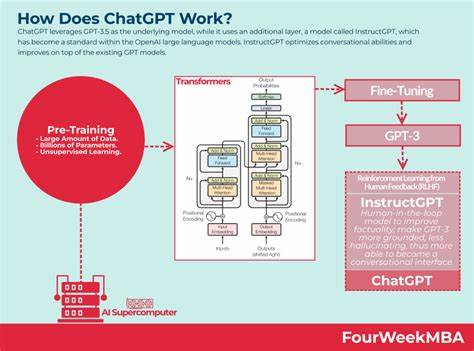
Hacker News ist seit Jahren eine der wichtigsten Plattformen für Entwickler, Unternehmer und Technologen, um sich auszutauschen, neues Wissen zu teilen und heiße Diskussionen zu führen. Angesichts der Größe und Relevanz dieser Community stellt sich die Frage, ob große Sprachmodelle wie ChatGPT tatsächlich auf diese wertvollen Daten zugreifen und sie in ihr Training einfließen lassen. Die Antwort darauf ist nicht nur spannend in Bezug auf die Leistungsfähigkeit von KI-Modellen, sondern auch wichtig hinsichtlich ethischer und rechtlicher Aspekte. Zunächst sei festgehalten, dass OpenAI keine vollständige öffentliche Liste der spezifischen Datenquellen veröffentlicht hat, die beim Training von Modellen wie ChatGPT genutzt wurden. Allerdings ist bekannt, dass die Trainingsdaten aus einer Vielzahl von öffentlich zugänglichen Textquellen bestehen, darunter auch Internetforen, Websites, wissenschaftliche Publikationen und Code-Repositorien.
Hacker News, als Teil des öffentlichen Internets, könnte demnach potenziell unter diesen Quellen sein. Einige Nutzer innerhalb der Hacker News Community haben versucht, ChatGPT mit konkreten Fragen zu zitaten oder Inhalten aus der Plattform zu testen. Beispielsweise wurde der Bot aufgefordert, bestimmte Kommentare zu identifizieren oder deren Verfasser zu benennen, die auf Hacker News gepostet wurden. Die dabei erzielten Ergebnisse sind interessant: ChatGPT zeigte sich zwar mit allgemeineren Themen und häufig diskutierten Inhalten vertraut, aber oft ohne den genauen Urheber oder das exakte Zitat zu nennen. Das deutet darauf hin, dass das Modell wahrscheinlich Trainingsdaten enthält, die aus Hacker News inspiriert sind oder ähnliche Diskussionen wiedergeben, allerdings nicht im Sinne einer akkuraten Nachbildung einzelner Kommentare.
Es gibt sogar Hinweise in der Community, dass ChatGPT über ein Grundverständnis der Dynamiken von Hacker News verfügt. Diskussionen zu Technologie, Programmierung, Startups und ähnlichen Themen werden in Hacker News oft thematisiert, und viele dieser Themen finden sich auch in Textquellen, die KI-Modelle trainieren. Dies erlaubt ChatGPT, mit einer gewissen Vertrautheit zu antworten, ohne dabei spezifische Details preiszugeben, die auf eine vollständige Datennutzung und Speicherung zurückzuführen wären. Darüber hinaus werfen einige Nutzer ethische und rechtliche Fragen auf, wenn es darum geht, ob und in welchem Umfang Daten von Websites wie Hacker News für Trainingszwecke verwendet werden dürfen. Während die meisten Inhalte öffentlich zugänglich sind, variieren die Nutzungsbedingungen und Lizenzen.
Im Fall von Hacker News liegt der Fokus auf dem offenen Diskurs, aber es gibt keine ausdrückliche Erlaubnis, Kommentare automatisiert zu sammeln und in eigenen Produkten zu nutzen. Die Datenschutzbestimmungen und die Zustimmung der Nutzer sind daher zentrale Aspekte, die momentan noch diskutiert werden. Ebenfalls interessant ist die Diskussion um die technische Machbarkeit und den Umfang einer solchen Datennutzung. Hacker News verfügt über umfangreiche APIs und eine offene Infrastruktur, die den Zugriff auf kommentierte Beiträge ermöglicht. Dieses Datenvolumen ist jedoch nur ein Bruchteil der Gesamtmenge an Trainingsdaten, die ein Modell wie ChatGPT benötigt.
Daher ist es plausibel, dass Hacker News Kommentare als ergänzender Baustein in einem großen Datensatz verwendet werden, ohne dass sie das Training dominieren. Aus einer praktischen Perspektive profitiert ChatGPT natürlich von der inhaltlichen Diversität, die durch die Integration unterschiedlichster Quellen entsteht. Hacker News als technikfokussierte Community liefert komplexe Diskussionen zu den neuesten Trends und Herausforderungen in der Softwareentwicklung, KI und Startups – also genau den Themen, bei denen das Sprachmodell glänzen soll. Die Einbindung solcher Inhalte in das Training trägt dazu bei, dass ChatGPT überzeugende und fundierte Antworten liefern kann. Für Nutzer von ChatGPT bedeutet dies: Wenn Sie spezifische Informationen oder Zitate aus Hacker News suchen, kann das KI-Modell möglicherweise eine hilfreiche Orientierung bieten, ohne jedoch die Plattform vollständig zu ersetzen oder alle Details exakt wiederzugeben.
Die Antworten sind in der Regel verallgemeinert und basieren auf Mustern, die das Modell gelernt hat, anstatt auf einer direkten Wiedergabe von Texten aus der Community. Insgesamt lässt sich sagen, dass die Integration von Hacker News Kommentaren in das Training von ChatGPT wahrscheinlich ist, allerdings nicht als Einzelquelle im Vordergrund steht. Die Kombination aus zahlreichen Quellen ermöglicht dem Modell eine enorm breite Wissensbasis, in der Hacker News als wichtiger Vertreter technikaffiner Inhalte einen Platz einnimmt. Gleichzeitig sorgt die Anonymisierung und das Generalisieren der Daten dafür, dass spezifische Beiträge oder Meinungen nicht direkt extrahiert werden können. Zukunftsperspektivisch wird die Frage nach Quellen und Datenrecht weiter an Bedeutung gewinnen.