Die Suche nach relevanten Informationen im Internet ist durch die sich stetig weiterentwickelnde Technologie immer schneller und präziser geworden. Suchmaschinen sind das Herzstück dieser Entwicklung, und ihre Leistungsfähigkeit hat direkten Einfluss auf die Benutzererfahrung. Um diese Leistungsfähigkeit objektiv zu messen und zu vergleichen, bedarf es standardisierter Benchmarks. Ein besonders interessantes Projekt in diesem Zusammenhang ist „Search Benchmark, the Game“, das von den Entwicklern der Tantivy-Suchbibliothek ins Leben gerufen und auf GitHub öffentlich gepflegt wird. Dieses Benchmark-Framework bietet einen umfassenden Einblick in die Funktionsweise und Effizienz moderner Suchsysteme und ermöglicht den Vergleich von Suchmaschinen verschiedener Programmiersprachen, Architekturen und Optimierungen.
Das Benchmark wurde ursprünglich 2018 von Jason Wolfe initiiert und hat sich seit 2023 zu einem aktiven und kontinuierlich weiterentwickelten Werkzeug gemausert. Seine Hauptaufgabe ist, Suchanfragen aus einem realistischen Datensatz gegen eine exportierte Version der englischen Wikipedia auszuführen. Die darin enthaltenen Queries stammen aus dem AOL-Datensatz, kombiniert mit weiteren herausfordernden Suchbeispielen, die ganz unterschiedliche Leistungseigenschaften aufzeigen, beispielsweise solche, die nur aus so genannten Stoppwörtern bestehen. Stoppwörter, wie „der“ oder „und“, tragen in der Regel nicht zur Relevanz einer Suche bei, können aber das Query-Processing aus Performance-Sicht vor große Herausforderungen stellen. Die Einbindung neuer Suchmaschinen in den Benchmark ist bewusst einfach gestaltet – es genügt, eine Index-Erstellung und eine Abfrageausführung per Kommandozeile zu implementieren.
Dadurch hat das Benchmark eine breite Kompatibilität und kann die Leistung von Apache Lucene (in zwei Varianten), Tantivy, PISA, Bleve, Rucene und Bluge unter die Lupe nehmen. Apache Lucene ist als Java-Bibliothek ein etablierter Standard im Bereich der Volltextsuche. Es existiert in einer Basisversion, die Dokumente ohne spezielle Ordnung indexiert, und einer optimierten Variante, die mittels Recursive Graph Bisection, einer Methode zur Neuordnung von Dokument-IDs, schnelleres Suchen ermöglicht. Tantivy wiederum stellt eine moderne Rust-Implementierung dar, die in vielen Designaspekten der Lucene-Struktur ähnelt, was Vergleiche äußerst spannend macht. PISA hebt sich durch die kompromisslose Ausrichtung auf maximale Performance hervor und experimentiert mit neuen Verfahren, die potenziell revolutionäre Suchbeschleunigungen ermöglichen.
Die Tatsache, dass PISA und Tantivy teilweise schneller als Lucene agieren, zeigt, dass es trotz der etablierten Position von Lucene weiterhin Spielraum für Verbesserungen gibt. Die Benchmark berücksichtigt unterschiedliche Aspekte, wobei sie sich jedoch bewusst auf schreibgeschützte Datenbestände fokussiert. Das bedeutet, dass die Indizes nach ihrer Erstellung nicht mehr verändert werden, was das Problem vereinfacht und auch realistisch ist, da zahlreiche Anwendungsfälle mit seltenen Updates existieren. Allerdings ist es aus praktischer Sicht nicht unproblematisch, dass Löschungen in den Indizes fehlen, denn diese erschweren Optimierungen wie die Vektorverarbeitung von Abfragen. Ein weiterer Faktor, der die Ergebnisse beeinflusst, ist die verwendete Hardware: Die Tests wurden auf AWS c7i-Instanzen erhoben, die Unterstützung für AVX-512-Befehlssätze bieten.
Dies begünstigt Suchmaschinen, die auf Vektoroperationen und Parallelisierung setzen. Die Benchmark analysiert Abfragen gegen ein einzelnes Feld, was zwar praxisfremd erscheinen mag, da häufig mehrere Dokumentfelder durchsucht werden, aber in Benchmark-Kreisen üblich ist, um klare Vergleichbarkeit zu gewährleisten. Neben den Messungen von durchschnittlichen Latenzen werden auch wichtige Perzentile erfasst, die Rückschlüsse auf die Stabilität und das Verhalten der Suchmaschinen im Bedarfsfall geben. Kaum berücksichtigt wird im Rahmen des Benchmarks jedoch die Größe der erzeugten Indizes oder die Zeit, die für deren Erstellung notwendig ist. So entstehen potenzielle Verzerrungen, denn Techniken wie Recursive Graph Bisection, die massiv Indizierungszeit beanspruchen, können die Suche zwar deutlich beschleunigen, bei der Gesamtperformance aber eine Bremse darstellen.
Die Menge an Daten umfasst rund sechs Millionen Wikipedia-Dokumente, was für viele Echtweltmodelle repräsentativ ist, aber nicht die Herausforderungen eines zehn- oder hundertfach größeren Korpus simuliert. Die ausgewählten Suchanfragen decken ein breites Spektrum an Besonderheiten ab und zeigen, wie unterschiedliche Algorithmen und Optimierungen auf spezielle Problemstellungen reagieren. Dynamische Pruning-Algorithmen, insbesondere WAND (Weak AND) und MAXSCORE, zum Beispiel, sind wesentliche Techniken zur Steigerung der Sucheffizienz bei Top-k-Abfragen – also solchen, die nur die besten Treffer zurückgeben sollen. Während Tantivy und PISA auf block-max WAND setzen, verwendet Lucene block-max MAXSCORE. Beide Ansätze ermöglichen es, Dokumente auszuschließen, die keine Chance haben, unter die Top-Treffer zu gelangen, unterscheiden sich jedoch in der Handhabung der Bewertungsrelationen und der damals notwendigen Optimierungsaufwände.
Eine ganz besondere Herausforderung stellen Suchanfragen dar, die ausschließlich aus Stoppwörtern bestehen. Diese sind problematisch, weil die Begriffe in fast allen Dokumenten vorkommen und daher keinerlei natürliche Gewichtungsdominanz möglich ist, was das Pruning fast unmöglich macht. Interessanterweise sind bei solchen Anfragen Tantivy und PISA sogar langsamer als bei verwandten Top-k-Suchtypen, was darauf hindeutet, dass die vom Pruning erzeugten Overheads die potenziellen Einsparungen übertreffen. Eine ausgeklügelte Optimierung, die besonders Lucene nutzt, ist die Termdeduplizierung. Dabei werden mehrfach vorkommende identische Begriffe in der Anfrage zusammengefasst, sodass die Anzahl der zu durchsuchenden Postinglisten reduziert wird.
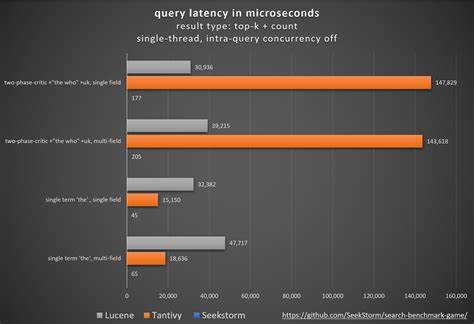
Des Weiteren werfen Anfragen, die sowohl häufige als auch seltene Terme enthalten, Fragen zur Reihenfolge der Auswertung auf. Beispielsweise dauert es bei einer Kombination von „the“ und einem seltenen Begriff wie „incredibles“ oft lange, bis genügend Ergebnisse mit dem seltenen Begriff gefunden werden, damit dynamisches Pruning wirksam greifen kann. Die Anwendung einer frühzeitigen Evaluation der k-ten besten Score wurde von keiner getesteten Suchmaschine implementiert, stellt aber eine vielversprechende Option dar. Besonders spannend sind auch komplexere Queries wie gefilterte Phrasensuchen. Lucene zeigt hier mit seiner Zweiphasen-Auswertung, die zuerst ungefähr prüft, ob eine Phrase vorkommt und erst im Anschluss die genauen Positionen kontrolliert, performante Lösungen.
Solche Verfahrensweisen erlauben es, größere Datenmengen mit deutlich geringerer Latenz zu verarbeiten. Auch längere Suchstrings, etwa ein ganzes Absatzzitat, stellen zunehmende Herausforderungen dar. Mit wachsender Termanzahl wird die Effektivität dynamischer Pruning-Methoden geringer, was die Unterschiede zwischen den Algorithmen wie WAND und MAXSCORE besonders deutlich macht. Ein Highlight im Leistungswettbewerb ist die recursive Graph Bisection, ein Verfahren zur Neuordnung von Dokument-IDs bei PISA, das zu einer höheren Homogenität von Treffer- und Bewertungskonstellationen führt und somit Abfragen stark beschleunigen kann. Diese Idee wurde später auch von Lucene übernommen und zeigt Wirkung im Vergleich der Lucene-Versionen mit und ohne diese Technik.
Tantivy punktet mit einer speziellen Optimierung bei sogenannten COUNT-Abfragen, bei denen nur die Anzahl der Treffer und nicht die einzelnen Treffer selbst ermittelt werden. Hier setzt die Engine auf Bit-Set-Operationen, die eine signifikante Reduktion der Rechenzeit ermöglichen. Lucene hat diese Verbesserung mit Version 9.8 ebenfalls adaptiert. Neuere Entwicklungen bei Lucene umfassen die Kodierung dichter Posting-Abschnitte direkt als Bit-Sets im Index, wodurch das Zusammenführen von Postingslisten erheblich effizienter wird.
Diese Optimierung schlägt sich auch in den Suchzeiten nieder und bietet eine interessante Brücke zur Datenbanktechnik, die Bitmap-Indizes schon lange verwendet. Spannend ist die Beobachtung, dass diese für Suchmaschinen lange vernachlässigten Techniken wohl noch viel ungenutztes Potenzial bergen, was in Zukunft zu weiteren Performance-Sprüngen führen könnte. Abschließend zeigt der Vergleich der Suchmaschinen eindrucksvoll, wie unterschiedlich designentscheidungen Einfluss auf die Suchperformance haben können. Die Mischung von Algorithmen, datenstrukturellen Optimierungen und pragmatischen Vereinfachungen sorgt für ein vielseitiges Ökosystem, in dem es sich lohnt, voneinander zu lernen. Ausbaustufen der Benchmark könnten künftig zusätzliche Szenarien mit Löschungen und komplexeren Filterungen erfassen, um den Praxisanforderungen noch besser gerecht zu werden.
Ebenso spannend wäre die Integration weiterer Systeme wie PostgreSQL Volltextsuche oder Vespa, deren Zugangsweisen gewinnbringende Impulse setzen könnten. Insgesamt macht „Search Benchmark, the Game“ den aktuellen Leistungsstand moderner Suchmaschinen transparent und gibt wertvolle Hinweise darauf, wie die Zukunft der Volltextsuche noch effizienter gestaltet werden kann.