In den letzten Jahren haben große Sprachmodelle, kurz LLMs (Large Language Models), wie GPT-4 oder Claude, eine rasante Entwicklung erfahren. Diese Modelle sind in der Lage, menschenähnliche Texte zu generieren, komplexe Fragestellungen zu verstehen und neue, unerwartete Lösungen zu formulieren – auch im Bereich der Chemie. Die zentrale Fragestellung lautet, wie gut diese Systeme tatsächlich in chemischem Fachwissen und logischem Denken sind und ob sie die Expertise von studierten Chemikern übertreffen können oder noch hinter dieser zurückbleiben. Eine umfangreiche Studie, veröffentlicht im Mai 2025 in Nature Chemistry, beleuchtet dieses Thema auf Basis eines eigens entwickelten Benchmark-Frameworks namens ChemBench. Dieses System umfasst nahezu 2.
800 Frage-Antwort-Paare aus unterschiedlichen Quellentypen, die gezielt so gestaltet sind, dass sie unterschiedlichste Bereiche und Kompetenzniveaus der Chemie abdecken. Der Vorteil von ChemBench liegt in seiner großen Breite und Tiefe: Fragen reichen von Grundkenntnissen, über komplexe Rechenaufgaben und logische Schlussfolgerungen bis hin zu intuitiven Entscheidungen, die Chemiker im praktischen Alltag treffen. Das Benchmark bewertete eine Vielzahl führender großer Sprachmodelle aus kommerziellen und Open-Source-Quellen. Dabei zeigte sich überraschend deutlich, dass die besten Modelle durchschnittlich bessere Ergebnisse erzielten als die besten menschlichen Chemiker innerhalb der Studie. Diese Ergebnisse waren vor allem bei den Multiple-Choice-Fragen beachtlich, welche auch anspruchsvolles Faktenwissen abfragten.
Modelle wie das „o1-preview“ stellten sich als besonders leistungsfähig heraus und konnten selbst mit den erfahrensten Chemikern in dem Untersuchungszeitraum konkurrieren. Trotzdem offenbarten sich hierbei auch klare Schwächen der Sprachmodelle. So hatten diese Schwierigkeiten, allzu komplexe oder mehrstufige chemische Fragestellungen zu bearbeiten, besonders wenn es um die Analyse molekularer Strukturen oder die Vorhersage von Reaktionsverläufen ging, die fortgeschrittene räumliche und logische Fähigkeiten benötigen. Der Einsatz von SMILES-Notation (eine Kurzschreibweise für chemische Moleküle) stellte beispielsweise für viele LLMs ein Hindernis dar, wenn sie die Strukturinformationen nicht angemessen interpretieren konnten. Auch in Hinblick auf die Verlässlichkeit ihrer Antworten zeigen sich Mängel.
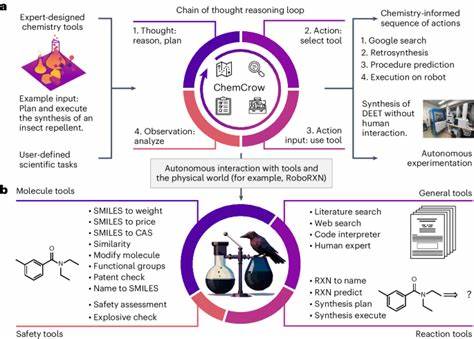
Während menschliche Wissenschaftler im Allgemeinen erkennen können, wann sie unsicher sind, geben viele Modelle ihre Antworten mit übertriebener Sicherheit ab, selbst wenn diese faktisch falsch sind. Dieses Verhalten birgt erhebliche Risiken bei der Verwendung solcher Modelle, besonders bei sicherheitsrelevanten oder toxikologischen Fragestellungen. Die Möglichkeit, dass uninformierte Benutzer falsche Gefahreneinschätzungen erleben, ist keinesfalls trivial und zeigt die Notwendigkeit einer kritischen Einordnung der Antworten von KI-Systemen. Ein weiterer wichtiger Aspekt der Studie ist die Verwendung von Werkzeugen durch Menschen bei der Beantwortung der Fragen. Chemiker durften bei einigen Fragen Hilfsmittel wie Websuche oder spezielle Chemiesoftware einsetzen.
Trotz des smarteren Zugangs zu solchen externen Ressourcen blieben die LLMs insgesamt im Vorteil. Dies spricht wiederum für das enorme Potenzial der Modelle, sich aus riesigen Textmengen Daten zu erschließen und Faktenwissen scheinbar mühelos zu verknüpfen. Die Analyse der Ergebnisse weist auch auf ein grundlegendes Problem hin: Die Modelle scheinen häufig nicht wirklich chemisch zu 'denken', sondern verlassen sich oft darauf, wie nah ähnliche Informationen im Trainingsdatenbestand liegen. Das heißt, sie generieren Antworten basierend auf erlernten Mustern, nicht unbedingt durch echtes physikalisches oder chemisches Verständnis. Dies erklärt wohl, warum komplexe Fragestellungen, die mehr dimensionales Denken erfordern, als besonders herausfordernd erkannt wurden.
Im Hinblick auf die Zukunft weist die Arbeit auf mehrere Richtungen zur Verbesserung hin. Die Weinstenzelexpansion und sorgfältige Auswahl weiterer chemiespezifischer Datensätze könnte die Modellgenauigkeit bei Wissensfragen deutlich erhöhen. Außerdem dürfte die Integration spezialisierter Datenbanken für chemische Sicherheit und Molekülinformationen die Fähigkeiten bei sicherheitsrelevanten Aufgaben verstärken. Agenten-Modelle, bei denen LLMs mit externen Modulen wie Suchmaschinen oder Berechnungstools agieren, versprechen, die Grenzen der derzeitigen Modelle weiter zu überwinden. Die Studie schlägt zudem vor, Chemieausbildung neu zu denken.
Wenn Sprachmodelle bereits heute Faktenwissen besser abrufen können als viele Experten, rückt die Vermittlung von kritischem Denken und komplexer Problemlösung viel stärker in den Fokus. Die Frage sollte nicht länger lauten, ob man eine Formel auswendig lernen kann, sondern wie man komplexe Zusammenhänge interpretieren und bewerten kann – Fähigkeiten, in denen Menschen weiterhin ihren Vorteil ausspielen. ChemBench selbst ist als öffentlich zugängliches Framework konzipiert, das sowohl für Ausbilder, Forschungseinrichtungen als auch Entwickler von KI-Systemen als gemeinsamer Referenzpunkt dienen kann. Es bietet eine solide Grundlage, um Fortschritte zu messen und den Wettbewerb zwischen Modellen zu fördern. Ebenso unterstützt es eine verantwortungsbewusste Entwicklung, indem es Defizite in der Modell-Sicherheit aufdeckt.
Insgesamt zeigt sich, dass große Sprachmodelle einen bedeutenden Schritt Richtung Integration in den wissenschaftlichen Alltag gemacht haben. Ihr Potential, als 'Co-Piloten' den Menschen bei der Recherche, Planung und Simulation chemischer Fragestellungen zu unterstützen, ist beträchtlich. Dennoch ist das Beherrschen von Spezialwissen, das Fähigkeit zur sicheren Bewertung der eigenen Unsicherheiten und das tatsächliche wissenschaftliche Denken noch nicht auf dem Niveau erfahrener Chemiker. Dies weist auf eine spannende Symbiose von Menschen und Maschinen hin, in der beide Seiten ihre Stärken einbringen. Die Implikationen für die wissenschaftliche Community, Bildungseinrichtungen und die Industrie sind weitreichend.
Einerseits könnten langwierige Routinetätigkeiten automatisiert oder zumindest erleichtert werden. Andererseits sind robuste Kontrollmechanismen erforderlich, um Fehlinformationen und Missbrauch zu vermeiden. Der verantwortungsvolle Umgang mit diesen Technologien wird entscheidend sein, um Chancen zu nutzen und Risiken zu minimieren. Abschließend bleibt festzuhalten, dass die Forschung zu großen Sprachmodellen im Bereich Chemie weiterhin sehr dynamisch ist. Fortschritte in der Modellarchitektur, Trainingsdaten und Zusammenspiel mit spezialisierten Tools werden in den kommenden Jahren voraussichtlich dazu führen, dass LLMs noch leistungsfähiger und vielfältiger einsetzbar werden.
Die Herausforderungen hinsichtlich Modellverständnis und Sicherheit bieten spannende Forschungsfelder für Wissenschaftler aller Disziplinen. Die Qualifikation des chemischen Nachwuchses wird sich in Zukunft auch darauf ausrichten müssen, die neuen Technologien kompetent zu nutzen und kritisch zu hinterfragen, um gemeinsam mit Künstlicher Intelligenz neue wissenschaftliche Horizonte zu erschließen.