In der Welt der Künstlichen Intelligenz spielen große Sprachmodelle (Large Language Models, LLMs) eine immer bedeutendere Rolle. Sie werden in verschiedensten Gebieten eingesetzt – von der automatisierten Textgenerierung bis hin zu komplexen Mehrfachwahlprüfungen. Doch trotz ihrer beeindruckenden Fähigkeiten stehen Entwickler und Forscher vor einer bemerkenswerten Herausforderung: die hohe Instabilität und Sensibilität der Modelle gegenüber minimalen Änderungen in der Struktur der Eingabe, auch als „Prompt“ bezeichnet. Diese Sensitivität führt dazu, dass selbst kleinste Modifikationen im Prompt-Format zu erheblichen Schwankungen der Modellevaluierung führen können, was eine faire und konsistente Beurteilung der Modellqualität erschwert. Genau hier setzt die Idee der strukturierten Generierung an, wie jüngste Untersuchungen des Leaderboards und Evals Forschungsteams bei Hugging Face aufgezeigt haben.
Ihre Forschung öffnet ein neues Kapitel für die Verbesserung der Prompt-Konsistenz und eröffnet innovative Perspektiven in der Evaluierung von LLMs. Das Problem der Formatabhängigkeit bei der KI-Evaluierung ist weitreichend. Experimente haben gezeigt, dass die Leistung eines Modells in einer benchmarking Aufgabe wie MMLU – einem umfangreichen Multitasking-Datensatz – stark schwanken kann, wenn nur die Art und Weise verändert wird, wie die Eingabeformulierung gestaltet ist. Betrachtet man verschiedene Prompt-Variationen, etwa mit oder ohne explizite Antwortmöglichkeiten (Choices), oder mit unterschiedlichen Kennzeichnungen für Frage und Antwort, schwankt die Modellgenauigkeit teilweise um bis zu zehn Prozentpunkte. Sogar eine drastische Verschlechterung wurde beobachtet, etwa beim Modell Qwen1.
5-7B, das bei einer Prompt-Variante eine Genauigkeit von nur 22,9 Prozent erreichte – ohne allerdings die Informationsmenge im Prompt zu verändern. Solche Schwankungen sind nicht nur problematisch für die absolute Leistungsbewertung, sondern verfälschen auch die relative Rangordnung der Modelle. Dies bedeutet, dass Designer von Modellen durch die Wahl geeigneter Prompt-Formate gezielt ihre Modelle bevorzugt darstellen könnten, was den objektiven Vergleich erschwert. Ein weiteres Problem taucht bei der Anordnung von Beispielen im Few-Shot-Lernen auf. Selbst wenn die gleiche Anzahl an Beispielen im Prompt genutzt wird, führt eine andere Reihenfolge zu durchaus relevanten Leistungsunterschieden von bis zu drei Prozentpunkten.
Dadurch wird klar, dass sowohl in der Art der Eingaben als auch in deren Struktur eine erhebliche Varianzquelle zu finden ist. Die Konsequenz daraus ist, dass die klassische Bewertung von großen Sprachmodellen oft wenig robust gegenüber kleinen Veränderungen ist. Eine vielversprechende Alternative zu diesen Herausforderungen wurde von der Firma Dottxt und dem Team bei Hugging Face durch den Fokus auf die Ausgabe des Modells vorgeschlagen und erforscht. Anstatt sich primär auf die promptbezogenen Eingabevariationen zu konzentrieren, setzt man hier auf strukturierte Generierung beim Modell-Output. Diese Technik erzwingt eine bestimmte, vorab definierte Formatstruktur, oftmals als reguläre Ausdrücke (Regex) oder kontextfreie Grammatiken festgelegt.
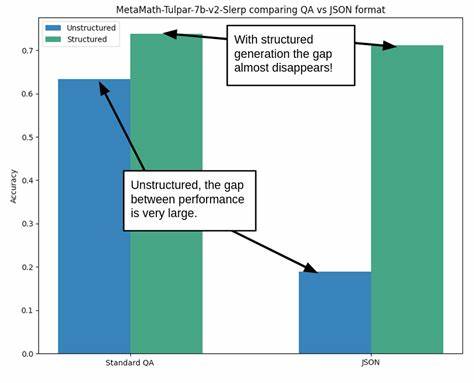
Die Organisation des Outputs stellt sicher, dass alle Antworten einem konsistenten Muster folgen, etwa bei JSON-Formaten oder maßgeschneiderten Antwortlayouts. Strukturierte Generierung hat sich ursprünglich als Hilfsmittel für die Programmierbarkeit von KI-Ausgaben etabliert. Indem ein Modell beispielsweise JSON-Daten liefert, lassen sich seine Antworten leichter automatisiert weiterverarbeiten und validieren. Überraschenderweise stellte sich jedoch heraus, dass strukturierte Generierung auch die Benchmark-Leistung unabhängig vom Inhalt verbessern kann und dabei gleichzeitig die Stabilität gegenüber promptbedingten Variationen erhöht. Als Beispiel wurde die MetaMath-Tulpar-7b-v2-Slerp Serie untersucht, die bei unstrukturiertem JSON-ähnlichem Prompt mit einem starken Abfall der Genauigkeit reagierte.
Dagegen minimierte die strukturierte Erzeugung die Einbußen nahezu vollständig. Dieser Befund führte zu der Hypothese, dass durch die Strukturierung der Ausgabe (Output) eine deutlich höhere Beständigkeit in den Bewertungen erreicht werden kann. Um diesen Gedanken tiefergehend zu prüfen, wurden Experimente mit zwei führenden Modellen im 7-Billionen-Parameter-Bereich durchgeführt: Mistral-7B-v0.1 und Zephyr-7B-beta. Die Tests erfolgten auf einem bekannten mathematischen Benchmark namens GSM8K, der Schul-Mathematikaufgaben in einem Few-Shot-Evaluierungskontext verwendet.
Dabei wurde ein regulärer Ausdruck eingesetzt, der eine genaue Struktur vorschrieb. Konkret durfte das Modell bis zu 700 Zeichen an „Rechenschritten“ oder Erklärungstext liefern, bevor es die abschließende Lösung in einem klar definierten Format – zum Beispiel als eine Zahl am Ende – ausgab. Die gesammelten Ergebnisse waren überzeugend. Die Varianz in den Testergebnissen über unterschiedliche Anzahlen von Beispielen (1 bis 8 Shot) reduzierte sich signifikant. Zusätzlich wurde die Rangordnung zwischen Mistral und Zephyr über alle Prompt-Variationen hinweg konstant gehalten.
Bemerkenswert ist auch die Beobachtung, dass 1-Shot-Prompts beim Einsatz strukturierter Generierung eine Leistung erreichten, die mit den Ergebnissen von 5-Shot unstrukturierter Prompts vergleichbar war. Dieses Phänomen könnte als Fortschritt in Richtung effizienterer Prompts interpretiert werden, was sowohl die Kosten als auch die Komplexität bei der Modellabfrage minimieren kann. Der Fortschritt wurde durch weitere Untersuchungen im Rahmen des GPQA-Datensatzes ergänzt, einem schwierigen multi-choice Benchmark mit anspruchsvollen graduate-level Fragen. Hier wurden nicht nur unterschiedliche Anzahlen an Beispielen variiert, sondern auch deren Reihenfolge mittels festgelegter Zufallszahlen (Seeds) verändert. Die Analyse zeigte erneut, dass strukturierte Generierung nicht nur zu höheren Durchschnittswerte bei der Genauigkeit führte, sondern auch die Streuung der Ergebnisse um den Mittelwert um bis zu 30 % reduzierte.
Dieses stabile Verhalten sorgt für deutlich vertrauenswürdigere Modellvergleiche, da die Bewertung weniger anfällig für zufällige Prompt-Variationen ist. Der Einfluss auf die sogenannte Modell-Rangfolge, also die Entscheidung, welches Modell als besser eingestuft wird, ist besonders bedeutsam. Ohne strukturierte Generierung schwankte die Entscheidung stark in Abhängigkeit von der Prompt-Variante. Mit der Einbindung der strukturierten Ausgabe waren Bewertungsergebnisse hingegen konsistenter und Modelle konnten mit klarerer Überlegenheit bestimmt werden. Für Anwender und Forschende ist dies ein entscheidender Vorteil, um Manipulationen oder unerwünschte Verzerrungen auszuschließen.
Trotz der erfolgversprechenden Resultate bestehen weiterhin offene Fragen und Forschungsbedarf. Um den praktischen Nutzen der strukturierten Generierung breit auszuschöpfen, ist die Überprüfung auf weiteren Datensätzen, mit größeren Modellvielfalten und komplexeren Aufgaben notwendig. Außerdem gilt es, die optimalen Strukturen und Regularien für unterschiedliche Einsatzszenarien systematisch zu erforschen. Schon kleinere Anpassungen an den Strukturvorgaben – beispielsweise die erlaubte Länge für logische Zwischenschritte – haben messbaren Einfluss auf die Leistung. Dieses Konzept wird intern als „thought control“ bezeichnet und könnte zukünftig wertvolle Steuerungsmöglichkeiten zur Verbesserung von Prompt-Effizienz und Antwortqualität bieten.
Das Thema konsistente Prompt-Evaluierung gewinnt angesichts der zunehmenden kommerziellen und wissenschaftlichen Nutzung von LLMs an Relevanz. Nutzer wünschen sich verlässliche, reproduzierbare und transparente Ergebnisse bei der Leistungsbewertung von Sprachmodellen. Die strukturierte Generierung stellt einen vielversprechenden Lösungsansatz dar, der nicht nur theoretisch überzeugt, sondern auch praktische Vorteile hinsichtlich Robustheit, Effizienz und Nachvollziehbarkeit bietet. Zusammenfassend zeigt die Forschungsgemeinschaft mit der strukturierten Generierung einen vielversprechenden Weg auf, um die Herausforderungen bei der Variabilität von Sprachmodell-Evaluationen zu überwinden. Während die Betrachtung der Eingabevariationen weiterhin notwendig ist, schafft der Fokus auf den modellgenerierten Output eine neue Dimension der Stabilität und Fairness.
Die Kombination aus erhöhten Genauigkeiten und verringerter Varianz könnte in Zukunft zum Standard im Bereich der Modellbewertung und -entwicklung werden. Es bleibt abzuwarten, wie sich diese Ansätze in der breiten Anwendung etablieren und welche technischen Feinheiten zukünftig optimiert werden können. Die Antworten auf diese Fragen werden entscheidend sein für die nächste Generation sicherer, effizienter und verlässlicher KI-Systeme, die der Forschung sowie industriellen Anwendungen nachhaltig zugutekommen.