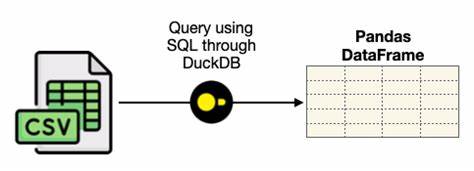
In den letzten Jahren hat sich DuckDB als eine extrem leistungsfähige und zugleich einfach zu bedienende analytische Datenbank etabliert. Seine Architektur erinnert dabei stark an Sqlite, ist jedoch gezielt auf analytische Workloads optimiert, welche oft mit großen Datenmengen arbeiten. Im Vergleich zu den klassischen Big-Data-Lösungen punktet DuckDB vor allem mit geringeren Kosten, einfacher Installation und flexibler Nutzung ohne umfangreiche Infrastruktur. Der Gedanke, ScalaSQL als ORM-Bibliothek aus dem Scala-Ökosystem mit DuckDB zu kombinieren, ist deshalb mehr als nur eine technische Spielerei. Es geht darum, die Stärken beider Technologien zu verbinden und die Vorteile von Typensicherheit, funktionaler Programmierung und SQL-Konformität in der Datenverarbeitung nutzbar zu machen.
Doch wie realistisch ist dieses Vorhaben und welche Herausforderungen gilt es zu meistern? DuckDB setzt auf den Postgres SQL-Dialekt, was für ScalaSQL eine perfekte Grundlage darstellt. ScalaSQL nutzt diesen Dialekt, um typsichere Datenbankzugriffe zu ermöglichen und abstrahiert gleichzeitig wesentliche Schritte in der Abfrageerstellung. Die Integration erfolgt über den JJDBC-Treiber von DuckDB, mit dem sich eine direkte Verbindung zum Datenbankkern herstellen lässt. Das Ganze gestaltet sich dank ScalaSQL vergleichsweise einfach und erlaubt es Entwicklern, Datenbanktabellen als Case Classes zu definieren. So entsteht eine Brücke zwischen objektorientierter Programmierung und relationaler Datenwelt, die klassische SQL-Statements elegant umgeht und Fehlerquellen reduziert.
Die praktische Anwendung zeigt, dass Insert- und Select-Statements mit ScalaSQL problemlos auf DuckDB ausgeführt werden können. Ein Beispiel sind Tabellen wie "Items", welche als Case Classes modelliert werden und per ScalaSQL in der Datenbank persistiert werden. Das erzeugte SQL wird automatisch korrekt gerendert und ausgeführt, wodurch der Entwickler vor syntaktischen Problemen geschützt wird. Dennoch gibt es derzeit noch signifikante Einschränkungen bei der Verwendung von ScalaSQL mit DuckDB. Eine der größten Hürden ist das Fehlen nativer Unterstützung für Data Definition Language (DDL) innerhalb von ScalaSQL.
Das bedeutet, dass Tabellenstrukturen und Indizes momentan nicht über gepufferte ScalaSQL-Methoden definiert oder verändert werden können, sondern separat in SQL-Dateien gepflegt und mit rohen SQL-Statements ausgeführt werden müssen. Gerade bei analytischen Datenprojekten, wo häufig große Mengen an Daten erzeugt, transformiert und geladen werden, ist diese Einschränkung spürbar. Darüber hinaus fehlen aktuell auch Funktionen zur Nutzung von COPY-Statements, die im Postgres-Dialekt unterstützt und von DuckDB zum effizienten Export von Daten beispielsweise als Parquet-Dateien verwendet werden können. Ohne diese Möglichkeiten steigt der Aufwand bei Datentransformationen und Datenexporten, was den Einsatz von ScalaSQL im Bereich Data Engineering erschwert. Der Fokus von ScalaSQL liegt traditionell auf operationellen Datenbanken, wo diese Funktionen weniger stark benötigt werden.
Daher ist es wenig verwunderlich, dass der vollständige Funktionsumfang im analytischen Kontext noch nicht gegeben ist. Trotzdem zeigt die Kombination Potenzial, insbesondere wenn man DDL und Bulk-Operationen weiterhin über rohe SQL-Kommandos abwickelt, während die komplexeren Transformationen und Abfragen mittels ScalaSQL typsicher und wartbar gestaltet werden. Ein weiterer spannender Aspekt ist die Nutzung von Apache Arrow im Zusammenspiel mit DuckDB und ScalaSQL. Arrow ermöglicht eine performante, spaltenorientierte Datenhaltung und einen schnellen Datenaustausch zwischen verschiedenen Systemen. In der Praxis ist es möglich, Arrow-Vektoren in DuckDB zu registrieren und anschließend mit ScalaSQL darauf zuzugreifen.
Allerdings gestaltet sich die Umsetzung mit Arrow bisher recht aufwändig, da unter anderem die Erstellung eines vollständigen VectorSchemaRoot notwendig ist und bestimmte Java Runtime-Optionen gesetzt werden müssen, etwa die --add-opens Variable. Diese Komplexität erschwert den Einsatz in einfachen Entwicklungsumgebungen, zeigt aber ebenfalls, dass durch Erweiterungen und Optimierungen die Lücke zwischen ScalaSQL und hochperformanten analytischen Workflows kleiner werden kann. Zusammenfassend lässt sich sagen, dass die Kombination aus ScalaSQL und DuckDB durchaus praktikabel ist und bereits in vielen Bereichen funktioniert. Vor allem Entwickler, die auf Scala setzen und dessen Stärken wie Typensicherheit und funktionale Programmieransätze für Datenanalysen nutzen wollen, finden hier eine interessante Alternative zu etablierten Big-Data-Tools und Python-basierten Lösungen. Die Kostenersparnis im Vergleich zu großen Cloud-basierten Datenplattformen ist nicht zu unterschätzen, speziell für kleinere bis mittlere Datenmengen.