinzip ist einfach, gleichzeitig ermöglicht der Graph vielfältige Optimierungen. Jeder Knoten hält dabei eine Liste von Nachbarn. Beim Suchen wird eine Prioritätsstruktur genutzt, um stets die aktuell besten Kandidaten für eine weitere Exploration festzuhalten. Python-Beispiele zeigen, wie man solche Suche implementieren kann – inklusive Tracking besuchter Knoten und dynamischer Auswahl der Nachbarn. Die Knotenanzahl der Nachbarn ist ein wichtiger Aspekt.
In einer einfachen Implementierung ist die Anzahl der Verbindungen pro Knoten unbegrenzt, was sich in echten Anwendungen als problematisch erweist. Die Qualität der Suche verbessert sich mit einer optimalen Balance zwischen Verbindungsdichte und Performance. Es ist ebenfalls entscheidend, nicht nur mit einem direkten Nachbarn zu navigieren, sondern mehrere alternative Pfade gleichzeitig zu berücksichtigen – Parameter wie ef (die Suchtiefe) und M (die maximale Anzahl an Nachbarn pro Knoten) steuern diese Aspekte. Ein herausragendes Merkmal von HNSW ist die Hierarchie. Vergleichen wir es mit Straßentypen: Ein Navigationssystem verlässt sich nicht nur auf kleine Nebenstraßen, sondern nutzt Autobahnen und Schnellstraßen für lange Strecken, damit Ziele schneller erreicht werden.
Im Vektorgraphen sind die höheren Ebenen der Hierarchie solche „Highways“, die die Daten in grobe Bereiche ordnen. Die Suche beginnt in diesen oberen Ebenen und steigt dann schrittweise in die feineren Ebenen ab, um das optimale Ziel zu finden. Diese Schichtung ermöglicht eine exponentielle Reduktion der Sucheffizienz bei sehr großen Datenvolumina. Insgesamt zeigt sich, dass eine eigene Vektordatenbank zu entwickeln ein faszinierendes Unterfangen ist, das Wissen in Bereichen wie hochdimensionale Geometrie, Graphentheorie und algorithmische Optimierung erfordert. HNSW stellt einen klugen Kompromiss dar, der praktikable Laufzeiten und hohe Genauigkeit vereint.
Durch die Kombination von Quantisierung, Clustering, Graphenstruktur und Hierarchie entsteht ein flexibles System, das den Ansprüchen moderner Anwendungen gerecht wird. Für Entwickler und Forscher, die sich mit der Vektorsuche auseinandersetzen wollen, bietet das Studium von HNSW eine wertvolle Grundlage. Klar ist aber auch, dass die implementierte Version nur den Anfang markiert. In der Praxis erfordert das Zusammenspiel von Anpassung der Parameter, Ressourcenoptimierung und skalierbarer Infrastruktur weitere Schritte. Wer tiefer in das Thema eintaucht, entdeckt schnell, wie vielfältig die Möglichkeiten sind und wie wichtig ein solides Verständnis der Technik für innovative Suchlösungen ist.
Am Ende bleibt die Erkenntnis, dass die Suche nach den nächsten Nachbarn in hochdimensionalen Vektorräumen kein triviales Unterfangen ist. Es bedarf eines ganzheitlichen Ansatzes, der die Eigenheiten der Daten berücksichtigt und intelligente Datenstrukturen wie HNSW nutzt. Wer diesen Weg einschlägt, kann von effektiven, schnellen und skalierbaren Suchsystemen profitieren, die in vielen digitalen Anwendungen von morgen eine Schlüsselrolle spielen werden.








