In der heutigen digitalen Welt nimmt Künstliche Intelligenz eine immer zentralere Rolle ein. Insbesondere Large Language Models, kurz LLMs, haben die Art und Weise, wie wir mit Maschinen kommunizieren und Informationen verarbeiten, grundlegend verändert. Diese komplexen Modelle, die riesige Mengen an Textdaten verarbeiten können, sind Grundlage für viele Anwendungen wie Chatbots, Übersetzungssysteme, Textgenerierung und Wissensmanagement. Ein bedeutender Trend, der die Entwicklung und Verbreitung von LLMs maßgeblich beeinflusst, ist die Bewegung hin zu Open Source und Open Data. Diese offenen Ansätze versprechen mehr Transparenz, Zusammenarbeit und Innovation – und könnten die technologische Landschaft nachhaltig verändern.
Der Begriff Open Source steht für Software, deren Quellcode öffentlich zugänglich ist, sodass jeder Entwickler diesen einsehen, verändern und weiterverbreiten kann. Im Kontext von LLMs bedeutet dies, dass die Architektur, Trainingsmethoden und oft auch vortrainierte Modelle der Öffentlichkeit bereitgestellt werden. Dies bietet einen entscheidenden Vorteil gegenüber proprietären Lösungen, die meist hinter verschlossenen Türen entwickelt und nur unter restriktiven Bedingungen zugänglich sind. Open Source ermöglicht es Fachleuten, Unternehmen und sogar Hobbyisten, tief in die Technologie einzutauchen, neue Ideen auszuprobieren und bestehende Modelle zu verbessern. Die Innovationsgeschwindigkeit wird durch diesen freien Zugang deutlich erhöht, da zahlreiche talentierte Entwickler auf der ganzen Welt ihre Beiträge leisten können.
Parallel zum Open Source-Gedanken gewinnt auch Open Data enorm an Bedeutung. Open Data bezeichnet den freien und ungehinderten Zugang zu großen, oft komplexen Datensätzen. Für das Training von LLMs sind vielfältige und qualitativ hochwertige Daten unerlässlich, da die Leistungsfähigkeit der Modelle stark vom Umfang und der Vielfalt der Trainingsdaten abhängt. Offene Datenquellen erlauben es Forschern und Entwicklern, auf eine breite Datenbasis zurückzugreifen, ohne durch hohe Kosten oder rechtliche Einschränkungen gehemmt zu werden. Somit wird die Demokratisierung der KI-Forschung gefördert, was insbesondere kleineren Instituten und Start-ups die Möglichkeit gibt, konkurrenzfähige Modelle zu entwickeln.
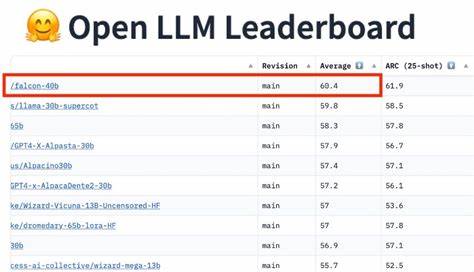
In den letzten Jahren haben viele renommierte Organisationen und Forschungseinrichtungen begonnen, ihre Modelle und Datensätze als Open Source bzw. Open Data zur Verfügung zu stellen. Prominente Beispiele sind unter anderem der GPT-2-Code von OpenAI, diverse Modelle von Hugging Face sowie zahlreiche Datensätze aus dem Bereich der natürlichen Sprachverarbeitung, die frei verfügbar sind. Diese Zugänglichkeit hat eine breite Community rund um LLMs entstehen lassen, die geprägt ist von kooperativem Arbeiten, Wissensaustausch und gemeinsamer Weiterentwicklung. Die offene Verfügbarkeit hat auch dazu beigetragen, ethische und technische Schwachstellen aufzuzeigen, da externe Experten die Systeme auf Bias, Datenschutzproblematiken oder fehlerhafte Verhaltensweisen untersuchen können.
Ein bemerkenswertes Open Source Projekt aus dem Bereich der LLMs ist das Framework, das sich auf parameter-effizientes Training spezialisiert hat. Inspiriert von modernster Forschung, nutzt es Methoden wie Mixture-of-Experts (MoE) und fortschrittliche Attention-Mechanismen, um große Modelle mit effizienter Ressourcennutzung zu trainieren. Solche Innovationen zeigen, wie die enge Zusammenarbeit der Szene zu bahnbrechenden Entwicklungen führt – ganz im Geiste von Open Source. Das Projekt bietet dabei auch Tools zur einfachen Verwaltung von Datensätzen, flexible Trainingspipelines sowie Möglichkeiten zur Überwachung und Analyse der Modelle während des Trainings. Diese umfangreiche, frei zugängliche Infrastruktur senkt die Einstiegshürden für viele Akteure deutlich und fördert eine praxisnahe Nutzung von LLM-Technologie.
Die Rolle von Open Data ist hierbei genauso essentiell. Vielfältige Datensätze ermöglichen nicht nur bessere Trainingsbedingungen, sondern helfen auch, Modelle robuster und vielseitiger zu machen. Offene Datensätze können Texte aus verschiedenen Sprachen, Domänen oder kulturellen Kontexten enthalten. Dies ist besonders wichtig, wenn LLMs globale Anforderungen erfüllen sollen. Ohne offene Daten gäbe es eine starke Abhängigkeit von einzelnen großen Konzernen, die Zugang zu enormen Datenmengen haben, was die Innovation und demokratische Verbreitung von KI deutlich einschränken würde.
Jedoch gibt es auch Herausforderungen bei Open Source und Open Data im Kontext von LLMs. Datenschutz und ethische Fragen spielen eine zentrale Rolle. Die Offenlegung von Daten und Modellen kann potenziell auch missbraucht werden, etwa durch die Erstellung von irreführenden Informationen oder die Verstärkung von Vorurteilen in den Daten. Hier sind strenge Richtlinien, verantwortungsvolle Nutzungskonzepte sowie technische Mechanismen nötig, um Missbrauch zu verhindern und ethischen Standards gerecht zu werden. Darüber hinaus erfordert die Nutzung großer offener Modelle eine beträchtliche Rechenleistung, was eine wirtschaftliche Hürde darstellen kann.
Doch auch hier entstehen durch Open Source Projekte neue Lösungsansätze, indem effiziente Trainingsverfahren und optimierte Hardwarebeschleuniger entwickelt werden. Offene LLM-Initiativen bieten außerdem eine wichtige Plattform für akademische Forschung. Anders als bei kommerziellen Modellen, die oft nicht vollständig transparent sind, können Forscher offene Modelle genau untersuchen und eigene Experimente durchführen. Dies führt zu einem tieferen Verständnis der Funktionsweise und ermöglicht die Entwicklung neuer Verfahren, die die Effizienz, Genauigkeit und Fairness von Sprachmodellen steigern. Weiterhin wird die Nachvollziehbarkeit und Reproduzierbarkeit wissenschaftlicher Arbeiten gefördert, was für die langfristige Fortschrittsfähigkeit unumgänglich ist.
Aus wirtschaftlicher Sicht eröffnen Open Source LLMs neue Geschäftsfelder. Unternehmen können bestehende Modelle an ihre speziellen Bedürfnisse anpassen, erweitern oder als Basis verwenden, ohne von teuren Lizenzgebühren belastet zu werden. Dies erhöht die Wettbewerbsfähigkeit besonders kleiner und mittlerer Unternehmen, die sonst kaum Zugang zu dieser Technologie hätten. Zudem unterstützt die Offenheit die Bildung einer vielfältigen Entwickler-Community, die wiederum neue Ideen und Innovationen hervorbringt, von denen alle Beteiligten profitieren. Die Kombination von Open Source Software und Open Data bei LLMs stellt somit einen entscheidenden Schritt hin zu einer inklusiveren und transparenteren KI-Welt dar.
Sie begünstigt die Verbreitung von Wissen, die Zusammenarbeit über Grenzen hinweg sowie die Entwicklung nachhaltiger und vertrauenswürdiger KI-Systeme. Während einige Herausforderungen zu bewältigen bleiben, zeigt die aktuelle Entwicklung, dass offene Ansätze nicht nur technisch sinnvoll, sondern auch gesellschaftlich wünschenswert sind. Zukünftig ist zu erwarten, dass immer mehr Organisationen die Prinzipien von Open Source und Open Data adaptieren werden, um gemeinsam die nächste Generation von Large Language Models zu entwickeln. Diese Modelle werden nicht nur leistungsfähiger, sondern auch anpassungsfähiger und ethisch verantwortungsvoller sein. Damit ebnen sie den Weg für eine neue Ära der Mensch-Maschine-Kommunikation, die von Offenheit, Kooperation und Innovation geprägt ist.
Die Kraft der Community, gepaart mit dem freien Zugang zu Ressourcen, wird die KI-Landschaft nachhaltig prägen. Open Source und Open Data bei LLMs bilden das Fundament für eine vielfältige und dynamische Zukunft, in der technologische Durchbrüche nicht einzelnen Konzernen vorbehalten sind, sondern allen zugutekommen können. Für Entwickler, Forscher und Anwender bedeutet dies eine spannende Zeit, in der kreative Ideen, verantwortungsbewusstes Handeln und technische Exzellenz Hand in Hand gehen, um die Grenzen des Machbaren immer weiter zu verschieben.




![Artificial Intelligence Report 2025 [pdf]](/images/311B0329-F652-47B0-BDCA-86DFB9015BCB)