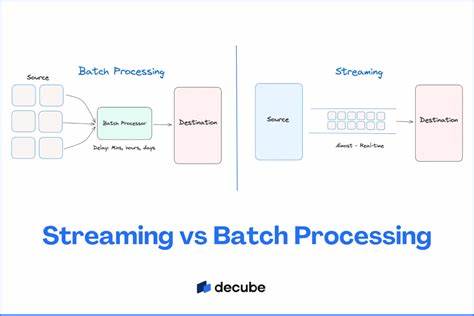
In der Welt der Datenverarbeitung und insbesondere im Umgang mit großen Datenmengen wird oft die Gegenüberstellung von Streaming und Batch diskutiert. Dabei wird häufig suggeriert, dass es sich um zwei strikt voneinander getrennte, sich ausschließende Ansätze handelt – man trifft die Wahl zwischen Streaming oder Batch. Diese Sichtweise erweist sich jedoch als stark vereinfachend und in vielen Fällen sogar irreführend. Ein differenzierterer Blick ist notwendig, um den tatsächlichen Mehrwert und die Komplexität beider Ansätze zu verstehen und ihre Potenziale in der Praxis besser nutzen zu können. Zunächst sollte erkannt werden, dass Streaming-Systeme in der Realität oftmals ebenfalls auf Batch-Verarbeitung zurückgreifen.
Sie verarbeiten Daten nicht zwingend einzeln und unmittelbar, sondern sammeln Daten manchmal in kleinen oder größeren Gruppen – sogenannten Batches – bevor diese weiterverarbeitet oder übertragen werden. Dies hat vielfältige Vorteile, beispielsweise wird die Netzwerkverbindung effizienter genutzt, der Verwaltungsaufwand durch das Parallelschalten von Threads wird reduziert, und es können fortschrittliche Verfahren wie SIMD (Single Instruction, Multiple Data) verwendet werden, die Datenparallelisierung ermöglichen. Batch und Streaming sind also keine Gegensätze, sondern können vielmehr als ergänzende Techniken innerhalb eines Systems betrachtet werden. Die zunehmende Entwicklung hin zu getrennter Speicherung und Berechnung in Datenverarbeitungssystemen, wie es bei modernen Streaming-Plattformen wie WarpStream oder Diskless Kafka der Fall ist, verstärkt diesen Trend noch. In solchen Architekturen kann die Datenaufnahme in kleinen Batches erfolgen, die dennoch in Echtzeit oder nahezu in Echtzeit verarbeitet werden.
Das Timing der Übermittlung ist dynamisch und passt sich der Datenanfallrate an. Wenn viele Daten eintreffen, sind die Batches größer, was zu einer besseren Durchsatzleistung führt; bei geringerem Datenvolumen sind sie kleiner oder sogar einzelne Ereignisse. Dies erlaubt eine Selbstregulierung der Systeme, um einerseits Latenz gering zu halten und andererseits Effizienz zu steigern. Wichtig ist auch die Rolle moderner, spaltenorientierter In-Memory-Datenformate wie Apache Arrow. Solche Technologien vereinfachen die Speicherung und den schnellen Zugriff auf Daten erheblich und tragen dazu bei, dass sich Batching und Streaming reibungslos miteinander verbinden lassen.
Sie ermöglichen, dass Daten durch die hohen Geschwindigkeiten und niedrigen Latenzen der In-Memory-Verarbeitung sehr performant gehandhabt werden können, ohne den Charakter eines Streaming-Systems zu verlieren. Ein weiterer kritischer Punkt ist die eigentliche Diskussion, die hinter der oft simplifizierten Gegenüberstellung von Streaming und Batch steckt. Es geht im Kern um das Paradigma „Pull versus Push“. Dabei stellt sich die Frage, ob neue Daten aktiv von einem System abgefragt (Pull) oder vom Datenlieferanten unmittelbar zum System gesendet (Push) werden. Dieses Konzept ist fundamental, denn bei Pull-Systemen werden Daten in regelmäßigen Abständen abgeholt, wodurch potenziell Aktualisierungen zwischen zwei Abfragen verloren gehen können – insbesondere wenn der Datenstrom nicht kontinuierlich und vollständig verfügbar ist.
Auch Löschungen oder Veränderungen können so übersehen werden. Streaming-Systeme basieren hingegen meist auf dem Push-Prinzip. Die Datenquelle schickt Änderungen unmittelbar weiter und hält das System so stets auf dem neuesten Stand. Das bietet den großen Vorteil, dass ein aktuelles, vollständiges Abbild der Daten in Echtzeit vorliegt. Dies ist eine enorme Stärke, denn es erlaubt Unternehmen, Entscheidungen auf Basis des neuesten Stands zu treffen und Anwendungen zu realisieren, die auf zeitkritische Daten angewiesen sind.
Beispielsweise wird dies bei der Überwachung von Maschinen in Echtzeit oder bei personalisierter Werbung genutzt. Das Push-Prinzip bringt allerdings auch Herausforderungen mit sich. Streaming-Anwendungen müssen oft mit aus dem zeitlichen Kontext fallenden oder verspäteten Daten umgehen, es müssen Zustände in sogenannten Streaming-Joins gepflegt werden, und die gesamte Komplexität der Datenverarbeitung steigt. Hier wird intensiv an Lösungen gearbeitet, beispielsweise durch die Entwicklung von disaggregierten State-Backends, die detaillierte Zustandsverwaltung erlauben, oder durch transaktionale Stream-Verarbeitung, die komplexe Konsistenzanforderungen sicherstellt. Die Innovationsgeschwindigkeit in diesem Bereich ist hoch und führt zu stetigen Verbesserungen, die den Umgang mit Streaming-Daten immer zugänglicher machen.
Trotz allem stellt sich die Frage, ob für jeden Anwendungsfall Streaming wirklich notwendig ist. Die Antwort hängt von den individuellen Anforderungen ab. Für viele Anwendungen kann Batch-Verarbeitung ausreichend sein, besonders wenn die Datengeschwindigkeit und -frische nicht kritisch sind. Dennoch zeigt die Praxis, dass Anwender, die einmal die Szenarien in Echtzeit erlebt haben, zunehmend streamingbasierte Ansätze für eine Vielzahl von Use Cases bevorzugen. Die unvergleichliche „Frische“ der Daten strahlt oft eine Art Magie aus, die den Wunsch nach Echtzeitdaten nachhaltig verstärkt.
Dabei ist die Realität nicht so schwarz-weiß. Batch und Streaming ergänzen sich in modernen Systemen oft. So werden beispielsweise Backfills von Daten – die nachträgliche Verarbeitung großer Datenmengen zur Wiederherstellung oder Aktualisierung eines Datenbestands – klassisch durch Batch-Jobs realisiert, auch wenn der tagtägliche Betrieb auf Streaming setzt. Umgekehrt kann in Situationen mit geringem Datenvolumen ein Streaming-System zeitweise angehalten werden, um Kosten zu sparen, bevor es bei wieder zunehmenden Datenmengen erneut startet. Dieses Vorgehen wird manchmal als „Batch Streaming“ bezeichnet und verdeutlicht, wie sich die Methoden vermischen und flexibel anpassen lassen.
Abschließend zeigt die Betrachtung, dass der vermeintliche Gegensatz zwischen Streaming und Batch oft auf einer falschen Dichotomie basiert. Vielmehr sind beide Ansätze Teil eines Kontinuums innerhalb moderner Datenverarbeitungssysteme. Die Wahl zwischen ihnen sollte auf den konkreten Anforderungen, der Komplexität der Datenlandschaft und der gewünschten Datenaktualität basieren. Grundlegend ist, das Zusammenspiel der zugrundeliegenden Techniken und deren Ergänzung zu verstehen – vom effizienten Batching in Streaming-Systemen bis hin zu Echtzeit-Push-Mechanismen. Das Wissen um diese Zusammenhänge ist essentiell, um die richtigen Technologien und Architekturen auszuwählen und die Vorteile moderner Streaming- und Batch-Technologien zu nutzen.
Nur so können Unternehmen die Herausforderungen der stetig wachsenden Datenmengen meistern und zugleich von einer möglichst schnellen und vollständigen Datenverfügbarkeit profitieren. Die Zukunft der Datenverarbeitung ist weniger ein Widerspruch als ein spannendes Miteinander unterschiedlicher Methoden, das gemeinsam zum Erfolg führt.



![Solving Scala's Build Problem with the Mill Build Tool [video]](/images/A7FF83C3-5FD6-4D3E-BB45-4ECB3768C3B7)