Die Softwareentwicklung ist ein Bereich, der sich kontinuierlich weiterentwickelt und zunehmend komplexer wird. Entwickler stehen oft vor der Herausforderung, umfangreichen und vielschichtigen Code zu schreiben und gleichzeitig produktiv zu bleiben. In diesem Kontext hat sich die Codevervollständigung als ein unverzichtbares Werkzeug innerhalb integrierter Entwicklungsumgebungen (IDEs) etabliert. Ursprünglich basierte die Codevervollständigung auf regelbasierten semantischen Engines, welche die Struktur des Codes analysieren, um Entwicklern passende Vorschläge zu liefern. Doch die jüngsten Fortschritte im Bereich des maschinellen Lernens, insbesondere bei der Nutzung von Transformer-Modellen, verändern das Spielfeld grundlegend und ermöglichen eine intelligente, KI-gestützte Codevervollständigung, die weit über einfache Token-Vorschläge hinausgeht.
Die Kombination von maschinellem Lernen (ML) mit semantischen Engines (SE) stellt eine revolutionäre Entwicklung dar, die darauf abzielt, die Stärke beider Ansätze zu verbinden. Semantische Engines verfügen über ein tiefes Verständnis der Codebasis und können präzise syntaktische und semantische Analysen durchführen. Machine-Learning-Modelle, wie etwa Transformer-basierte Architekturen, sind in der Lage, längere und komplexere Codefragmente vorherzusagen, indem sie Muster und Zusammenhänge erkennen, die über einfache Regeln hinausgehen. Diese hybriden Systeme bieten damit Entwicklern weitreichende Hilfestellungen, die den Programmierprozess effizienter und reibungsloser gestalten. Bei der Entwicklung solcher hybriden Systeme wird beispielsweise sowohl der semantische Kontext als auch die Stärke von ML-Modellen genutzt, um Vorschläge besser zu priorisieren und zu filtern.
Eingaben des Entwicklers, wie der aktuell geschriebene Code oder der Kontext des Projekts, werden sowohl vom semantischen Backend als auch vom ML-Modell verarbeitet. Das ML-Modell generiert daraufhin mehrere Vorschläge, wobei die semantische Engine die Korrektheit und Relevanz überprüft und bestimmte Vorschläge neu bewertet und entsprechend höher priorisiert. Auf diese Weise gewährleisten die Entwickler, dass die vorgeschlagenen Code-Snippets nicht nur syntaktisch korrekt sind, sondern auch semantisch zum Programmierkontext passen. Ein wesentlicher Vorteil der KI-unterstützten Codevervollständigung liegt in der Möglichkeit, dreistufige Prozesse anzuwenden, bei denen ML-Modelle zunächst Vorschläge generieren, die dann mithilfe von semantischen Checks validiert werden. So werden beispielsweise mögliche Kompilierfehler bereits vor dem Vorschlag ausgeschlossen, was das Vertrauen der Entwickler in die Empfehlungen wesentlich stärkt.
In realen Anwendungen konnte gezeigt werden, dass die Rate akzeptierter Vorschläge durch semantische Prüfungen signifikant steigt, was dazu beiträgt, dass Entwickler deutlich weniger Zeit mit manueller Korrektur und Fehlersuche verbringen. Die Integration von ML-Modellen erlaubt zudem die Vervollständigung mehrerer Codezeilen auf einmal, während traditionelle Systeme oft nur tokenweise oder zeilenweise Vorschläge machen. Die transformerbasierten Modelle können komplexe Methodenaufrufe oder API-Nutzungen umfassend vorhersagen, inklusive der zugehörigen Parameter und Einrückungen. Dies führt zu einem flüssigeren Entwicklungsprozess, da Programmierer nicht mehr jedes Detail mühsam eingeben müssen, sondern auf intelligente Vorhersagen zurückgreifen können, die sich nahtlos in den bestehenden Code integrieren lassen. Ein entscheidender Aspekt für die Leistungsfähigkeit dieser Systeme ist die Trainingsdatenbasis.
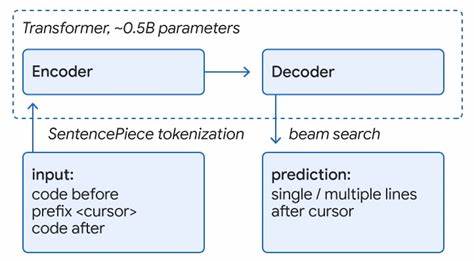
Im Fall von Google wurde ein großes Monorepo genutzt, das qualitativ hochwertigen Code über mehrere Programmiersprachen hinweg enthält. Das ML-Modell wird dabei mit Codefragmenten aus acht verschiedenen Sprachen trainiert, darunter C++, Java, Python, Go und TypeScript. Dies hat den Vorteil, dass ein einziges Modell auf eine Vielzahl von Programmiersprachen anwendbar ist, ohne dass für jede Sprache separate Modelle entwickelt werden müssen – ein großer Gewinn in Bezug auf Wartbarkeit und Ressourcenverbrauch. Die Modelle arbeiten mit einer Größenordnung von rund 500 Millionen Parametern und profitieren stark von der Qualität der zugrundeliegenden Daten. Die Nutzung von Richtlinien und Code-Reviews in der Trainingsbasis erhöht die Genauigkeit der Vorschläge und minimiert Fehler.
Dies zeigt, wie wichtig nicht nur die Modellarchitektur, sondern auch die Datenqualität für den Erfolg solcher Lösungen sind. Ein weiterer bemerkenswerter Effekt zeigte sich bei der Verkürzung der sogenannten Coding Iteration Time – also der Zeit zwischen zwei Entwicklungszyklen, etwa zwischen einem Build und einem Testlauf. Die Verwendung von ML-gestützter Codevervollständigung führte hier zu einer Reduction von etwa 6 Prozent. Auch wenn dieser Wert auf den ersten Blick klein erscheinen mag, bedeutet er in der Summe eine erhebliche Zeitersparnis, die über viele Entwickler und Projekte hinweg zusammenkommt. Solche Optimierungen sind für Unternehmen von großem wirtschaftlichen Wert, da sie helfen, Entwicklungszyklen zu beschleunigen und die Time-to-Market von Softwareprodukten zu verkürzen.
Neben der Zeitersparnis zeigte sich auch eine Verbessung in der Interaktion der Nutzer mit ihrem Codeeditor. Entwickler mussten etwa mehr als zehn Prozent weniger Zeichen eingeben, bevor sie einen Vorschlag annahmen. Dies unterstreicht die steigende Qualität der Vorschläge, die nicht nur korrekter, sondern auch relevanter sind. Die Akzeptanzrate der Vorschläge lag dabei bei 25 bis 34 Prozent, was als bemerkenswert hoch gilt für automatisierte Unterstützungstools. Ein zentrales Element der Implementation solcher Systeme ist die Kollokation von semantischer Infrastruktur und ML-Modellen in der Cloud.
Durch die parallele Bearbeitung von Anfragen durch semantische Engines und ML-Inference wird die Latenz für Entwickler minimal gehalten, wodurch die Benutzererfahrung nicht beeinträchtigt wird. Innovationsfeindliche Wartezeiten, die häufig bei komplexen Modellen auftreten können, werden so vermieden, was die Akzeptanz weiter steigert. Die Zukunft der KI-unterstützten Codevervollständigung verspricht noch mehr Innovationen. Geplant ist unter anderem, den Austausch zwischen den ML-Modellen und semantischen Engines zu intensivieren. So könnten ML-Modelle iterativ Vorschläge machen, die von der semantischen Engine überprüft und verfeinert werden, bevor sie dem Entwickler präsentiert werden.
Dies würde eine Art dynamisches Feedback-System darstellen, das die Präzision und Nützlichkeit von Vorschlägen weiter erhöht. Nicht zuletzt geht es bei der Weiterentwicklung auch darum, über reine „smarte“ Vorschläge hinauszugehen und messbare Verbesserungen in der Entwicklerproduktivität zu erzielen. Die Herausforderung besteht darin, Systeme zu schaffen, die nicht nur technisch beeindruckend sind, sondern tatsächlich den Arbeitsalltag ihrer Nutzer erleichtern. In der Gesamtschau zeigt die Integration von maschinellem Lernen in die Codevervollständigung, wie KI konkrete praktische Probleme in der Softwareentwicklung adressieren kann. Indem ML-Modelle und semantische Engines sinnvoll kombiniert werden, profitieren Entwickler von intelligenten, zuverlässigen und zeitsparenden Werkzeugen, die ihnen den komplexen Alltag erleichtern.
Diese Fortschritte tragen maßgeblich dazu bei, die Produktivität in der Softwarebranche zu erhöhen und die Qualität von Softwareprojekten nachhaltig zu verbessern. Die Forschung und Entwicklung auf diesem Gebiet bleibt spannend und wird in den nächsten Jahren voraussichtlich weitere bedeutende Fortschritte und Innovationen hervorbringen.