Im Bereich der Künstlichen Intelligenz hat die Entwicklung und Verbesserung großer Sprachmodelle (Large Language Models, LLMs) in den letzten Jahren zu bahnbrechenden Fortschritten geführt. Trotz ihrer beeindruckenden Fähigkeiten stellen große Modelle oft hohe Anforderungen an Speicher, Rechenleistung und Energieverbrauch. Aus diesem Grund gewinnt die Technik der Knowledge Distillation, also der Wissensdestillation, zunehmend an Bedeutung. DistilKitPlus ist eine innovative Open-Source-Toolbox, die speziell dafür entwickelt wurde, die Distillation zwischen beliebigen LLMs praktikabel, effizient und skalierbar zu gestalten. Die Fähigkeit, Wissen zwischen Modellen zu übertragen, ohne ausschließlich auf teure und ressourcenintensive Trainings zu setzen, macht DistilKitPlus zu einer wertvollen Bereicherung für das KI-Ökosystem.
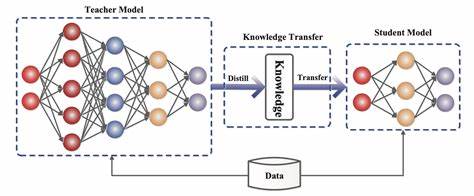
Wissensdestillation ist eine Methode, bei der ein großes, oft komplexes Lehrer-Modell (Teacher Model) sein Wissen an ein kleineres, kompakteres Schüler-Modell (Student Model) überträgt. Ziel ist es, die Leistung und Genauigkeit des Schüler-Modells zu verbessern, während es gleichzeitig leichter und schneller wird. Dies ist besonders wichtig für Anwendungen, die auf Geräten mit begrenzten Ressourcen laufen oder bei denen niedrige Latenzzeiten gefordert sind. Hier setzt DistilKitPlus an und bietet eine umfassende Lösung, die sowohl traditionelle als auch fortgeschrittene Distillationstechniken unterstützt. Eine der herausragenden Eigenschaften von DistilKitPlus ist die Unterstützung von Logit Distillation, bei der die Wahrscheinlichkeitsverteilungen (Logits) des Lehrer-Modells genutzt werden, um das Schüler-Modell anzuleiten.
Das Besondere ist, dass DistilKitPlus sowohl die Distillation mit gleichen als auch mit unterschiedlichen Tokenizern zwischen Lehrer und Schüler ermöglicht. Dies erweitert die Anwendungsmöglichkeiten erheblich, da es nicht mehr nötig ist, auf exakt identische Vokabular- und Tokenisierungsmethoden zu setzen. Gerade beim Zusammenspiel von verschiedenen LLM-Architekturen ist dies ein großer Vorteil. Die Möglichkeit, Logits im Voraus zu berechnen und zu speichern, sorgt für eine erheblich effizientere Nutzung von Arbeitsspeicher und Prozessorzeit während des Trainingsprozesses. Diese Pre-Computed Logits Funktion ist besonders relevant, wenn große Datensätze eingesetzt werden oder die Modelle sehr umfangreich sind.
Dadurch wird DistilKitPlus auch für Projekte mit begrenzten Ressourcen attraktiv, da die Trainingskosten reduziert werden können, ohne die Qualität der Distillation nennenswert einzuschränken. Ein weiteres zukunftsweisendes Feature ist die Integration von LoRA-Finetuning (Low-Rank Adaptation). LoRA ermöglicht es, Modelle mit einer geringeren Anzahl an Parametern feinzujustieren, was den Ressourcenaufwand erheblich senkt, ohne dabei auf signifikante Leistungssteigerungen verzichten zu müssen. Die Kombination von LoRA mit DistilKitPlus schafft somit eine nachhaltige Plattform für das Training und die Anpassung von LLMs in ressourcenarmen Umgebungen, wie sie beispielsweise bei kleineren Forschungsgruppen oder Unternehmen ohne Zugriff auf leistungsstarke Hardware gegeben sind. Zusätzlich unterstützt DistilKitPlus Quantisierung auf 4-Bit-Ebene.
Quantisierung ist eine Technik, bei der die Präzision der Modellparameter reduziert wird, um Speicherplatz und Berechnungen einzusparen. 4-Bit-Quantisierung stellt dabei ein Gleichgewicht zwischen Effizienz und Genauigkeit dar und eignet sich hervorragend für den Einsatz in produktiven Umgebungen mit strengen Hardware-Anforderungen. Die nahtlose Einbindung dieser Quantisierung in DistilKitPlus macht es Entwicklern einfach, performante und ressourcenschonende Modelle zu erstellen. Für die Skalierung und Verteilung von Trainingsprozessen bietet das Framework die Unterstützung von Accelerate und DeepSpeed, beides moderne Technologien zur verteilten und optimierten Modelltrainierung. Durch die Einbindung dieser Tools lässt sich DistilKitPlus in größeren Infrastrukturumgebungen nutzen, wodurch Trainingszeiten spürbar verkürzt und Speicherressourcen besser genutzt werden können.
Dies öffnet die Tür für umfangreiche Experimente mit großen Datensätzen und tiefen Modellen, ohne die Betriebskosten unverhältnismäßig zu erhöhen. Die Vielseitigkeit von DistilKitPlus zeigt sich zudem in den vielfältigen Verlustfunktionen (Loss Functions), die im Training verwendet werden können. Neben der klassischen KL Divergenz für Distillation mit gleichen Tokenizern stehen fortgeschrittene Methoden wie Universal Logit Distillation (ULD) und Multi-Level Optimal Transport (Multi-OT) zur Verfügung. Diese sind insbesondere für Cross-Tokenizer-Distillation geeignet und ermöglichen eine noch präzisere Übertragung von Wissen zwischen unterschiedlich aufgebauten Modellen. Spezielle Anforderungen wie das Vorhandensein von Lehrer-Labels gewährleisten dabei eine optimale Anpassung der Trainingsverfahren an die spezifischen Gegebenheiten der Anwender.
Die Installation und Anwendung von DistilKitPlus ist bewusst einfach gehalten, um eine möglichst breite Nutzerbasis anzusprechen. Über ein konfigurierbares JSON-Format können Nutzer ihre Projekte flexibel anpassen – von der Wahl der Datensätze über die Definition der Modelle und Tokenizer bis hin zu komplexen Trainingseinstellungen. Die Bereitstellung von Beispielkonfigurationen und ausführlichen Tutorials erleichtert den Einstieg und unterstützt Nutzer dabei, schnell produktive Ergebnisse zu erzielen. Darüber hinaus beinhaltet DistilKitPlus eine optionale Integration mit Modal, einem Framework zur einfachen Cloud-Ausführung von KI-Workloads. Dies ermöglicht es Anwendern, Distillation-Jobs bequem in der Cloud laufen zu lassen und somit von skalierbarer Infrastruktur zu profitieren, ohne sich selbst um komplexe Setups kümmern zu müssen.
Das macht DistilKitPlus nicht nur für Einzelanwender, sondern auch für Teams und Unternehmen attraktiv, die in produktiven Umgebungen schnell und flexibel arbeiten möchten. Die Kombination aus ressourcenbewusster Architektur, modularer Flexibilität und modernen Trainingsmethoden macht DistilKitPlus zu einer der vielversprechendsten Open-Source-Initiativen im Bereich der KI-Wissensdistillation. Entwickler können damit auf eine solide Grundlage zurückgreifen, die nicht nur effiziente Modellentwicklung unterstützt, sondern auch eine nachhaltige Nutzung von Rechenressourcen fördert. Für die Zukunft ist mit weiteren Verbesserungen in der Unterstützung neuer Adjustierungstechniken, der Erweiterung der quantitativen Methoden und einer noch engeren Integration mit gängigen KI-Frameworks zu rechnen. Die offene Struktur des Projekts lädt zu aktiver Mitarbeit und gemeinschaftlicher Weiterentwicklung ein, was die Innovationskraft der Plattform zusätzlich steigert.
Zusammenfassend bietet DistilKitPlus eine fortschrittliche, vielseitige und benutzerfreundliche Lösung, die den Prozess der Wissensdistillation zwischen verschiedensten LLMs erheblich vereinfacht und optimiert. Von kleinen Forschungsprojekten bis hin zu anspruchsvollen industriellen Anwendungen stellt das Framework eine zuverlässige Grundlage bereit, um die Leistungsfähigkeit von KI-Modelle effizient zu steigern und gleichzeitig die Kosten und den Ressourcenverbrauch zu minimieren. Somit ist DistilKitPlus ein wichtiger Schritt hin zu intelligenteren, ressourcenschonenden und flexiblen KI-Systemen der nächsten Generation.