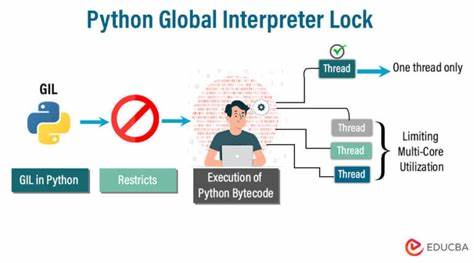
Python ist eine der beliebtesten Programmiersprachen weltweit, doch ihre Verwendung in Multithreading-Szenarien stößt häufig auf ein bekanntes Problem: den Global Interpreter Lock, kurz GIL. Dieser sorgt dafür, dass zwar mehrere Threads existieren können, aber nur einer zur gleichen Zeit Python-Code ausführen darf. Das stellt eine Herausforderung dar, wenn man in einem einzigen Prozess mehrere Python-Interpreter parallel betreiben möchte, insbesondere bei Robotik- und Steuerungssoftware, die auf Performance angewiesen ist. Vor der Veröffentlichung von Python 3.12 war diese Herausforderung untrennbar mit dem GIL verbunden und stellte Entwickler vor erhebliche Probleme.
Doch es gibt bemerkenswerte technische Ansätze und Umgehungslösungen, die zeigen, dass man auch mit älteren Python-Versionen mehrere Interpreter in einem Prozess ohne GIL-Contention nutzen kann. Basis, ein innovatives Framework für Robotersoftware, ist ein Beispiel für solche Entwicklungen. Das GIL-Problem ist bekannt: Python erlaubt zwar Multithreading, aber der GIL verhindert, dass mehrere Threads gleichzeitig nativen Python-Bytecode ausführen. Dies führt schnell zu Engpässen bei parallelen CPU-intensiven Aufgaben. Besonders problematisch ist es, wenn man Subinterpreters einsetzen möchte.
Diese wurden eingeführt, um mehrere unabhängige Python-Umgebungen im selben Prozess zu erlauben, teilen sich aber dennoch den GIL. Somit verhindert der GIL effektives paralleles Ausführen in einem einzigen Prozess mit mehreren Interpreter-Instanzen. Die Architektur von Basis verfolgt einen anderen Ansatz. Anstatt verschiedene Prozesse durch Shared-Memory-Segmente zu verbinden, lädt Basis alles in denselben Speicherraum und teilt Objekte via smart pointers. Das reduziert Overhead durch Interprozesskommunikation und ermöglicht nahezu zero-copy-Kommunikation.
In der Praxis bedeutet das eine verbesserte Performance für komplexe Robotiksoftware, die mehrere Pipelines parallel ausführt – wie Wahrnehmung, Planung und Steuerung – alles innerhalb eines einzigen Prozesses. Die Herausforderung war, wie mehrere Python-Interpreter in diesem Modell gestartet werden können, ohne dass sie sich gegenseitig blockieren oder crashen. Per Standard verhält sich Python so, dass Py_Initialize nur einmal pro Prozess aufgerufen werden kann. Versucht man, es zweimal zu initialisieren, kommt es zum Abbruch mit Fehlermeldung. Subinterpreters via Py_NewInterpreter schaffen zwar neue Umgebungen, teilen aber den GIL, was die ursprüngliche Problematik nicht löst.
Die erste Inspiration zur Lösung kam aus dem Linux-Werkzeugkasten, genauer gesagt aus dem dynamischen Laden von Bibliotheken. Normalerweise nutzt man dlopen, um shared objects (.so-Dateien) zu laden. Dabei bekommt man aber stets denselben Namespace. Mehrere dlopen-Aufrufe laden dieselbe Bibliothek nicht neu, sondern liefern denselben Handle zurück.
Das bedeutet auch, dass die Python-Bibliothek nicht mehrfach unabhängig geladen werden kann. Ein möglicher Workaround wäre, Kopien der Library umzubenennen und separat zu laden, aber das ist wenig praktikabel und führt zu komplexen Abhängigkeitsproblemen. Der entscheidende Durchbruch erfolgte durch den Einsatz von dlmopen, einer Technik, die Linux-spezifisch ist. dlmopen erlaubt es, Bibliotheken in separaten Link-Namespaces zu laden. Mit LM_ID_NEWLM als Namespace-Parameter kann jede Python-Interpreter-Instanz ihre eigene, isolierte Version der Python-Laufzeit erhalten, unabhängig von anderen im selben Prozess.
Das Wichtigste dabei: keine symbolischen Überschneidungen und keine unerwünschte gemeinsame Nutzung von globalem Zustand. Das Ergebnis war beeindruckend: Mehrere Units, die Python-Interpreter enthalten, konnten parallel gestartet werden. Jeder Interpreter agierte unabhängig mit seiner eigenen Initialisierung, und die bekannte Absturzproblematik durch Mehrfachinitialisierungen löste sich auf. Dies war ein wichtiger Schritt dahin, mehrere Interpreter innerhalb eines einzigen Prozess-Images sinnvoll einzusetzen. Allerdings stellte sich bald heraus, dass dies noch nicht die ideale Lösung war.
Zum Beispiel ist das Teilen von Komponenten wie statischen Variablen, die Basis für Kommunikation oder Logging nutzen, schwierig. Statische Variablen werden pro Namespace isoliert, was Integrationsprobleme verursacht. Ebenso bleiben Probleme mit Thread-Lokalen bestehen, da jede Namespace-Version von glibc und deren Thread-Lokalen unterschiedlich agiert. Besonders auffällig wurde dieser Effekt, als Python-Threads in verschiedenen Interpretern außerhalb des Hauptthreads gestartet werden sollten. Dabei trat neues, hartnäckiges Fehlverhalten auf, das die Implementierung infrage stellte.
Nach intensiver Fehlersuche zeigt sich der Kern des Problems in der glibc-Integration: Python nutzt intensiv Thread-Lokale Speicher (TLS) für interne Zustände und Synchronisation. Wird glibc mehrfach separat geladen, gibt es unterschiedliche TLS-Bereiche, die nicht miteinander kompatibel sind. Dies führt zu Inkonsistenzen und Abstürzen, die sich kaum debuggen lassen. Der Lösungsansatz bestand darin, eine Art Shim zu programmieren, der bestimmte pthread-Funktionen von der Haupt- bzw. Baseline-Namespace in die neue Python-Instanz durchreicht.
Konkret wurde eine Struktur mit Funktionzeigern erstellt, die auf die Original-pthread-Funktionen zeigen. Diese werden dann in der isolierten Namespace implementiert, sodass alle Thread-bezogenen Operationen über die einzig gültige glibc-Schnittstelle laufen. So wird thread-lokaler Zustand konsistent gehalten und das Mehrfach-Interpreter-Modell funktioniert auch mit Threads. Diese Technik ist allerdings komplex und erfordert tiefes Verständnis von Linux-Dynamik, Threading und C++-Symbolmanagement. Beispielhaft dafür sind Makros, die in Headern Funktionszeiger definieren, und im Konstruktor mit dlsym gefüllt werden.
Damit lassen sich Python-APIs nahtlos shimen, ohne dass die eigentliche Python-Binary oder pybind11 direkt gelinkt oder mehrfach geladen wird. Ein weiteres technisches Detail betrifft die Verwendung von Lokalisation (Locale). C- und C++-Funktionen wie islower oder ähnliche Verhaltensweisen hängen vom eingestellten Locale ab. Dieses kann ebenfalls thread-lokal sein und sorgt mitunter für Abstürze bei Python-Modulen wie numpy, wenn die Locale unterschiedlich oder inkonsistent pro Thread gesetzt ist. Die Lösung war, thread-lokale Locale-Varianten zu ersetzen oder global konsistent zu initialisieren.
Dieses Vorgehen ist nicht nur akademisch interessant, sondern hat praktische Auswirkungen für Softwareentwicklung im Robotik-Kontext. Hier ist Performance und Ressourcenoptimierung entscheidend, und mehrere Python-Interpreter in nur einem Prozess eröffnen neue Möglichkeiten bei der Parallelisierung von Steuerungs- und Wahrnehmungsalgorithmen. Ein weiterer Vorteil ist, dass sich mit dlmopen-Namespaces gewisse Isolationsgrad zwischen Erweiterungen oder Modulen erzielen lässt, was klassische Shared-Memory-Segmente überflüssig macht und potentiell Komplexität reduziert. Gleichzeitig sollte man sich der Grenzen bewusst sein. Linux und glibc begrenzen die Anzahl der verfügbaren Link-Namespaces auf etwa 16, was nur ca.
15 separate Python-Interpreter erlaubt. Erweiterungen darüber hinaus sind möglich, bedürfen aber tiefer Eingriffe in die Systembibliothek, die nicht trivial sind und die Systemstabilität gefährden können. Außerdem bringt das manuelle Management von Thread-Lokalen, Shims und lokalen Funktionstöpfen einen erheblichen Wartungsaufwand mit sich. Fehler sind komplex und schwer nachvollziehbar. Während dieser experimentelle Ansatz vor allem vor Python 3.
12 relevant war, zeigen die Entwicklungen im aktuellen Python, dass Subinterpreters mit eigenem GIL ab Version 3.12 viele Probleme lösen. Das macht diesen Aufwand für neue Projekte unnötig. Doch in der Praxis halten sich viele Robotikprojekte und Pipelines noch auf älteren Python-Versionen auf, da zahlreiche Abhängigkeiten und Drittbibliotheken nicht zeitnah aktualisiert werden. Basis hat sich inzwischen entschlossen, auf Python 3.
12 mit modernisierten Subinterpreters zu setzen. Diese modernere Lösung ermöglicht echte Parallelität dank unabhängiger GILs, während die Kompatibilität mit rospy und anderen Robotik-Nachrichten durch einfache PYTHONPATH-Konfigurationen erleichtert wird. Dennoch sind die Erfahrungen mit dlmopen und Namespace-Shimming weiterhin wertvoll, etwa für Legacy-Systeme oder andere Szenarien, in denen Isolation innerhalb eines Prozesses erforderlich ist. Neben den technischen Herausforderungen zeugen auch Debugging-Erfahrungen von den Schwierigkeiten beim Einsatz von dlmopen. So unterstützen Debugger wie lldb standardmäßig keine symbolischen Stack-Traces für Module, die in eigenen Link-Namespaces geladen wurden.
Man muss daher per Scripts selber die Basisadresse aus /proc nehmen und die Module manuell „sliden“, um lesbare Call-Stacks zu erhalten. GDB unterstützt das im Gegensatz dazu seit Version 13.1 schon automatisch. Solche Details sind wichtig, damit Entwickler später Bugs finden und verstehen können. Abschließend zeigt sich: Mehrere Python-Interpreter in einem Prozess ohne GIL-Contention vor Python 3.
12 sind technisch möglich, aber komplex und mit vielen Hürden verbunden. Der Einsatz von dlmopen und Namespace-Shimming stellt einen mutigen und originellen Weg dar, der sowohl starkes Linux-Know-how als auch gründliches Verständnis der Python-Internals und glibc erfordert. Für Entwickler im Bereich Robotik und Performance-kritischer Applikationen kann dieser Ansatz eine spannende Option sein, besonders wenn ein Upgrade auf neuesten Python-Versionen nicht möglich ist. Langfristig empfehlen sich jedoch moderne Python-Feature-Sets, die native Lösungen anbieten. Die Erfahrungen aus dieser Arbeit können darüber hinaus für die allgemeine Softwareentwicklung lehrreich sein, wenn es um die Isolierung von Modulen, Plugin-Architekturen und das Management von gemeinsam genutzten Ressourcen in großen Anwendungen geht.
Sie zeigen eindrucksvoll, wie vielschichtig und herausfordernd Multithreading in interpretierten Sprachen ist und wie viel Kreativität und tiefes Systemverständnis notwendig sind, um performante und stabile Mehrfach-Interpreter-Systeme zu realisieren.