Die Welt der Informationssuche hat in den letzten Jahren enorme Fortschritte erlebt. Besonders die dichte Vektorrepräsentation von Dokumenten und Abfragen hat die Fähigkeit verbessert, relevante Inhalte in großen Datenbeständen zu finden. Neben klassischen Methoden, die ein einzelnes Vektorbild pro Dokument verwenden, rückt die Multi-Vektor-Repräsentation zunehmend in den Fokus der Forschung. Sie ermöglicht eine feinere Granularität und präzisere Erfassung von mehrdimensionalen Zusammenhängen innerhalb eines Textes. Doch trotz dieser Vorteile bringen Multi-Vektor-Modelle spezielle Herausforderungen mit sich, vor allem im Hinblick auf Speicherbedarf und Rechenressourcen.
Im Folgenden wird erläutert, wie das Konzept des Cascading Retrieval, also eines mehrstufigen Suchprozesses, diese Schwierigkeiten adressiert und zugleich die Vorteile mehrerer Vektoransätze kombiniert. Dabei spielt auch das innovative Modell ConstBERT eine wichtige Rolle, das die Balance zwischen Effizienz und Genauigkeit neu definiert. Die Suche nach Informationen in umfangreichen Textsammlungen folgt traditionell einem mehrstufigen Verfahren. Zunächst holt ein schneller, aber weniger präziser Erststufen-Retriever eine breitere Auswahl an Kandidaten. Anschließend verfeinert ein komplexerer zweiter Schritt die Auswahl und schließlich optimiert ein besonders genaues, aber rechenintensives Modell die finale Reihenfolge der Ergebnisse.
Diese traditionelle Retrieve-and-Rerank-Strategie stößt jedoch bei immer größeren Datenmengen und hohem Qualitätsanspruch häufig an ihre Grenzen. Das Ergebnis ist entweder eine Einschränkung der Menge durch vorzeitige Filter oder eine erhebliche Belastung der Infrastruktur durch teure Berechnungen. Multi-Vektor-Repräsentationen bieten die Möglichkeit, dieses Dilemma zu entschärfen. Im Gegensatz zu Single-Vector-Modellen, die einen gesamten Text in einem einzigen Interaktionspunkt abbilden, zerlegen mehrstufige Ansätze Dokumente in mehrere Vektoren, typischerweise einem pro Token oder für definierte Textsegmente. Dies erlaubt eine differenzierte Betrachtung von Textteilen und erleichtert die Identifikation lokaler, kontextabhängiger Relevanzen.
Modelle wie ColBERT haben mit dieser Methode bereits bemerkenswerte Erfolge erzielt. Das Problem liegt jedoch darin, dass für ausgedehnte Dokumente die auf Tokenebene erzeugten Vektoren zu Speicherexplosionen führen und bei der Abfrage hohe Latenzzeiten durch umfangreiche Ähnlichkeitsberechnungen entstehen. Hier setzt ConstBERT als praktisches Multi-Vektor-Modell an, das eine feste Anzahl von Vektoren pro Dokument verwendet, unabhängig von der Länge des Textes. Diese Festlegung hat mehrere entscheidende Vorteile. Einerseits ermöglicht sie eine deutlich bessere Verwaltung und Skalierung großen Datenmengen in Vektorindizes, da alle Dokumente gleich viel Speicherplatz beanspruchen.
Andererseits fördert die einheitliche Struktur die Optimierung der Zugriffe im Arbeitsspeicher und die Nutzung moderner Hardwarebeschleuniger durch konsistente Muster. Durch diese feste Struktur lassen sich zudem effiziente Batch-Verarbeitungen realisieren, die in der Praxis die Verarbeitungsgeschwindigkeit deutlich erhöhen. Neben der Verbesserung der Effizienz adressiert ConstBERT auch die Speicheroptimierung. Durch den Verzicht auf variabel viele Vektoren wird die Indexgröße im Vergleich zu traditionellen Multi-Vektor-Modellen um mehr als die Hälfte reduziert, ohne dabei signifikante Einbußen bei der Suchqualität zu erleiden. Gerade bei Anwendungen mit Millionen oder sogar Milliarden von Dokumenten ist dies ein entscheidender Fortschritt.
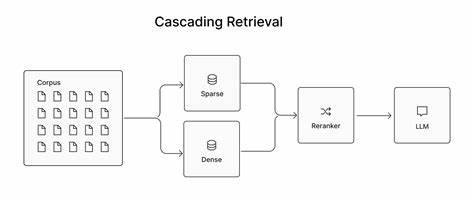
Ein weiterer innovativer Ansatz innerhalb moderner Retrieval-Pipelines ist das sogenannte Cascading Retrieval, das mehrere Phasen miteinander verknüpft. In einer solchen Pipeline startet eine erste Stufe mit einem schnellen Retriever, häufig ein einfacher sparsamer oder dichter Single-Vector-Ansatz, der das Datenvolumen schnell reduziert. Darauf folgt eine Zwischenstufe, in der Multi-Vektor-Modelle, beispielsweise ConstBERT, für eine präzisere Zwischenselektion sorgen. Die finale Stufe wird dann von einem hochpräzisen Cross-Encoder durchgeführt, der jedoch auf eine deutlich kleinere Kandidatenmenge angewandt wird als bei klassischen Systemen. Dieses Vorgehen gewährleistet, dass die Gesamtarchitektur sowohl in puncto Geschwindigkeit als auch hinsichtlich Ergebnisqualität optimal funktioniert.
Das Cascading Retrieval profitiert dabei von den komplementären Stärken der einzelnen Komponenten. Während die erste Stufe eine hohe Recall-Rate sicherstellt und dadurch keine relevanten Dokumente aussortiert, erhöht die Multi-Vektor-Zwischenstufe die Präzision durch feinkörnige Bewertungsmöglichkeiten. Dadurch wird die finale aufwendige Neuralkomponente deutlich entlastet, was ihre Berechnungskosten reduziert und gleichzeitig die Nutzerzufriedenheit durch qualitativ bessere Resultate steigert. In der praktischen Implementierung kann Multi-Vektor-Retrieval durch Modelle wie ConstBERT elegant in bestehende Vektor-Datenbanken wie Pinecone eingebunden werden. Ein effizienter Weg besteht darin, die Multi-Vektor-Repräsentationen als Metadaten innerhalb eines bestehenden Single-Vector-Indexes zu speichern.
Dies erspart doppelte Indizes, vereinfacht die Backend-Architektur und reduziert den Verwaltungsaufwand. Bei einer Suchanfrage wird zunächst die Kandidatengruppe anhand der Single-Vector-Phase ermittelt und anschließend durch die Multi-Vektor-basierten Interaktionen neu bewertet. Dabei wird die Ähnlichkeit über sogenannte MaxSim-Algorithmen berechnet, die performant und effektiv die Zusammenhänge zwischen den Vektorgruppen erfassen. Trotz kleiner Mehrkosten bei der Abfragezeit ist dieser Ansatz besonders attraktiv für großskalige Anwendungen mit hohen Anfragenraten. Im Vergleich zu herkömmlichen End-to-End-Multi-Vektor-Implementierungen zeigen Benchmark-Studien, dass das Reranking mit ConstBERT sowohl hinsichtlich der Rankingqualität als auch der Ressourcenverwendung überzeugen kann.
Insbesondere bei standardisierten Testsets wie MSMARCO und BEIR positioniert sich das Modell nahe an hochkomplexen Lösungen wie ColBERT und schlägt diese teilweise beim nachgelagerten Ranking sogar. Die reduzierte Indexgröße und die geringere Latenz, besonders bei der Verarbeitung großer Dokumentenmengen, machen das Modell zu einer zeitgemäßen Wahl. Langfristig eröffnet dieser Ansatz neue Perspektiven für die Weiterentwicklung von Suchsystemen. Die Kombination aus intelligenten Komprimierungsmethoden, adaptiven Reranking-Strategien und hybriden Modellen verspricht eine noch flexiblere Steuerung von Qualität und Reaktionszeit. So könnten beispielsweise in Zukunft Machine-Learning-gestützte Komponenten auf Anfrage-Komplexität reagieren und den Rechenaufwand dynamisch anpassen.
Ebenso sind Fortschritte bei der Quantisierung und dem Pruning der Embeddings geplant, um die Speicheranforderungen noch weiter zu minimieren. Im Kontext der Bildsuche finden ähnliche Prinzipien Anwendung. Das Modell ColPali exemplifiziert die Übertragung von festen Multi-Vektor-Repräsentationen auf visuelle Daten, was die Effizienz und Skalierbarkeit von Bildretrieval ebenso verbessert. Dieser interdisziplinäre Transfer unterstreicht die Bedeutung fester Vektorformate als Trend in der KI-gestützten Informationsbeschaffung. Für Unternehmen und Entwickler bietet die Einbindung von Multi-Vektor-Ansätzen in moderne Vektor-Datenbanken wie Pinecone eine einfache und performante Möglichkeit, ihre Suchlösungen zukunftssicher aufzustellen.