Im digitalen Zeitalter, in dem Millionen von Nutzern kontinuierlich auf Webanwendungen zugreifen, ist eine stabile und effiziente Infrastruktur unerlässlich. Gerade bei Anwendungen mit hohem Verkehrsaufkommen spielen Load Balancer eine entscheidende Rolle. Sie sorgen dafür, dass die Anfragen gleichmäßig auf verschiedene Server verteilt werden, wodurch Auslastungsspitzen abgefedert und Systemausfälle vermieden werden. In diesem Kontext klingt die Idee, einen voll funktionsfähigen Load Balancer in gerade einmal 250 Zeilen Code zu entwickeln, beinahe zu schön, um wahr zu sein. Doch mit klarer Architektur, dem richtigen Verständnis und etwas Programmiergeschick ist genau das möglich – und zwar auf effektive und erweiterbare Weise.
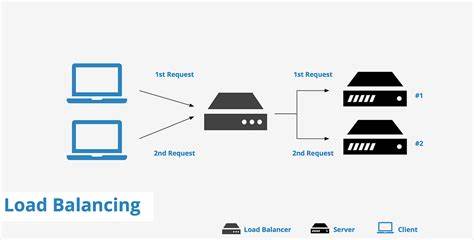
Zunächst stellt sich die grundsätzliche Frage: Was ist ein Load Balancer eigentlich und warum ist er so wichtig? Vereinfacht gesagt ist es eine Komponente, die den eingehenden Datenverkehr annimmt und ihn auf mehrere Server verteilt. Dies ist besonders bei Anwendungen wichtig, die horizontal skaliert werden sollen, also über mehrere Instanzen laufen, um mehr Nutzer gleichzeitig bedienen zu können. Ohne Lastverteilung würde ein einzelner Server sämtliche Anfragen verarbeiten müssen, was schnell zu Überlastungen und Ausfällen führt. Um das Prinzip der Lastverteilung zu verstehen, hilft ein Blick auf konkrete Zahlen. Eine Anwendung, die beispielsweise eine Million Anfragen pro Sekunde erhält, müsste diese enorme Last auf mindestens einen Server stemmen.
Dies ist weder effizient noch zuverlässig, da der Server schnell an seine Leistungsgrenzen stoßen könnte. Werden jedoch mehrere Instanzen eingesetzt, beispielsweise fünf, so verteilt sich die Last auf jeden Server. Jeder Server verarbeitet dann nur 200.000 Anfragen pro Sekunde, was die Belastung reduziert und die Zuverlässigkeit deutlich steigert. Diese Beispiele zeigen, warum Load Balancer in modernen Systemen unverzichtbar sind.
Die Verteilung der Anfragen erfolgt dabei nach bestimmten Strategien. Besonders populär ist die Round Robin Methode, bei der jeder neue Zugriff der Reihe nach an den nächsten Server im Pool weitergeleitet wird. Sobald das Ende der Liste erreicht ist, beginnt die Zuweisung wieder von vorne. Dies sorgt für eine gleichmäßige Verteilung ohne komplexe Logiken. Andere Strategien berücksichtigen beispielsweise die aktuelle Auslastung der Server oder nutzen IP-basierte Hash-Verfahren, um eine Sitzungskonsistenz sicherzustellen.
Bei letzterem wird garantiert, dass ein Nutzer immer auf denselben Server geleitet wird, was etwa für Online-Shops oder Anwendungen mit angemeldeten Nutzern entscheidend sein kann. Die Round Robin Methode ist vor allem durch ihre Einfachheit attraktiv und bildet die ideale Grundlage für einen selbstgeschriebenen Load Balancer. Der Kern einer solchen Implementierung liegt in der Verwaltung der Backend-Server. Anstatt mit einzelnen Servern eigenständig zu kommunizieren, wird ein Serverpool aufgebaut – eine Sammlung, die alle verfügbaren Server auflistet und verwaltet. Dabei beinhaltet jeder Server wichtige Eigenschaften wie eine eindeutige ID, einen Namen zur leichten Identifikation sowie die zur Kommunikation nötigen Netzwerkdaten wie Protokoll, Host-Adresse und Port.
Zusätzlich ist es wichtig, den Zustand jedes Servers zu kennen, ob er also gesund ist und Anfragen empfangen kann, sowie wann zuletzt eine Überprüfung durchgeführt wurde. So lassen sich Ausfälle schnell erkennen und ungesunde Server aus der Lastverteilung ausnehmen. Die Round Robin Logik selbst führt dann über diesen Pool eine einfache, aber effektive Auswahl durch. Mit Hilfe einer Index-Variable wird immer der nächste Server ausgewählt. Ein Mutex sorgt dafür, dass in Mehrbenutzerumgebungen keine Konflikte bei der Aktualisierung dieses Index entstehen.
So wird gewährleistet, dass jederzeit nur eine Anfrage den Zeiger verändert und es nicht zu Doppelbelegungen kommt. Wenn der letzte Server erreicht ist, springt der Zeiger dank eines modularen Operators wieder auf den ersten zurück – der Kreis schließt sich. Nachdem der Server bestimmt wurde, erfolgt die eigentliche Weiterleitung der Anfrage. Die eingehende HTTP-Anfrage wird dabei fast eins zu eins erstellt, nur die Ziel-URL wird angepasst, um auf den ausgewählten Backend-Server zu verweisen. Dabei werden auch alle Header übernommen und ein spezieller Header „X-Forwarded-For“ ergänzt, der die IP des ursprünglichen Clients enthält.
Dies ist entscheidend, damit die Backend-Server nachvollziehen können, von wem die Anfrage ursprünglich kam. Für die Kommunikation mit den Backend-Servern wird in der Regel ein HTTP-Client verwendet, der bei Zeitüberschreitungen oder Fehlern entsprechend reagieren kann. Ein großer Vorteil dieser selbstgebauten Lösung ist die Übersichtlichkeit und Anpassbarkeit. Mit circa 250 Zeilen lässt sich ein produktionsfähiger Load Balancer schreiben, der als Grundlage für weitere Erweiterungen dient. So kann beispielsweise eine Gesundheitsüberprüfung der Server implementiert werden, die automatisch ungesunde Instanzen erkennt und temporär aus der Verteilung nimmt.
Auch die Unterstützung weiterer Strategien, wie Least Connection oder Weighted Round Robin, ist prinzipiell einfach integrierbar, da das System modular aufgebaut ist. Die Implementierung endet nicht mit dem internen Load Balancer, sondern beansprucht auch das Zusammenspiel aller Komponenten. Der Einstiegspunkt ist ein Hauptprogramm, das alle Backend-Server definiert, sie in den Pool einfügt und den Load Balancer mit der gewählten Strategie initialisiert. Dort wird auch der eigentliche HTTP-Server aufgesetzt, der auf einem festgelegten Port auf eingehende Anfragen wartet und diese per Load Balancer an die jeweiligen Server weitergibt. Die Praxis zeigt, dass eine so schlanke und dennoch vollständige Architektur enorme Vorteile hinsichtlich Verständlichkeit, Wartbarkeit und Performance bietet.
Entwickler erhalten ein solides Fundament, das gezielt erweitert und angepasst werden kann, ohne auf externe Abhängigkeiten oder komplexe Frameworks angewiesen zu sein. Somit eignet sich dieses Vorgehen ideal für Lernzwecke, Prototypenentwicklung oder sogar kleinere produktive Systeme, die Skalierung und Redundanz benötigen. Nicht zu unterschätzen ist dabei auch die Sicherheitsaspekte, da der Load Balancer ein zentraler Knotenpunkt im Netzwerk ist. Durch gezielte Kontrolle des Datenflusses, Überwachung und präzise Konfigurationsoptionen lässt sich die angreifbare Oberfläche reduzieren. Der Verzicht auf vorgefertigte Proxy-Lösungen gibt zudem mehr Kontrolle über die Anforderungen und ermöglicht tiefere Einblicke in den Ablauf.
Abschließend lässt sich festhalten, dass ein Load Balancer kein unüberwindbares Hindernis darstellen muss. Wer die Grundprinzipien und Mechaniken versteht, kann mit überschaubarem Aufwand eine eigene Lösung entwickeln, die den Anforderungen moderner Anwendungen gerecht wird. Die Kombination aus Servermanagement, Round Robin Algorithmus und sauberer Anfrageweiterleitung bildet das Fundament dafür. Künftige Erweiterungen wie Gesundheitschecks, adaptive Lastverteilung oder Sitzungsmanagement können auf dieser Basis langfristig implementiert werden. Durch die konsequente Orientierung an einfachen und bewährten Mustern gewinnen Entwickler eine solide technische Kompetenz, die sich auf viele komplexere Systeme übertragen lässt.
Das Selbstprogrammieren eines Load Balancers ist somit nicht nur eine interessante Herausforderung, sondern auch ein wertvoller Lernprozess, der praktische Netzwerkerfahrung und Programmierkenntnisse nachhaltig verbessert. In einer Welt, in der flexible und skalierbare Systeme immer wichtiger werden, ist ein solches Verständnis von unschätzbarem Wert.