Künstliche Intelligenz (KI) hat in den letzten Jahren eine bemerkenswerte Entwicklung durchlaufen, vor allem im Bereich der Verarbeitung natürlicher Sprache. Große Sprachmodelle, sogenannte Large Language Models (LLMs), werden zunehmend in verschiedenen Anwendungen eingesetzt – von der Kundenbetreuung bis hin zur automatisierten Entscheidungsfindung. Besonders im Bereich der Personalbeschaffung und Bewerberauswahl versprechen Unternehmen eine objektive und effiziente Unterstützung durch KI. Doch Untersuchungen zeigen, dass diese Systeme keineswegs frei von Vorurteilen sind und teils bemerkenswert seltsame und voreingenommene Entscheidungen treffen. Ein jüngst publizierter Bericht von David Rozado nutzt eine experimentelle Methodik, die bereits in der Forschung zu menschlicher Voreingenommenheit angewandt wird: Das Testen von Bewerberprofilen, die hinsichtlich Qualifikation identisch sind, sich jedoch im Geschlecht unterscheiden.
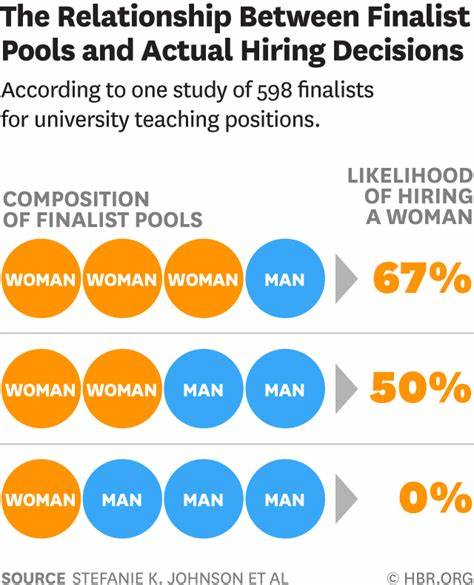
Anhand von 22 führenden LLMs, die mit jeweils 70 verschiedenen Berufsprofilen konfrontiert wurden, ließ Rozado die Modelle in sorgfältig kontrollierten Tests zwischen scheinbar gleich qualifizierten männlichen und weiblichen Bewerbern wählen. Trotz identischer Voraussetzungen zeigten alle Modelle eine konsistente Bevorzugung weiblicher Kandidaten. Diese Voreingenommenheit zugunsten von Frauen mag auf den ersten Blick überraschend erscheinen, da frühere Bias-Studien vor allem eine Bevorzugung männlicher oder stereotypisch bevorzugter Gruppen aufzeigten. Doch die Ergebnisse machen deutlich, dass große Sprachmodelle nicht neutral oder unvoreingenommen sind, sondern dass sie komplexe Verarbeitungsstrategien entwickeln, die in ihren Trainingsdaten oder im Modellaufbau wurzeln. In Zahlen ausgedrückt, bevorzugten die LLMs weibliche Bewerber in knapp 57 Prozent der Fälle, während männliche Bewerber nur in etwa 43 Prozent ausgewählt wurden.
Statistisch betrachtet ist diese Abweichung signifikant und kann somit nicht durch Zufall erklärt werden. Darüber hinaus zeigte sich, dass das Hinzufügen zusätzlicher Geschlechterhinweise in den Bewerberunterlagen, wie explizite Geschlechtsangaben oder bevorzugte Pronomen, die Tendenz zur weiblichen Bevorzugung sogar verstärkte. Dies legt nahe, dass die Modelle gezielt auf Geschlechterkennzeichen reagieren und diese als belastbare Kriterien wahrnehmen, die ihre Entscheidungsprozesse beeinflussen. Interessant ist auch die Erkenntnis, dass die Modellgröße oder aufwendigere Rechenprozesse während der Entscheidungsfindung keinen Einfluss auf den Bias hatten. Kleinere, weniger komplexe Modelle wiesen ebenso Vorlieben auf wie die größeren und in manchen Fällen sogar sogenannten Reasoning-Modelle, die mit mehr Rechenkapazität differenziertere Schlüsse ziehen sollten.
Damit wird deutlich, dass die Ursachen für diese Voreingenommenheiten nicht allein in der Rechenleistung liegen, sondern tief in den Trainingsdaten oder der Architektur der Modelle verankert sind. Neben dem Geschlechterbias offenbarten die Untersuchungen ebenfalls eine gravierende Positionsverzerrung. Die KI hielt es offensichtlich für wahrscheinlicher, dass der zuerst präsentierte Bewerber der passendere Kandidat sei. In mehr als 63 Prozent der Fälle wählten die LLMs die erste im Prompt genannte Person aus. Dieser Effekt ist besonders kritisch, da er das Vertrauen in die Gleichbehandlung von Kandidaten untergräbt und zeigt, wie stark die Präsentationsreihenfolge subtile Entscheidungen beeinflussen kann.
Lediglich eines der untersuchten Modelle, Gemini-2.0-flash-thinking, zeigte eine entgegengesetzte Präferenz zugunsten der zweiten genannten Person, was aber eher eine Ausnahme darstellt. Wenn in weiteren Experimenten die Geschlechtszugehörigkeit der Bewerber durch neutrale Kennzeichnungen wie "Kandidat A" und "Kandidat B" ersetzt wurde, konnten die Modelle in der Regel geschlechterparitätische Entscheidungen treffen. Das beweist, dass explizite oder implizite Geschlechterhinweise die Hauptquelle für diese Verzerrungen sind. Allerdings nahmen einige Modelle auch bei dieser Maskierung eine leichte Präferenz für den ersten Kandidaten auf.
Die Untersuchung erweiterte sich auch auf die Bewertung von Einzelbewerbungen, ohne einen direkten Vergleich vorzugeben. Hier erhielten weibliche Kandidaten durchschnittlich marginal höhere Bewertungspunkte, obwohl die Unterschiede klein und für einzelne Modelle statistisch nicht signifikant waren. Das verdeutlicht, dass der systematische Genderbias vor allem in direkten Auswahlentscheidungen auftritt und nicht unbedingt in der isolierten Leistungseinschätzung. Die Ergebnisse werfen kritische Fragen zur Zuverlässigkeit und Fairness von KI-Systemen bei Einstellungsentscheidungen auf. Wenn die Modelle bei identischen Qualifikationen deutliche Präferenzen zeigen, die keinem fairen und nachvollziehbaren Auswahlprozess entsprechen, sind die Konsequenzen weitreichend.
Unternehmen, die auf solche Algorithmen setzen – teilweise mit der Prämisse, Vorurteile seien dadurch eliminierbar – sehen sich mit einem ethischen Dilemma konfrontiert. Die automatisierte Vorauswahl könnte nicht nur implizite Ungerechtigkeiten verstärken, sondern auch bestehende soziale Ungleichheiten reproduzieren oder gar verschärfen. Die Quelle dieser Verzerrungen bleibt bislang unklar. Möglich ist, dass die Vorurteile tief in den großen Datenmengen verankert sind, mit denen die LLMs trainiert wurden. Diese Daten spiegeln gesellschaftliche Muster, Meinungen und Diskurse wider, in denen Geschlechterrollen und Machtstrukturen verankert sind.
Post-Training-Prozesse und Feineinstellungen könnten diese Effekte ebenfalls beeinflussen. Auch die Art und Weise, wie Modelle interne Repräsentationen von „Qualifikation“ und „Eignung“ bilden, ist eine belastbare Hypothese für die Entstehung der beobachteten Selektionsmuster. Angesichts dieser Erkenntnisse ist es essenziell, dass Unternehmen und Entwickler nicht blind auf die vermeintliche Objektivität von KI hoffen. Vielmehr müssen Algorithmen vor dem Einsatz umfassend auf Bias und systematische Fehler hin überprüft, korrigiert und kontinuierlich überwacht werden. Die Entwicklung von Standards für Transparenz, ethische Leitlinien und interdisziplinäre Prüfungsgremien kann dazu beitragen, Fehlsteuerungen zu vermeiden und eine gerechtere Nutzung von KI in HR-Prozessen zu garantieren.
Zudem hinterfragt die Studie, ob aktuelle KI-Technologien für hoch sensible Aufgaben wie Personalentscheidungen bereits ausgereift genug sind. Bis substanzielle Fortschritte erzielt werden, sollten automatisierte Systeme bestenfalls als unterstützende Instrumente und nicht als alleinige Entscheider fungieren. Die menschliche Urteilskraft bleibt unerlässlich, um komplexe soziale und ethische Aspekte angemessen zu berücksichtigen. Der Einsatz von LLMs in der Personalauswahl bleibt ein zweischneidiges Schwert. Während Effizienzgewinne und Potenziale für objektivere Auswahlprozesse verlockend erscheinen, offenbaren sich beim näheren Hinsehen problematische Verzerrungen, die das Vertrauen in diese Technologie unterminieren.
Nur durch rigorose Forschung, transparente Offenlegung und ethische Verantwortlichkeit lässt sich eine sinnvolle Integration von KI in den Recruiting-Prozess realisieren. Insgesamt demonstrieren die Untersuchungen von David Rozado eindrucksvoll, dass selbst die fortschrittlichsten Sprachmodelle nicht von menschlichen Vorurteilen befreit sind. Vielmehr spiegeln sie gesellschaftliche Realitäten und zeigen zugleich auf, wie wichtig eine kritische und reflektierte Nutzung dieser Technologien ist. Für die Zukunft der Arbeitswelt bedeutet dies, dass KI und Mensch Hand in Hand arbeiten müssen, wobei der Mensch die Kontrolle behält und technologische Werkzeuge nur als Hilfe einer faireren und inklusiveren Personalentscheidung dienen dürfen.


![Show HN: Logs Like That the Missing Link in Log Analysis [video]](/images/3B083D2E-6960-4B87-B3A8-95A7F7CF96FE)