In der heutigen Zeit, in der Datenmengen rasant wachsen und hochperformante Rechenoperationen alltäglich sind, gewinnt die effiziente Sortierung von Daten immer mehr an Bedeutung. Besonders in der GPU-Programmierung eröffnen sich spannende Möglichkeiten, um konventionelle Algorithmen mittels Parallelisierung und moderner Hardware-Instruktionen erheblich zu beschleunigen. Ein herausragendes Beispiel dafür ist der Einsatz von SIMD CUDA Intrinsics, die die Sortierung auf der GPU zu einem wahren Performance-Wunder machen. Um diesen Ansatz besser zu verstehen, lohnt sich ein Blick auf den Bitonic Sort, einen Parallel-Sortieralgorithmus, der sich besonders gut für eine Umsetzung mit diesem Hardwarekonzept eignet. Bitonic Sort ist ein spezieller Vertreter der Familie der Sortiernetzwerke.
Diese Netzwerke bestehen aus einer festgelegten Anzahl von Vergleichs- und Tauschoperationen, die parallel ausgeführt werden können. Das besondere an Bitonic Sort ist, dass er Daten in bitonischen Sequenzen sortiert. Eine bitonische Sequenz ist dabei eine Folge von Elementen, die aus zwei monotonen, also entweder auf- oder absteigenden, Teilsequenzen besteht. Das bedeutet, eine Sequenz kann beispielsweise zuerst steigen und danach fallen. Das klingt im ersten Moment ungewöhnlich, erlaubt aber die Rekonstruktion eines effizienten parallelen Sortierverfahrens, das sich ideal für SIMD-Architekturen eignet.
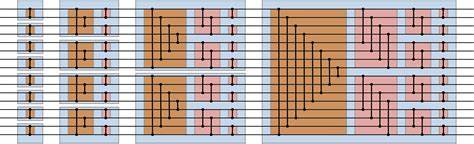
Der Clou bei Bitonic Sort liegt in seiner parallelen Ausführung. Die Laufzeitkomplexität in einer sequenziellen Welt erscheint mit O(n log² n) höher als die bekannten Vergleichssortieralgorithmen mit O(n log n). Doch da Bitonic Sort seine Arbeit massiv parallelisiert, entspricht die Laufzeit in der Parallelwelt eher O(log² n). Hierbei spielt die hierarchische Struktur der GPU eine zentrale Rolle. Moderne Grafikkarten wie NVIDIAs RTX-Serien bieten mit ihren Tausenden von Kernen ausgestattet massive Parallelisierungsmöglichkeiten.
Insbesondere der sogenannte Warp – eine Einheit von 32 Threads, die synchron ausgeführt werden – bildet die Basis für effiziente SIMD-ähnliche Operationen. SIMD, Single Instruction Multiple Data, ist ein Programmier- und Hardwarekonzept, bei dem mehrere Datenpunkte gleichzeitig mit derselben Operation bearbeitet werden. Dies ist besonders sinnvoll bei auf Datenparallelismus ausgelegten Algorithmen wie Sortiernetzwerken. Während der Begriff SIMD ursprünglich von CPU-Technologien wie AVX oder NEON stammt, lässt sich das Prinzip mit CUDA-Warp-Intrinsics auf der GPU nahtlos umsetzen. Jeder Warp kann als 32-längiger Vektor von Daten verstanden werden, wobei die einzelnen Lanes im Warp parallel die gleiche Instruktion ausführen, jedoch auf unterschiedlichen Daten.
Ein wesentliches Werkzeug bei der Realisierung ist die CUDA-interne Funktion __shfl_sync. Mit ihr können Werte direkt zwischen den Registern der einzelnen Threads eines Warps ausgetauscht werden, ohne den Umweg über den langsamen Shared Memory oder gar globalen Speicher gehen zu müssen. Dies erzeugt nicht nur beschleunigte Datenbewegungen, sondern verringert auch die notwendigen Synchronisationsaufrufe, was das Gesamtsystem spürbar entlastet. Die Warps können sich somit innerhalb eines Takts gegenseitig Werte tauschen und miteinander vergleichen, was den Kern des Bitonic Sort bildet. Praktisch betrachtet wird bei der Umsetzung in CUDA jedes Thread eines Warps mit einem einzelnen Element des zu sortierenden 32-Element Vektors belegt.
Mithilfe des __shfl_sync Befehls werden dann untereinander Elemente für Vergleichsoperationen getauscht und entsprechend sortiert. Dabei agiert das Bitonic Sort Netzwerk als feste Abfolge von Vergleichs- und Tauschapplikationen, welche die ursprünglich unsortierten Daten schrittweise in einen vollständig sortierten Vektor transformieren. Dank des direkten Registerzugriffs über __shfl_sync lässt sich dieser Prozess erheblich beschleunigen gegenüber Implementierungen, die auf Shared Memory und manuelle Synchronisationen setzen. In Performance-Tests konnte dieser optimierte Ansatz gegenüber klassischen Shared Memory-basierten Sortierungen eine Leistungssteigerung von bis zu 30 % erzielen. Besonders auf leistungsfähigen GPUs wie einer NVIDIA RTX 3090 zeigte sich deutliche Beschleunigung.
Der Aufwand für das Verwalten von gemeinsamem Speicher entfällt nahezu komplett, was bei steigender Datenmenge und Taktzahl ein entscheidender Vorteil ist. Gleichzeitig bleibt der Algorithmus durch seine deterministische Struktur gut vorhersagbar und stabil in seiner Performance. Die Bedeutung der Bitonic Sort Implementierung mit Warp-Intrinsics liegt jedoch nicht nur in der Beschleunigung kleinerer Sortiersegmente. Moderne Sortierverfahren auf der GPU basieren häufig auf Kombinationen verschiedener Algorithmen, um große Datenmengen optimal zu verarbeiten. Insbesondere hybriden Varianten aus Merge- und Bitonic-Sort kommen zum Einsatz.
Hier dient der Bitonic Sort als Basisfall für das Sortieren von 32-Element Blöcken, bevor diese in weiteren Schritten zu größeren Teillisten zusammengeführt werden. Ein weiterer spannender Anwendungsfall liegt in der 32-Wege-Menge von sortierten Listen, die als nächster Optimierungsschritt betrachtet wird. Die Frage dabei ist, ob das Prinzip des Bitonic Sort und die performante Datenbewegung via __shfl_sync auch dazu genutzt werden können, um effizient mehrere sortierte Sublisten zusammenzuführen. Obwohl dies noch in der Forschung und Entwicklung steckt, eröffnet dieser Ansatz interessante Perspektiven, insbesondere hinsichtlich der weiteren Beschleunigung des Merge-Schritts. Ein historisch interessanter Vergleich zeigt, dass das Konzept des Bitonic Sorts alles andere als neu ist.
Es wurde bereits seit den 1960er Jahren als theoretisches Modell für Parallel-Sortierungen erforscht. In modernen GPUs hat seine Umsetzung erstmals praktische Relevanz erhalten, da die Architektur von Warps und die Verfügbarkeit hochwertiger atomares Datenaustausch gleichzeitig die benötigte Infrastruktur liefern. Die Kombination aus bewährten Algorithmen und brandneuen Hardwarefeatures führt so zu einer neuen Generation performanter Sortieralgorithmen. Drei Charakteristika machen die Nutzung von SIMD CUDA Intrinsics besonders attraktiv für das Sortieren: niedrige Latenzen durch Registerzugriff, gleichzeitig hohe Parallelität durch Warps und der Verzicht auf teure Synchronisationsmechanismen. Die explizite Verwendung von __shfl_sync als primitives Kommunikationselement im Warp zeigt, wie wichtig es ist, die Hardwarefunktionalität optimal auszunutzen, um das Maximum an Performance herauszuholen.
Die Programmierung solcher Sortieralgorithmen stellt jedoch auch hohe Anforderungen an den Entwickler. Neben einem tiefen Verständnis der CUDA-Architektur sind sorgfältige Überlegungen zur Speicherverwaltung und Synchronisation unabdingbar. Die enge Verzahnung von Algorithmuslogik und hardwarenaher Optimierung erfordert ein hohes Maß an Expertise und die Fähigkeit, paralelle Abläufe effizient zu orchestrieren. Abschließend lässt sich festhalten, dass der Einsatz von SIMD CUDA Intrinsics, insbesondere durch den Einsatz von __shfl_sync zur Umsetzung von Bitonic Sort Algorithmen, einen vielversprechenden Weg darstellt, GPUs noch effizienter für Sortieraufgaben zu nutzen. Die daraus resultierende Performancesteigerung kann nicht nur die Sortierzeiten drastisch reduzieren, sondern stellt auch eine wichtige Grundlage dar, um komplexe Sortierprozeduren weiter zu optimieren.
Zukünftige Forschungsarbeiten und praktische Implementierungen werden sich sicherlich weiter mit der Frage beschäftigen, wie man neben der Sortierung auch das Mischen und Zusammenführen von Daten noch besser beschleunigen kann. Die Kombination aus tiefgreifender Algorithmusinnovation und moderner GPU-Technologie dürfte hier weiterhin zu beeindruckenden Ergebnissen führen. Wer Hochleistungssortierung benötigt, sollte daher den Blick auf die Nutzung von Warp-Level SIMD Intrinsics nicht verlieren. Damit lassen sich viele Anwendungen in Bereichen wie Big Data, Echtzeitanalyse oder maschinellem Lernen effizienter gestalten und auf ein neues Leistungsniveau heben.