In der heutigen digitalen Welt wächst das Datenvolumen explosionsartig, und die Anforderungen an moderne Sprachmodelle (Large Language Models, LLMs) steigen stetig. Immer mehr Unternehmen und Entwickler setzen auf KI-basierte Textverarbeitung, sei es zur Generierung von Inhalten, Analyse großer Textbestände oder zur Automatisierung von Geschäftsprozessen. Dabei spielt die Effizienz der Inferenz – also die Anwendung der trainierten Modelle auf neue Eingabedaten – eine entscheidende Rolle. Insbesondere wenn Millionen von Prompts oder Datenfragmenten verarbeitet werden müssen, können Kosten für Inferenz schnell ins Unermessliche steigen. Hier setzt die Batch-LLM-Inferenz als kostengünstige und effiziente Lösung an und revolutioniert die Art und Weise, wie große Textmengen bearbeitet werden.
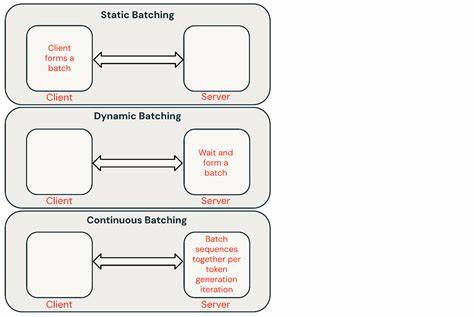
Batch-LLM-Inferenz ermöglicht die Verarbeitung tausender Texteingaben in einem einzigen, durchdachten Arbeitsprozess und optimiert dabei sowohl Zeit als auch Ressourcen. Die grundlegende Idee dahinter ist, statt jedes einzelne Textstück nacheinander in Echtzeit zu verarbeiten, eine Vielzahl an Eingaben gesammelt und gleichzeitig durch das Modell zu schicken. Dies führt zu erheblichen Einsparungen bei den Kosten für den Einsatz von LLMs, da die Infrastruktur maximal ausgelastet wird und gleichzeitig die Latenz – also die Verzögerung bis zur Rückmeldung – nicht oberste Priorität hat. Durch diese Fokussierung auf den Durchsatz können Anbieter wie batchinference.com beeindruckende Kostensenkungen anbieten.
Das Prinzip ist vergleichbar mit industriellen Fertigungsstraßen, bei denen Produkte in Chargen effizienter hergestellt werden als in Einzelanfertigung. Anstatt also jeden einzelnen Prompt einzeln und sofort zu verarbeiten, wartet das System, bis eine größere Anzahl von Prompts zusammenkommt, und verarbeitet diese gesammelt. Dies ermöglicht eine optimierte Nutzung von Rechenkapazitäten und reduziert die Kosten pro Ausgabezeichen (Output Token) dramatisch. Ein besonders attraktives Merkmal ist, dass bei Batch-LLM-Inferenz üblicherweise nur für die tatsächlich generierten Ausgabezeichen gezahlt wird. Dies macht den gesamten Prozess transparent und kalkulierbar, besonders für Anwender, die langfristig und in großem Umfang mit Sprachmodellen arbeiten möchten.
Die Vielfalt an verfügbaren Modellen und deren Preisgestaltung ist ein weiterer Vorteil für den Nutzer. Unternehmen können basierend auf ihrem Bedarf und Budget aus unterschiedlich großen oder spezialisierten Modellen wählen. So gibt es hochperformante Varianten wie Deepseek R1 oder Qwen 3 mit Milliarden Parametern ebenso wie kleinere, günstige Modelle wie Llama 3.1 8B Instruct, die bereits für einen Bruchteil der Kosten pro Million Tokens angeboten werden. Diese Flexibilität erlaubt es, maßgeschneiderte Lösungen zu finden, die sowohl hinsichtlich Qualität als auch Kosten effektiv sind.
Gerade für Aufgaben wie synthetische Datengenerierung, Vorverarbeitung bei Retrieval-Augmented Generation (RAG), Datenextraktion, großflächige Klassifizierungen oder komplexe Evaluationen ist Batch-LLM-Inferenz prädestiniert. Statt teure Echtzeit-APIs mit hohen Gebühren und begrenzter Auslastung zu nutzen, profitieren Anwender von einem System, das auf Durchsatz und Kosteneffizienz optimiert ist. Damit lassen sich Projekte umsetzen, die vorher aufgrund der Kostenstruktur kaum möglich waren. Besonders hervorzuheben ist der einfache Workflow für Nutzer. Prompts können bequem in einer JSON-Datei vorbereitet und über eine API eingereicht werden.
Die Batchverarbeitung läuft serverseitig ab und sobald die Berechnung abgeschlossen ist, können die Ergebnisse über die API abgerufen werden. Trotz der gebündelten Verarbeitung liegt die maximale Wartezeit für Rückmeldungen in einem überschaubaren Rahmen – Ergebnisse sind meist innerhalb von 24 Stunden abrufbar. Dies ist für viele Anwendungsfälle mehr als ausreichend, da in nicht-echtzeitkritischen Bereichen Zeit kein limitierender Faktor ist. Die Idee hinter Batch-LLM-Inferenz basiert auf der Erkenntnis, dass viele KI-Anwendungen nicht sofortige Antworten benötigen, sondern auf effiziente und kostengünstige Bearbeitung großer Datenmengen angewiesen sind. So können größere Projekte auch mit begrenztem Budget realisiert werden und der Zugang zu KI-Technologien wird erheblich demokratisiert.
Für Kunden, die noch speziellere Anforderungen haben, bietet Batchanbieter darüber hinaus die Möglichkeit, auch andere Open-Source-Modelle einzubinden oder maßgeschneiderte Lösungen anzufragen. So bleibt die Plattform flexibel und anpassbar an individuelle Bedürfnisse und technologische Entwicklungen. Darüber hinaus bietet das Warten auf den eigenen Zugang zur Plattform (etwa in Form einer Warteliste) ein Zeichen dafür, dass diese Technologie aktuell stark nachgefragt wird und auf ein solides Fundament mit stabiler Infrastruktur gebaut wird. Für viele Anwender stellt dies einen Wettbewerbsvorteil dar, da sie frühzeitig Zugang zu einer innovativen und kosteneffizienten Inferenzform erhalten. Aus SEO-Perspektive gibt es einige wichtige Keywords, die eng mit Batch-LLM-Inferenz verknüpft sind und typische Suchanfragen bedienen.
Dazu gehören Begriffe wie „kostengünstige KI-Inferenz“, „Batch-Verarbeitung von LLM“, „effiziente Sprachmodell-Inferenz“, „LLM Token Pricing“, „Batch API für KI“ oder „skalierbare KI-Datenverarbeitung“. Ein gut abgestimmter Content, der diese Schlüsselwörter sinnvoll integriert, kann die Sichtbarkeit für Interessenten erhöhen und zielgerichteten Traffic generieren. Fazit ist, dass Batch-LLM-Inferenz eine wirklich zukunftsträchtige Entwicklung darstellt, die zahlreiche Einsatzgebiete und Branchen revolutionieren kann. Unternehmen und Entwickler gewinnen damit Zugang zu leistungsfähigen KI-Modellen, ohne astronomische Kosten oder technische Einschränkungen in Kauf nehmen zu müssen. Dieser neue Ansatz macht die Verarbeitung großer Textmengen ökonomisch sinnvoll und technologisch effizient.
Wer heute auf durchdachte und bewährte Batch-Verarbeitung setzt, bereitet sich optimal auf die wachsenden Anforderungen der KI-getriebenen Zukunft vor. Zusammenfassend ist die kostengünstige Batch-LLM-Inferenz eine Schlüsseltechnologie für jeden, der mit natürlichen Sprachmodellen in großem Maßstab arbeitet. Sie bietet durch optimierte Nutzung von Rechenressourcen und flexible Preisgestaltung einen klaren Vorteil im Vergleich zu klassischen Echtzeit-APIs. Damit eröffnen sich zahlreiche innovative Einsatzmöglichkeiten und neue Perspektiven im Bereich der KI-gestützten Textverarbeitung.