Die Verschmelzung von visuellen und sprachlichen Daten in der künstlichen Intelligenz hat eine neue Ära der Innovation eingeleitet. Multimodale KI-Modelle, die sowohl Bild- als auch Textinformationen verarbeiten und integrieren können, gewinnen immer mehr an Bedeutung. In den letzten Jahren sind mehr als 125 solcher Modelle entwickelt worden, die auf unterschiedlichste Weise Vision und Sprache kombinieren, um komplexe Aufgaben zu bewältigen und damit die Grenzen traditioneller KI-Systeme weit zu überschreiten. Diese Modelle revolutionieren nicht nur die Forschung, sondern finden auch praktische Anwendung in verschiedensten Bereichen wie Gesundheitswesen, autonomes Fahren, Unterhaltung und Bildung. Ein tiefgehender Blick auf ihre Funktionsweise und Entwicklung offenbart bemerkenswerte Fortschritte und Herausforderungen, die die Zukunft der Technologie prägen werden.
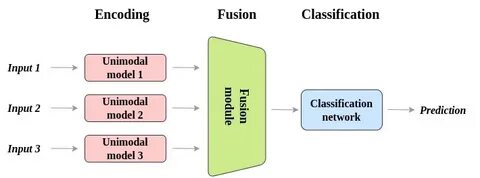
Multimodale KI-Modelle zeichnen sich dadurch aus, dass sie Informationen aus verschiedenen Modalitäten, hier insbesondere aus Bild- und Sprachdaten, gleichzeitig verarbeiten. Im Gegensatz zu rein textbasierten oder bildbasierten Systemen ermöglichen solche Modelle ein tieferes Verständnis von Kontext und Bedeutung. Beispielsweise kann ein Bild mit einer Bildunterschrift kombiniert werden, um nicht nur die Objekte auf dem Bild zu erkennen, sondern auch deren Beziehung zueinander zu verstehen und in natürlicher Sprache zu beschreiben. Dieses Zusammenspiel von visueller Wahrnehmung und sprachlicher Ausdrucksfähigkeit ist entscheidend für Anwendungen wie Bildbeschreibung, visuelle Fragebeantwortung und multimodale Suche. Die Entwicklung dieser Modelle erforderte erhebliche Fortschritte in der Architektur künstlicher neuronaler Netze.
Besonders Transformer-Modelle haben hier eine zentrale Rolle eingenommen. Diese Architektur ermöglicht es, sowohl Text- als auch Bilddaten in einer einheitlichen Repräsentationsform zu verarbeiten. Meistens werden Vortrainingsmethoden eingesetzt, bei denen das Modell auf einer großen Menge an multimodalen Daten lernt, semantische Zusammenhänge herzustellen. Dies kann beispielsweise durch das Vorhersagen fehlender Wörter in Texten, die auf Bildern basieren, oder durch das Erkennen von passenden Bild-Text-Paaren geschehen. Die so gewonnenen Fähigkeiten werden anschließend beim Finetuning für spezifische Aufgaben genutzt.
Die Vielfalt der 125 multimodalen Modelle spiegelt den unterschiedlichen Fokus in Forschung und Anwendung wider. Einige Modelle konzentrieren sich verstärkt auf die Erkennung von Objekten und Szenen in Bildern und deren sprachliche Beschreibung, während andere die Fähigkeit besitzen, komplexe Bildinhalte mit tiefgehenden Erklärungen zu versehen oder sogar kreative Texte zu generieren, die durch visuelle Eingaben inspiriert sind. Modularität und Flexibilität zeichnen viele dieser Ansätze aus, sodass sie an spezifische Bedürfnisse angepasst werden können. Eine besondere Herausforderung bei multimodalen Modellen liegt in der effizienten Fusion der Datenmodalitäten. Vision und Sprache unterscheiden sich grundlegend in ihrer Struktur und Informationsdichte.
Bilder enthalten oft hochdimensionale, kontinuierliche Informationen, während Sprache sequenziell und symbolisch ist. Die Modelle müssen also Wege finden, um diese unterschiedlichen Datentypen zu einem kohärenten Verständnis zusammenzuführen. Techniken wie Attention-Mechanismen oder Cross-Modal-Alignments sind hier entscheidend, um relevante Informationen aus beiden Modalitäten gezielt zu verknüpfen und somit ein einheitliches Semantikverständnis zu erzeugen. Einsatzmöglichkeiten für multimodale KI sind breit gefächert und reichen von der Bildbeschreibung für blinde Menschen über die Analyse von Video-Content bis hin zu interaktiven Sprachassistenten, die visuelle Kontexte interpretieren können. In der Medizin ermöglicht die Kombination von Bildgebung und patientenbezogener Dokumentation eine präzisere Diagnoseunterstützung.
Im Bereich des autonomen Fahrens helfen multimodale Systeme dabei, Verkehrssituationen besser zu erfassen und darauf zu reagieren, indem visuelle Informationen mit verbalen Anweisungen oder Kontextinformationen kombiniert werden. Während die Leistungsfähigkeit multimodaler Modelle beeindruckend ist, gibt es nach wie vor erhebliche Herausforderungen. Die Trainingsdaten müssen sorgfältig kuratiert werden, um Verzerrungen zu minimieren und eine ausgewogene Repräsentation von verschiedenen Bildern und Texten zu gewährleisten. Zudem erfordern diese Modelle große Rechenkapazitäten und sind daher nicht ohne Weiteres in jeder Anwendung einsetzbar. Datenschutz und ethische Fragen spielen ebenfalls eine wichtige Rolle, da multimodale Systeme besonders tiefgehende und intime Informationen erfassen können.
Die Forschungslandschaft entwickelt sich rasant weiter. Die kontinuierliche Verbesserung von Architekturen, Trainingsstrategien und Datenqualität verspricht, multimodale KI-Modelle noch leistungsfähiger und anpassungsfähiger zu machen. Zudem werden zunehmend Standardisierungen und Benchmarks etabliert, die eine objektive Bewertung und Vergleichbarkeit der verschiedenen Ansätze ermöglichen. Dies fördert nicht nur die Transparenz, sondern erleichtert auch den Transfer von Forschungsergebnissen in praktische Anwendungen. Zusammenfassend lässt sich sagen, dass die Fusion von Vision und Sprache in multimodalen KI-Modellen einen bedeutenden Fortschritt darstellt.
Die Entwicklung von mehr als 125 unterschiedlichen Modellen zeigt die Vielfalt und Innovationskraft dieses Forschungsgebiets. Diese Systeme erweitern die Fähigkeiten künstlicher Intelligenz erheblich und eröffnen neue Wege für interaktive und kontextbewusste Anwendungen. Mit weiteren technischen Entwicklungen und einer verantwortungsvollen Handhabung stehen multimodale KI-Modelle im Zentrum der nächsten Generation intelligenter Technologien.