Amazon Aurora hat sich als eines der fortschrittlichsten relationalen Datenbanksysteme im Cloud-Umfeld etabliert. Es bietet eine vollständig kompatible Umgebung mit MySQL- und PostgreSQL-Datenbanken und richtet sich an Unternehmen, die hohe Leistung, Zuverlässigkeit und globale Skalierbarkeit benötigen. Die Preisgestaltung von Amazon Aurora spielt dabei eine zentrale Rolle, denn sie gibt Unternehmen die Flexibilität, Kosten bedarfsgerecht zu steuern und gleichzeitig optimale Performance sicherzustellen. Die Kombination aus innovativen Technologien und intelligentem Preismodell macht Aurora sowohl für Start-ups als auch für Großunternehmen attraktiv. Die Preisstruktur von Amazon Aurora basiert im Wesentlichen auf drei Hauptfaktoren: den Kosten für die Datenbank-Instanzen, dem Speicherverbrauch sowie den Ein- und Ausgabeoperationen (I/O).
Darüber hinaus gibt es optionale Leistungsmerkmale und Zusatzfunktionen, die individuell aktiviert und abgerechnet werden können. Dieses System ermöglicht es Nutzern, ihre Datenbank-Umgebung exakt an ihre Anforderungen anzupassen und nur für tatsächlich genutzte Ressourcen zu bezahlen. Ob On-Demand oder mit Reservierungen – die verschiedenen Preisoptionen unterstützen ein breites Spektrum an Anwendungsfällen. Ein entscheidender Punkt in der Aurora-Pricing-Strategie ist die Cluster-Konfiguration. Amazon Aurora bietet die Wahl zwischen der Standardkonfiguration und der I/O-optimierten Variante.
Die Standardkonfiguration eignet sich für Anwendungen mit eher moderaten bis typischen Zugriffsmustern, bei denen Kostenkontrolle im Vordergrund steht. Die Abrechnung erfolgt hier nach genutzter Datenbankinstanz, Speicher sowie der Anzahl der Lese- und Schreiboperationen. Diese Variante stellt für viele Nutzer eine kostengünstige Lösung dar, die dennoch solide Leistung liefert. Demgegenüber steht die I/O-optimierte Konfiguration, die speziell für I/O-intensive Workloads entwickelt wurde. In diesem Modell entfallen zusätzliche Gebühren für Lese- und Schreiboperationen, was besonders bei Anwendungen mit hohem Datenverkehr und intensiver Nutzung von Speicherressourcen zu erheblichen Kosteneinsparungen führen kann.
Amazon nennt hierbei Einsparungen von bis zu 40 Prozent gegenüber der Standardkonfiguration als Richtwert. Die I/O-optimierte Variante ist daher ideal für anspruchsvolle Workloads, Netzwerkdatenbanken oder Echtzeitanalysen, wo eine konstante und vorhersehbare Kostenstruktur gewünscht wird. Amazon Aurora bietet zudem Serverless-Optionen an – insbesondere Aurora Serverless v2 – die eine automatische Skalierung der Datenbankkapazität je nach Last ermöglichen. Das bedeutet, dass die Datenbank nicht dauerhaft mit hoher Kapazität läuft, sondern nur die tatsächlich benötigten Ressourcen nutzt. Diese Flexibilität senkt nicht nur die Betriebskosten erheblich, sondern reduziert auch den Verwaltungsaufwand, da sich Entwickelnde und Administratoren weniger um die Skalierung kümmern müssen.
Die Abrechnung erfolgt hierbei auf Basis von Aurora Capacity Units (ACUs), die pro Sekunde berechnet werden. Aurora Serverless v2 kann in sehr feinen Kapazitätsschritten skalieren, sodass auch kleine Lastspitzen effizient bedient werden können. Für Datenbankinstanzen steht bei Aurora die Wahl zwischen On-Demand-Instanzen und Reserved Instances offen. Während On-Demand eine maximale Flexibilität ohne langfristige Bindungen bietet, können Reserved Instances durch Vorauszahlung und längere Nutzung verpflichtende Kostenvorteile liefern. Insbesondere Unternehmen mit planbaren und kontinuierlich hohen Lasten profitieren durch Reserved Instances von günstigeren Stundenpreisen.
Dabei gibt es auch die Möglichkeit, Reserved Instances flexibel zu verwalten und hinsichtlich Größe oder Region anzupassen, damit Ressourcen optimal genutzt werden können. Neben der technischen Infrastruktur beeinflussen auch Storage und I/O die Gesamtkosten maßgeblich. Aurora speichert Daten redundant über mehrere Verfügbarkeitszonen hinweg, um Ausfallsicherheit zu gewährleisten. Die Speicherkosten werden nach verbrauchtem Volumen in Gigabyte pro Monat berechnet. Bei der Standardkonfiguration kommen zusätzlich Kosten für jede Million Lese- und Schreiboperationen hinzu, wohingegen bei der I/O-optimierten Konfiguration diese I/O-Kosten entfallen.
Das flexible automatische Skalieren von Speicher und I/O garantiert, dass Nutzer nicht zu viel vorab investieren müssen und keine Ressourcen ungenutzt bleiben. Ergänzend zu diesen Kernkomponenten gibt es weitere Kostenpunkte, die Unternehmen berücksichtigen sollten. Beispielsweise fallen Gebühren für die Nutzung von Backup-Speicher an, sofern automatisierte Backups über das kostenlose Freikontingent hinausgehen. Backtrack ist eine weitere hilfreiche Funktion, sie ermöglicht es, die Datenbank schnell zu einem früheren Zustand zurückzusetzen, um beispielsweise versehentlich gelöschte Daten wiederherzustellen. Auch hierfür entstehen Kosten, die abhängig von der Speichermenge der Änderungsprotokolle berechnet werden.
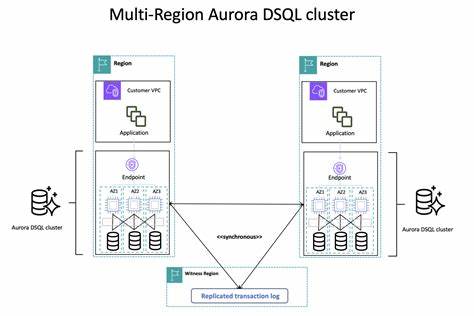
Für Entwickler, die den Zugriff auf Aurora-Datenbanken via API bevorzugen, bietet Amazon den Data API-Service. Dieser vereinfacht SQL-Abfragen über HTTPS, ohne dass eine direkte Verbindung zum Datenbankcluster erforderlich ist. Die Abrechnung erfolgt hier nach der Anzahl der API-Anfragen und der Größe der Datenübertragung. Ein attraktives Einstiegskontingent sorgt dafür, dass vor allem kleinere Anwendungen oder Entwicklungsprojekte das Data API kostenfrei oder kostengünstig nutzen können. Die Nutzung von Amazon Aurora als Global Database über mehrere AWS-Regionen hinweg ist optimal für globale Anwendungen mit hohen Anforderungen an Verfügbarkeit und Latenz.
Für diese Szenarien entstehen zusätzliche Kosten für die Replikation von Schreibvorgängen zwischen Regionen sowie für den Datenverkehr über Regionen hinweg. Allerdings profitieren Unternehmen auch dadurch von einer hohen Ausfallsicherheit sowie schnellen regionalen Datenzugriffen. Aus Sicht der Optimierung von Kosten und Performance sind einige Highlights hervorzuheben. Beispielsweise ermöglichen Optimized Reads für die PostgreSQL-Edition verbesserte Leseleistung durch NVMe-SSD-basierten lokalen Cache. Dies reduziert die Latenz bei großen Datenmengen und kann gleichzeitig für Kosteneinsparungen sorgen, weil weniger teure I/O-Operationen genutzt werden müssen.
Die Möglichkeiten, temporäre Objekte lokal abzulegen, verbessern zudem datenintensive Operationen wie Sortierungen oder Join-Abfragen. In der Praxis sind die Kosteneinsparungen und Vorteile einer passenden Aurora-Konfiguration erheblich. Kunden, die ihre Aurora-Workloads strategisch planen und die geeignete Kombination aus Standard- oder I/O-optimierter Cluster-Konfiguration und Serverless oder Provisioned Instances wählen, können ihre Betriebskosten optimieren und gleichzeitig eine hohe Skalierbarkeit und Performance gewährleisten. Eine genaue Analyse des eigenen Workloads in Bezug auf Datenzugriffe und I/O-Intensität lohnt sich daher vor der Entscheidung. Darüber hinaus bietet die AWS-Umgebung zahlreiche Tools wie den AWS Pricing Calculator, mit denen sich die Aurora-Kosten vorab simulieren und an das eigene Nutzungsszenario anpassen lassen.