Die digitale Welt wächst stetig, und mit ihr auch die Anforderungen an Datenverarbeitung und Speicherlösungen. In diesem Kontext stehen Unternehmen vor der Herausforderung, ihre Systeme nicht nur leistungsstark, sondern auch skalierbar zu gestalten. Ein besonders interessantes Beispiel hierfür liefert die Optimierung eines Proxy-Servers, um eine Milliarde Datenbanken zu verwalten – ein Unterfangen, das sowohl technische Finesse als auch innovative Ansätze erfordert. Im Zentrum dieser Entwicklung steht die Turso Cloud, eine serverlose Datenbanklösung, die auf SQLite basiert. SQLite ist eine bewährte, schlanke Datenbank, die vor allem für lokale und mobile Anwendungen populär ist.
Die Besonderheit der Turso Cloud besteht darin, Entwickler in die Lage zu versetzen, SQLite-Datenbanken programmgesteuert und in kürzester Zeit zu erstellen, synchronisieren und verwalten. Diese Fähigkeit erlaubt es, eine Vielzahl von kleinen, individuellen Datenbanken zu verwenden, die beispielsweise für KI-Agenten ideal sind, da jeder einzelne Prompt eine eigene, isolierte Datenbank als Grundlage nutzen kann. Diese Nutzungsmuster führen allerdings zu einer explosionsartigen Zunahme der Datenbankanzahl. Ursprünglich war das System auf eine überschaubare Anzahl von Datenbanken ausgelegt, doch mit dem zunehmenden Einsatz – beispielsweise einem Kunden, der innerhalb von Wochen zwei Millionen Datenbanken generierte – traten erhebliche Skalierungsprobleme auf. Die bestehenden Strukturen stießen an Grenzen, insbesondere der Proxy-Server, der die Verbindung zwischen Benutzeranfragen und der physischen Serverinfrastruktur vermittelt.
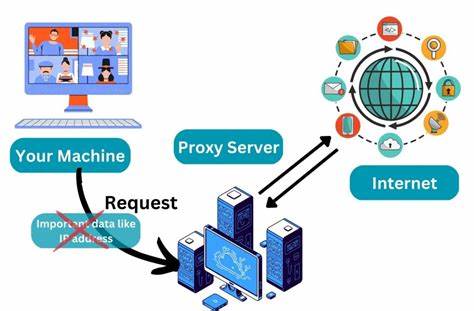
Der Proxy-Server ist eine essenzielle Komponente, die Anfragen an die korrekten Datenbanken leitet. Dazu übersetzt er eine Datenbank-URL in deren physikalischen Speicherort. Diese Zuordnung muss schnell und zuverlässig erfolgen, da jede Verzögerung in der Anfragestation die gesamte Benutzererfahrung beeinträchtigt. Zuvor nutzte der Proxy ein in den Arbeitsspeicher geladenes Mapping aller Datenbanken. Dabei wurde jede Datenbank als Route in einer großen Hash-Map gespeichert.
Dieses Modell funktionierte bei einer kleineren Datenbankanzahl ausreichend gut, aber mit der Skalierung stieg der Speicherbedarf enorm an. Die erste große Herausforderung war das sogenannte Bootstrapping: Beim Start des Proxy-Servers musste dieser alle Datenbank-Mappings von der Core-API ziehen und in den Speicher laden. Mit Millionen von Datenbanken führte dies zu immensen Speicheranforderungen und hoher Latenz beim Start, was das System anfällig für Ausfälle und Verzögerungen machte. Die Lösung bestand darin, den Ladevorgang zu optimieren, indem Daten gestreamt und paginiert übermittelt werden, sodass nur kleine Datenmengen gleichzeitig verarbeitet werden. Ein weiterer Punkt war die Redundanz bei der Speicherung von Routeninformationen.
Das ursprüngliche Datenmodell speicherte viele identische Strings mehrfach, beispielsweise den Namen des Nutzers (App) oder des Hosting-Servers (Address), weil viele Datenbanken denselben Nutzer oder Server teilten. Durch den Einsatz von String-Interning wurde dieser Speicherverbrauch drastisch reduziert. Interning speichert einen String nur einmal und verweist anschließend auf diesen Speicherort mit einer ID, wodurch Duplikate vermieden werden. Darüber hinaus wurde erkannt, dass viele Komponenten der URL redundant waren, speziell der Teil, der die Proxy-Region angibt. Durch Entfernung dieses Teils ergaben sich weitere Einsparungen im Speicherbedarf.
Nach diesen Optimierungen waren die Speicheranforderungen zwar deutlich geringer und stabiler, aber das Problem der exponentiellen Wachstumsrate blieb bestehen, da die Menge an Datenbanken und damit die Speichermenge weiterhin rapide zunahm. Die Erkenntnis, dass das vollständige Halten aller Mappings im Arbeitsspeicher langfristig nicht tragbar ist, führte zu einem Paradigmenwechsel. Statt eines monolithischen In-Memory-Ansatzes wurde eine hybride Lösung mit persistentem Speicher eingeführt. Konkret wurde für den Proxy eine lokale SQLite-Datenbank angelegt, die das aktuelle Mapping speichert und so einen dauerhaften Zustand bewahrt. Dieser Ansatz erlaubt es, beim Neustart des Proxy nicht mehr alle Datenbanken neu zu laden, sondern nur noch die Differenz zum letzten Stand zu übertragen.
Dies reduziert nicht nur den Speicherbedarf drastisch, sondern verbessert auch die Startzeiten erheblich. Die Datenbank ist also der persistente Speicher, während nur die tatsächlich genutzten Mapping-Einträge in einem schnellen LRU-Cache gehalten werden. Diese Cache-Schicht sorgt dafür, dass häufig benutzte Daten schnell zugänglich sind, während selten genutzte Daten auf der Festplatte verbleiben. Ein Lesezugriff auf die SQLite-Datenbank bei einem Cache-Miss erfüllt dennoch schnelle Antwortzeiten, da das Dateisystem und SQLite optimiert sind. Ein weiterer Vorteil dieser Architektur ist die Fähigkeit, den Speicherverbrauch und die Reaktionszeiten besser zu kontrollieren und zu optimieren, da der Cache nach unterschiedlichen Strategien gesteuert werden kann und der persistent gespeicherte Zustand konsistent bleibt, auch wenn der Proxy mehrfach neu startet oder Abstürze auftreten.
Zukunftsorientiert gesehen plant das Entwicklungsteam die Einführung sogenannter Embedded Replicas. Damit könnten SQLite-Datenbanken vom Core direkt auf die Proxy-Ebene repliziert werden. Diese Innovation erlaubt eine noch effizientere Datenhaltung und reduziert die Komplexität der Synchronisation zwischen den Systemteilen. Außerdem stehen weitere Optimierungen auf der Agenda. Beispielsweise könnte die kodierte URL-Information – wie der Organisationsname – mittels Dictionary-Encoding in einer Integer-Repräsentation vorgehalten werden, um Speicherbedarf und Übertragungsvolumen weiter zu senken.
Die Entscheidung, die API-Schicht auf Go zu schreiben, unterstützt die angestrebte Skalierbarkeit durch eine besonders effiziente und gut wartbare Implementierung. Go ist nicht nur für die Serialisierung und Kommunikation zwischen API-Teilen optimiert, sondern bietet auch stabile Laufzeit-Performance, was bei hoher Last entscheidend ist. Insgesamt zeigt die technische Reise zur Bewältigung der Herausforderung, eine Milliarde SQLite-Datenbanken effizient zu managen, die Bedeutung von gut durchdachten Architekturentscheidungen. Der Wechsel von einem rein in-memory orientierten Ansatz hin zu einer hybriden Cache- und Persistenzlösung kombiniert moderne Datenbanktechnologien mit innovativen Programmiertechniken. Diese Strategie ermöglicht es, nicht nur die derzeitigen Anforderungen zu erfüllen, sondern auch zukünftiges Wachstum nachhaltig zu unterstützen und ermöglicht Anwendern, mit Turso Cloud auf einfache und kostengünstige Weise eine große Anzahl an individuellen Datenbanken zu erstellen und zu nutzen.
Für Entwickler und Unternehmen, die auf skalierbare Datenbanksysteme setzen, bietet dieser Fall wertvolle Einblicke. Der Schlüssel liegt darin, den Speicherverbrauch zu optimieren, Anfragen schnell zu beantworten und gleichzeitig die Datenkonsistenz und Systemstabilität zu gewährleisten. Mit dem Einsatz von Go, Rust, SQLite und intelligentem Caching zeigt Turso Cloud eindrucksvoll, wie moderne Cloud-Architekturen auf große Herausforderungen reagieren können. Wer also gerade an der Entwicklung hochskalierbarer Systeme arbeitet oder sich für effiziente Datenbanklösungen interessiert, kann von diesen Erfahrungen enorm profitieren. Turso Cloud macht den Weg frei, damit selbst Milliarden Datenbanken kein Problem mehr darstellen.
Die Zukunft der Datenbank-Architektur ist hier – ergreifen Sie jetzt die Chance, mit den ersten kostenlosen 500 Datenbanken zu starten und das volle Potenzial dieser Technologie zu entdecken.