PostgreSQL hat sich als eine der robustesten und leistungsfähigsten relationalen Datenbanken etabliert, die in vielen Unternehmen für kritische Anwendungen unverzichtbar ist. Doch wie bei jeder komplexen Datenbank ist eine kontinuierliche Performanceoptimierung essenziell, um eine schnelle und zuverlässige Verarbeitung von Abfragen sicherzustellen. Dabei ist es ebenso wichtig, Engpässe zielgerichtet zu identifizieren wie auch Überoptimierungen zu vermeiden, die mehr Schaden als Nutzen anrichten können. Ein zentrales Hilfsmittel für diese Aufgabe ist die Analyse von Explain-Plänen. Sie offenbaren, wie PostgreSQL Abfragen plant und ausführt, und geben wertvolle Hinweise auf mögliche Flaschenhälse in der Datenverarbeitung.
Ein gezielter Blick auf diese Execution-Pläne ermöglicht es, die ressourcenintensivsten Schritte zu erkennen und gezielte Maßnahmen einzuleiten, ohne unnötigen Aufwand oder riskante Eingriffe vorzunehmen. Eine Analyse ohne objektive Daten und nur nach Gefühl kann zu übertriebenem Tuning führen, das häufig zu komplizierten Wartungszuständen, längeren Schreiboperationen oder gar unerwarteten Nebenwirkungen führt. Daher ist das Erfassen von realen Ausführungszeiten und Kosten der einzelnen Operationen der Schlüssel zum Erfolg. Ein häufiges Muster bei langsamen Abfragen ist der übermäßige Einsatz von Sequenzscans auf großen Tabellen, vor allem wenn dabei keine passenden Indizes genutzt werden. Solche Scans können viel Zeit und Ressourcen beanspruchen, insbesondere wenn Filterbedingungen auf Spalten angewandt werden, die nicht indexiert sind.
Werden diese Engpässe identifiziert, bietet sich oft die Anlage eines geeigneten Index an. Dabei sollte jedoch darauf geachtet werden, passende Indexarten zu wählen: Composite-Indizes sind sinnvoll, wenn mehrere Spalten gemeinsam gefiltert werden, während partielle Indizes bei häufig verwendeten Filterwerten ressourcenschonender sind. BRIN-Indizes können bei sehr großen, sortierten Datenmengen eine effektive Alternative sein. Doch nicht jede Indexerstellung führt automatisch zu einem Performancegewinn. Indizes erhöhen den Speicherverbrauch und können Schreibvorgänge verlangsamen, weil jede Datenänderung den Index ebenfalls aktualisieren muss.
Deshalb sollte man vermeiden, einfach basierend auf Annahmen neue Indizes hinzuzufügen, ohne die tatsächliche Auswirkung abzuwägen. Ein weiterer wichtiger Punkt ist die regelmäßige Pflege der Datenbankstatistiken und die Durchführung von VACUUM-Operationen. Nur wenn PostgreSQL aktuelle Statistiken über Datenverteilungen und Tabellenzustände besitzt, kann der Optimizer realistische Entscheidungen treffen. Veraltete oder falsche Statistiken führen oft zu suboptimalen Ausführungsplänen. Die Überprüfung der Explain-Pläne sollte deshalb immer in Kombination mit einem aktuellen Vacuum-Analyse-Lauf erfolgen.
Manchmal zeigt ein Explain-Plan einen geplanten Index-Scan auf einer Tabelle, der aber nie ausgeführt wird. Das kann bedeuten, dass PostgreSQL den Scan als ineffizient bewertet hat und stattdessen eine andere Methode nutzt. Hier sollte also nicht vorschnell ein Index hinzugefügt werden, sondern vielmehr beobachtet, ob sich die Abfrageperformance wirklich verschlechtert oder ob der Optimizer bereits die beste Strategie fährt. Eine besonders wichtige Regel lautet: Überoptimierung vermeiden. Wenn die Abfragen bereits extrem kurze Antwortzeiten haben, im Bereich von wenigen Millisekunden oder darunter, sind weitergehende Maßnahmen oft nicht lohnenswert.
Jede zusätzliche Indexpflege oder Restrukturierung kann mehr Aufwand verursachen als Nutzen bringen. Stattdessen empfiehlt es sich, die Performance über längere Zeiträume zu beobachten und erst bei echten Problemen einzugreifen. Extern veränderte Rahmenbedingungen wie Datenwachstum, neue Abfragemuster oder geänderte Geschäftsprozesse können dann neue Anforderungen schaffen, die ein erneutes Überdenken der Indexierung oder Partitionierung notwendig machen. Partitionierung selber ist ein mächtiges Mittel, um sehr große Tabellen in überschaubare Segmente zu zerlegen. Dadurch werden Abfragen oft auf kleinere Datenbereiche begrenzt, was die Effizienz steigert.
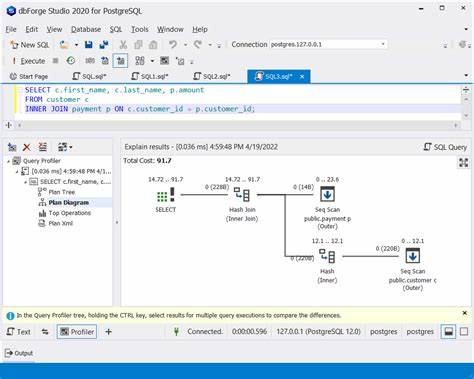
Allerdings ist auch hier zu beachten, dass eine falsche Partitionierung die Komplexität erhöhen und zusätzliche Rechenzeit verursachen kann. Deshalb sollte Partitionierung nur dann eingesetzt werden, wenn eindeutige Zugriffs- und Filtermuster das rechtfertigen. Das Generieren und Interpretieren von EXPLAIN ANALYZE-Ausgaben ist die Basis für fundierte Performanceentscheidungen in PostgreSQL. Sie liefert neben Plankosten auch tatsächliche Laufzeiten, Schleifenanzahlen und Informationen zu ausgeführten Scans und Joins. Ein tieferes Verständnis dieses Outputs ist essenziell, um Prioritäten bei der Optimierung sinnvoll zu setzen.
So lässt sich beispielsweise leicht erkennen, welche Teiloperationen dominant zur Gesamtausführungszeit beitragen. Nach der Identifikation des Flaschenhalses kann gezielt überprüft werden, ob dieser durch einen Index, Partitionierung, Query-Rewriting oder andere Maßnahmen zu verbessern ist. Dabei ist es wichtig, Abfragen und Indizes regelmäßig zu überwachen und die Statistiken aktuell zu halten. Erfolgreiches Performance-Tuning ist kein einmaliger Akt, sondern ein fortlaufender Prozess. Ein überoptimiertes System mit zu vielen Indizes und komplexen Optimierungen erschwert die Wartung und kann zu unvorhersehbaren Nebenwirkungen führen.
Die Balance zwischen ausreichend Optimierung und der Vermeidung von Overhead ist entscheidend. Neben technischen Maßnahmen spielt auch die Überwachung eine große Rolle. Metriken wie Latenz, Throughput und Fehlerraten sollten kontinuierlich beobachtet und Schwankungen analysiert werden. Moderne Monitoring-Tools bieten oft Alerts bei auffälligen Performanceproblemen, sodass frühzeitig reagiert werden kann. Die Integration von Explain-Analyesequenzen in den Workflow der Datenbankadministration hilft dabei, vorhandene Engpässe transparent zu machen und nur dort einzugreifen, wo es wirklich notwendig ist.



![Smart tunnel boring machine in China redefines underground construction [video]](/images/EE71234A-8D0A-469D-A3C2-92DEAC9C53BE)