Im Zeitalter der digitalen Informationsflut ist die Fähigkeit, relevante Daten schnell und präzise aus umfangreichen Texten zu extrahieren, von zentraler Bedeutung. Künstliche Intelligenz und insbesondere Systeme für Informationsretrieval spielen dabei eine entscheidende Rolle. Traditionsgemäß werden Dokumente in kleinere Abschnitte, sogenannte Chunks, unterteilt und diese anschließend einzeln in Vektorform gebracht, um semantisch ähnliche Inhalte effizient abrufen zu können. Doch dieser Ansatz weist gravierende Schwächen auf, insbesondere im Umgang mit Kontextinformationen, die sich über mehrere Chunks erstrecken. Hier setzt das Konzept des Late Chunkings an, das eine grundlegende Neuerung in der Vorgehensweise darstellt und die Qualität der Dokumentenrecherche erheblich verbessert.
Im Folgenden wird das Prinzip von Late Chunking umfassend dargestellt, seine Vorteile erläutert und dessen Bedeutung im Bereich moderner NLP-Anwendungen hervorgehoben. Das Kernproblem klassischer Chunking-Strategien besteht darin, dass Dokumente vor der Einbettung in semantische Vektoren in kleine, meist isolierte Ausschnitte aufgeteilt werden. Diese Vorgehensweise führt dazu, dass kontextuelle Bezüge zwischen den einzelnen Chunks verloren gehen. So können Verweise wie Pronomen oder allgemeine Begriffe ohne Rückgriff auf vorherige Abschnitte missverstanden oder falsch interpretiert werden. Ein typisches Beispiel: Wird in einem Chunk von „der Stadt“ gesprochen, ohne den Stadtnamen explizit zu nennen, bleibt für das System unklar, auf welche Stadt sich diese Bezeichnung bezieht, wenn der relevante Bezugspunkt in einem vorherigen Chunk steht.
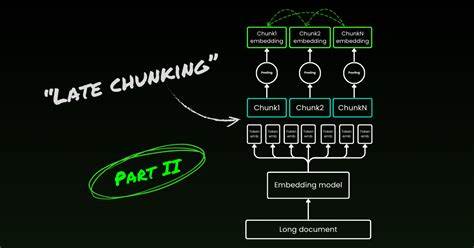
Dies führt zu fehlerhaften Suchergebnissen, insbesondere bei Anfragen, die eine semantische Verknüpfung über mehrere Textpassagen hinweg erfordern. Late Chunking kehrt die herkömmliche Herangehensweise um und verkettet erst nach dem Erzeugen von Einbettungen im Tokenraum. Anstatt also das Dokument in mundgerechte Teile zu zerlegen, bevor es in Vektoren überführt wird, wird im ersten Schritt das gesamte Dokument auf Tokenebene durch ein langkontextfähiges Einbettungsmodell verarbeitet. Dabei wird für jeden Token oder jedes Wort eine Repräsentation erzeugt, die alle Dokumentinformationen einbezieht. Im Anschluss werden per Chunking die einzelnen Textabschnitte im Tokenraum definiert, und die zugehörigen Token-Embeddings werden zu einem einzigen Vektor für jeden Chunk aggregiert, beispielsweise durch Mittelwertbildung.
Dieses Verfahren stellt sicher, dass die Einbettungen jedes Chunks die komplette Kontextinformation des gesamten Dokuments enthalten. Ein essenzieller Faktor für die Umsetzung von Late Chunking sind Langzeitkontextmodelle, die in der Lage sind, sehr umfangreiche Texte auf einmal zu erfassen. Solche Modelle können mehrere tausend Tokens verarbeiten, wodurch sie Beziehungen und Verweise über große Textabschnitte hinweg verstehen und abbilden können. Sie ermöglichen eine bidirektionale Kontextwahrnehmung, sodass sowohl vorherige als auch nachfolgende Informationen in die Einbettungsdarstellung einfließen. Somit können pronomenhafte Bezüge oder thematische Zusammenhänge auch dann korrekt interpretiert werden, wenn sie sich über unterschiedliche Abschnitte verteilen.
Die Vorteile von Late Chunking zeigen sich besonders bei Suchanfragen, deren Antworten Informationen aus verschiedenen Teilen eines Dokuments benötigen. Während klassische Ansätze häufig nur Teilinformationen extrahieren oder falsche Ergebnisse liefern, sorgt Late Chunking für konsistentere und relevantere Treffer. Dies erhöht die Nutzerzufriedenheit, da Suchsysteme nicht nur Stichwortübereinstimmungen liefern, sondern die zugrunde liegenden Zusammenhänge erkennen und abbilden können. Darüber hinaus trägt Late Chunking zur Reduzierung redundanter Daten bei. Traditionelle Methoden, die mit überlappenden Chunks arbeiten, führen oft zu mehrfach gespeicherten Informationen, was sowohl die Speicherlast als auch den Indexierungsaufwand erhöht.
Late Chunking hingegen benötigt keine oder nur minimale Überlappungen, da die kontextuelle Einbettung bereits alle essenziellen Verknüpfungen beinhaltet. Dies optimiert die Performance und Effizienz von Retrieval-Systemen erheblich. In der praktischen Anwendung wird Late Chunking oft mit speziellen Tokenizern und Modellen realisiert, die die Tokenpositionen und ihre semantischen Beziehungen dokumentübergreifend erfassen. Ein Beispiel ist der Einsatz von Modellen wie „jina-embeddings-v2-base-en“, die auf lange Kontexte optimiert wurden. Diese Modelle erzeugen für jeden Token ein Embedding, das die gesamte Dokumentenstruktur reflektiert.
Anschließend wird durch gezielte Chunk-Definition z.B. auf Satz- oder Absatzebene, die Aggregation durchgeführt, sodass jede Chunkeinbettung sowohl spezifisch als auch dokumentweit informiert ist. Ein weiterer kritischer Aspekt ist die Wahl der Chunk-Grenzen. Während traditionelle Ansätze oftmals komplexe Strategien mit überlappenden Segmenten und heuristischen Längeinstellungen nutzen, gestaltet sich dies bei Late Chunking einfacher.
Da jede Token-Einbettung bereits im umfassenden Kontext generiert wurde, verliert die exakte Chunk-Grenze an Relevanz. Das ermöglicht die Nutzung einfacher Chunking-Strategien, wie dem Aufteilen bei Satzzeichen, ohne Qualitätseinbußen in den Resultaten zu befürchten. Die Evaluierung von Late Chunking verdeutlicht seinen Nutzen eindrucksvoll. In verschiedenen Testszenarien ergibt sich eine massive Verbesserung bei Fragen, deren Antworten kontextübergreifend im Dokument verteilt sind. Während herkömmliche Methoden häufig eine sehr niedrige Treffergenauigkeit bei solchen Fragestellungen aufweisen, kann Late Chunking den Großteil dieser Anfragen korrekt und vollständig beantworten.
Gleichzeitig sinkt jedoch die Genauigkeit bei Fragen, die in einem einzigen Chunk gelöst werden können, nicht, was die Vielseitigkeit und Robustheit des Verfahrens unterstreicht. Neben dem offensichtlichen Nutzen für Suchmaschinen und Retrieval-Anwendungen eröffnet Late Chunking interessante Perspektiven für den Einsatz in Retrieval-Augmented Generation (RAG)-Systemen, bei denen große Sprachmodelle durch externe Quellen ergänzt werden. Die verbesserte Kontextintegration und präzisere Chunk-Repräsentation kann die Qualität generierter Antworten deutlich erhöhen und die Informationssynthese natürlicher gestalten. Die Bedeutung von Late Chunking wächst mit dem wachsenden Bedarf an verlässlichen Informationssystemen, die in der Lage sind, komplexe und umfangreiche Datenbestände intelligent zu durchsuchen. Unternehmen, die auf effiziente Wissensmanagementsysteme angewiesen sind, profitieren von verbesserten Suchergebnissen und einer gesteigerten Nutzererfahrung.
Auch im Bereich der Forschung und Lehre erleichtert das Verfahren den Zugang zu relevanten Informationen aus großen Textkorpora. Die Herausforderungen bei der Implementierung von Late Chunking liegen heute noch in der hohen Komplexität und Rechenintensität von Langzeitkontext-Modellen, sowie in der nötigen Infrastruktur für deren effizienten Betrieb. Doch die rasante Entwicklung in der KI-Forschung und Hardware-Optimierung lässt erwarten, dass sich diese Barrieren in naher Zukunft deutlich verringern werden. Die steigende Verfügbarkeit von geeigneten Pretrained Modellen und optimierten Tokenizern macht Late Chunking zunehmend praktikabel und attraktiv für vielfältige Einsatzfelder. Insgesamt markiert Late Chunking einen bedeutenden Fortschritt gegenüber klassischen Chunking-Methoden.
Es korrigiert den bisher vernachlässigten Verlust von Kontext über Chunks hinweg, gewährleistet damit eine tiefere semantische Verständnistiefe und ermöglicht eine effektivere Suche nach zusammenhängenden Informationen. Wer auf zukunftsweisende Suchtechnologien setzt, sollte Late Chunking daher als essenzielle Komponente moderner Retrieval-Systeme im Blick behalten und in ihre Entwicklungsstrategie integrieren.