Die Verarbeitung und Extraktion von Inhalten aus unterschiedlichen Dokumentenformaten stellt Unternehmen und Entwickler vor immer größere Herausforderungen. Insbesondere bei PDFs, PowerPoint-Präsentationen oder Word-Dokumenten mit eingebetteten Bildern, Tabellen und Grafiken wird die zuverlässige Erkennung und strukturierte Weiterverarbeitung zur komplexen Aufgabe. Traditionelle Ansätze, die hauptsächlich auf simplen OCR-Verfahren basieren, stoßen schnell an ihre Grenzen, wenn es um visuell aufwändige Dokumente oder gescannte Unterlagen geht. Genau hier setzen moderne multi-modale Large Language Models an und schaffen eine völlig neue Dimension der Dokumenteninhaltsanalyse. Die Problematik bei der herkömmlichen Dokumentenextraktion liegt häufig in der fehlerhaften Erkennung von komplexen visuellen Elementen oder dem Verlust wichtiger Text- und Strukturdaten.
Zahlreiche Nutzerberichte zeigten, dass Texte fehlen oder unvollständig extrahiert werden, was die Qualität von Suchfunktionen, Zusammenfassungen und weiteren automatisierten Prozessen empfindlich beeinträchtigte. Solche Datenverluste führen zu einem Vertrauensverlust bei Endanwendern und verhindern eine effiziente Nutzung der gespeicherten Informationen. Die analytische Untersuchung solcher Ausfälle stützt sich auf umfassende Logdaten und Abfragen aus dem Systemmonitoring. Dabei zeigte sich, dass vor allem gescannte Bilder oder bildbasierte PDF-Dateien oft unbrauchbare, wirre Texte lieferten, während Tabellen und Diagramme ganz übersehen oder falsch interpretiert wurden. Die bisherigen OCR-basierten Techniken, darunter bewährte Tools wie Apache Tika, konnten in vielen dieser Szenarien nicht überzeugen, insbesondere bei visuell schwer zu greifenden Inhalten.
Mit der Einführung eines vision-fähigen Large Language Models änderte sich der Umgang mit diesen Herausforderungen grundlegend. Ein neuer Microservice wurde entwickelt, der Dokumente zunächst in überschaubare Abschnitte von vier bis zwanzig Seiten teilt. Dieses Vorgehen beugt der Überschreitung von Tokenlimits vor, erleichtert parallele Verarbeitungsschritte und sorgt für eine verbesserte Fehlertoleranz, da Teilabschnitte unabhängig neu berechnet werden können. Die Speicherung der segmentierten Dateiinhalte und deren Metadaten in einer Cloudumgebung schafft zudem eine robuste Grundlage für idempotentes Wiederholen von Extraktionsprozessen. Besondere Aufmerksamkeit erhielt die gezielte Optimierung der Eingabeaufforderungen an das Modell, um visuelle Inhalte vielschichtiger zu erfassen.
Ein intelligentes Prompt Engineering sorgt dafür, dass Farben, Formen, Layouts sowie Text, Beschriftungen und strukturierte Informationen systematisch erkannt und in gut strukturiertem Markdown-Format ausgegeben werden. Diese methodische Präzision bei der Beschreibung der Bildinhalte erhöht die inhaltliche Tiefe und die Nachvollziehbarkeit der extrahierten Daten, was bei nachgelagerten Funktionen wie Suche oder Analyse klare Vorteile bringt. Um eine flexible und modulare Anbindung sicherzustellen, wurde eine neue Extraktionsschnittstelle implementiert, die dynamisch Tochterprozesse und externe Systeme anspricht. Diese Architektur erlaubt es, je nach Dateityp und Komplexität optimale Extraktionspfade einzuschlagen und nahtlos zwischen den verschiedenen Technologien zu vermitteln. Ein weiterer zentraler Aspekt war die Einführung eines transparenten Fehlermanagements, das Tokenüberschreitungen und andere Extraktionsfehler klar signalisiert.
Dies verbessert die Nutzererfahrung deutlich, da Anwender gezielte Hinweise zum Grenzen der Verarbeitung erhalten und so Enttäuschungen vermieden werden können. Erhebliche Verbesserungen zeigen sich sowohl in quantitativer als auch qualitativer Hinsicht. In umfangreichen Dokumenten stieg die Anzahl der generierten Embeddings von niedrigen einstelligen auf über zweihundert. Die durchschnittliche Verarbeitungszeit blieb mit circa vier Sekunden pro Seite effizient, ermöglicht also eine praktische Integration in reale Produktionssysteme. Die Segmentierung des Testdokuments führte zu einer deutlich feineren granulären Aufteilung, was die Nachbearbeitung durch Such- und Analysewerkzeuge optimierte.
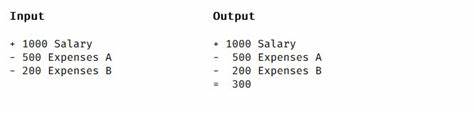
Besonders vorteilhaft ist die Fähigkeit des Systems, Tabellen flexibel als Markdown oder HTML abzubilden, je nach Komplexität der Datenstruktur. Mathematische Formeln und Programmcode bleiben vollständig erhalten, wodurch wichtige Fachinformationen nicht verloren gehen. Auch in der Produktionsumgebung bewährte sich das neue System durch eine robuste Handhabung von Fehlern und automatisierte Wiederaufnahmen bei Teilabbrüchen. Die automatische Konvertierung von schwer unterstützten Formaten wie PowerPoint in PDF ermöglicht eine ganzheitliche Dokumentabdeckung ohne manuelle Zwischenschritte. Ein erfolgreiches Praxisbeispiel ist die aufwändige Schnittstellenerweiterung für das „Untitled James Donovan Project“, bei dem die Anzahl hochwertiger Inhaltssegmente von 10 auf 268 gesteigert wurde.
Die gewonnenen Erkenntnisse zeigen klar, dass tokenbasierte Begrenzungen eine fundamentale Herausforderung darstellen, die nur durch clevere Segmentierung und stufenweise Verarbeitung elegant umgangen werden kann. Die kontinuierliche Verbesserung der Promptgestaltung wirkt sich direkt auf Qualität und Struktur der Ausgabe aus und kann zu signifikanten Fortschritten führen. Zudem stellt die explizite Fehlerkommunikation sowohl für Entwickler als auch Endnutzer einen erheblichen Mehrwert dar, da sie eine gezielte Fehlerbehebung und klare Nutzeranweisungen ermöglicht. Zur ganzheitlichen Systemüberwachung sind sowohl quantitative Metriken als auch manuelle Inspektionen unverzichtbar. Zukünftige Entwicklungen konzentrieren sich auf eine noch flexiblere Unterstützung weiterer Dateiformate wie DOCX sowie auf eine adaptive Chunkgröße, die sich dynamisch an die Informationsdichte des Inhalts anpasst.
Mittels weiterentwickelter semantischer Analyse soll die automatische Kennzeichnung und Priorisierung von Bildinhalten noch effizienter gestaltet werden. Darüber hinaus ist eine automatische Feineinstellung der Prompts geplant, die anhand von Metadaten der Dokumente eine optimierte individuelle Extraktion gewährleistet. Um die Skalierbarkeit des Systems zu sichern, werden auch Schutzmechanismen gegen Überlastungen in der Extraktionslogik priorisiert. Insgesamt führt der Einsatz multi-modaler Large Language Models in Kombination mit sorgfältig entwickelten Prompt-Strategien zu einem deutlichen Sprung in der Dokumenteninhalts-Extraktion. Unternehmen profitieren von präziseren Suchergebnissen, besser strukturierten Zusammenfassungen und einer deutlich gesteigerten Nutzerzufriedenheit.
Diese Neuerungen schaffen eine solide Basis für zukunftssichere digitale Dokumentenprozesse und stärken langfristig das Vertrauen in automatisierte Inhaltsanalyseverfahren.







![3D Printing Homes in 1930 – Urschel Wall Building Machine [video]](/images/FBA92FE6-0EE9-43C6-824D-C1B56BE5A6CC)