In der heutigen datengetriebenen Welt gewinnen effiziente Speicherlösungen immer mehr an Bedeutung. Insbesondere im Bereich der Datenanalyse steht die Geschwindigkeit bei der Verarbeitung großer Datenmengen im Vordergrund. Ein Konzept, das dabei immer wieder zur Sprache kommt, ist die sogenannte spaltenbasierte Speicherung oder auch Columnar Storage. Doch was genau verbirgt sich hinter diesem Begriff, warum ist er so populär und wie unterscheidet er sich vom herkömmlichen zeilenbasierten Speicher? Diese Fragen wollen wir im Folgenden ausführlich beantworten und so ein tieferes Verständnis für die essenziellen Grundlagen moderner Dateninfrastrukturen schaffen. Um das Wesen der spaltenorientierten Speicherung zu erfassen, ist es hilfreich, den Unterschied zum traditionellen, zeilenbasierten Ansatz zu verstehen.
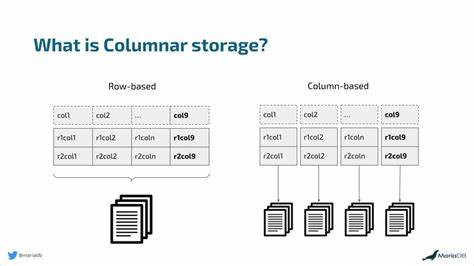
In klassischen relationalen Datenbanken werden Daten häufig zeilenweise gespeichert. Das bedeutet, jede Zeile in einer Tabelle repräsentiert einen Datensatz und alle Werte dieser Zeile werden zusammenhängend abgelegt. Beispielsweise speichert eine Tabelle mit Kundenbestellungen jede Bestellung komplett – von der Bestell-ID über das Produkt bis hin zum Umsatz – als einzelne Zeile. Diese Methode ist ideal für transaktionale Systeme, bei denen es vor allem darauf ankommt, komplette Datensätze schnell abzurufen oder zu ändern. Wird etwa eine neue Bestellung aufgegeben, so lässt sich der gesamte Datensatz in einem Schreibvorgang speichern, wodurch die Performance bei der Datenerfassung besonders effizient ist.
Dem gegenüber steht die spaltenbasierte Speicherung, bei der die Daten eines bestimmten Feldes kollektiv abgelegt werden. Anstatt alle Informationen einer einzelnen Bestellung als Zeile zu speichern, werden beispielsweise alle Bestell-IDs, alle Produktnamen, alle Bestelldaten und alle Umsätze in separaten Speicherbereichen aufbewahrt. Dieses Vorgehen ist insbesondere für analytische Abfragen optimiert, welche häufig nur auf einige wenige Spalten zugreifen. Fragen wie „Wie hoch war der durchschnittliche Umsatz im letzten Monat?“ oder „Wie oft wurde ein bestimmtes Produkt verkauft?“ lassen sich so deutlich schneller beantworten, da nur die relevanten Spalten geladen und verarbeitet werden müssen – die übrigen Daten bleiben unberührt. Das verringert die zu lesende Datenmenge erheblich und minimiert den Input/Output-Aufwand des Systems.
Ein weiterer entscheidender Vorteil der spaltenbasierten Speicherung ist die leistungsfähige Datenkompression. Weil in einer Spalte Daten vom gleichen Typ liegen – beispielsweise nur numerische Werte oder nur Datumsangaben – können Kompressionsalgorithmen wie Run-Length-Encoding, Dictionary-Encoding oder Delta-Encoding effizienter arbeiten. Run-Length-Encoding etwa speichert wiederholte Werte nur einmal zusammen mit der Anzahl der Wiederholungen, was bei homogenen Datenfeldern erhebliche Speicherersparnisse erzeugt. Dictionary-Encoding ersetzt wiederkehrende Werte durch kleinere Referenzschlüssel, wodurch die Datenmenge ebenso reduziert wird. Diese Kompressionsmethoden führen nicht nur zu geringeren Speicheranforderungen, sondern verbessern auch die Abfragegeschwindigkeit, da weniger Daten gelesen werden müssen.
Neben der Performance und Effizienz auf Seiten der Speicherung ermöglicht die Columnar-Architektur sogenannte vektorisierte Verarbeitungen. Dabei werden Operationen nicht Zeile für Zeile, sondern spaltenweise auf ganze Datenblöcke angewandt. Moderne Datenabfrage-Engines wie Apache Spark, DuckDB oder Presto nutzen diese Technik und setzen dabei SIMD-Prozessorinstruktionen (Single Instruction Multiple Data) ein, die dieselbe Rechenoperation simultan auf mehrere Datenwerte anwenden können. Dies führt zu einer noch schnelleren und ressourceneffizienteren Verarbeitung großer Datenvolumina. Auch die Parallelisierung profitiert maßgeblich von der spaltenweisen Speicherung.
Da jede Spalte unabhängig gespeichert ist, können unterschiedliche CPUs oder Knoten eines verteilten Systems gleichzeitig verschiedene Spalten laden und bearbeiten. Gerade bei sehr großen Datensätzen vermindert sich dadurch die Verarbeitungszeit erheblich, was in der Praxis vor allem bei analytischen Anwendungen mit komplexen Abfragen von großem Vorteil ist. Wenn wir auf die praktischen Umsetzungen der spaltenbasierten Speicherung blicken, treten Dateiformate wie Apache Parquet und Apache ORC besonders hervor. Parquet, ursprünglich von Twitter und Cloudera entwickelt, ist ein weitverbreitetes, spaltenorientiertes Format, das gezielt für Big Data Analytics optimiert wurde. Seine Architektur unterteilt Dateien in Row Groups, Column Chunks und Pages.
Row Groups stellen horizontale Partitionen dar – Bereiche von aufeinanderfolgenden Zeilen – innerhalb derer Daten spaltenweise als Column Chunks abgelegt sind. Die kleinste Einheit, die Page, ist dabei jeweils eine gefilterte und komprimierte Datenmenge einer Spalte. Diese Struktur erlaubt es Analytics-Engines, Teile der Datei gezielt zu lesen und andere Teile ohne Leseaufwand zu überspringen. Darüber hinaus nutzt Parquet beim Speichern fortschrittliche Hybrid-Kompressionsverfahren, die verschiedene Algorithmen kombinieren, um den Speicherbedarf weiter zu minimieren. Ähnlich wichtig ist das ORC-Format, das als Optimized Row Columnar-Dateiformat entstanden ist.
ORC wurde speziell für Hadoop-Ökosysteme mit Fokus auf starke Kompression und eingebettete Indexierung entwickelt, um schnelle analytische Abfragen zu ermöglichen. Die Datei ist in Stripes gegliedert – größere Blöcke von Daten, die selbständig komprimiert und indexiert werden. Durch detaillierte Metadaten und Fußzeilen ist es ORC möglich, viele Abfragen schon auf Dateiebene zu optimieren, indem nur relevante Datenblöcke gelesen werden. Die Vorteile dieser spaltenorientierten Dateiformate kommen bei großen Unternehmen, die mit enormen Datenmengen arbeiten, besonders zum Tragen. Beispielsweise hat Uber aufgrund des steigenden Datenvolumens seine Parquet-Dateien von Gzip- und Snappy-Kompression auf Zstandard (ZSTD) umgestellt.
Diese Änderung führte nicht nur zu einer Reduktion des Speicherbedarfs um bis zu 39 Prozent, sondern verbesserte auch die Abfragegeschwindigkeit, wodurch Rechenressourcen besser genutzt werden konnten. Zusätzlich konnten durch das Entfernen ungenutzter Spalten weitere Petabytes an Speicherplatz eingespart werden. Diese Optimierungen spiegeln die enorme Effizienz wider, die mit columnaren Speicherformaten und angepassten Kompressionsverfahren erzielt werden kann. Ein weiteres Beispiel ist Criteo, ein großer Akteur im Bereich Display-Retargeting, der täglich Milliarden von Events verarbeitet. Criteo wechselte von einem älteren RCFile-Format auf Parquet, was die Flexibilität steigerte und sowohl Speicherbedarf als auch Abfrageperformance optimierte.
Parquet ermöglichte hier eine nahtlose Integration in moderne Datenbearbeitungs-Engines und unterstützte die Skalierbarkeit für zukünftige Anforderungen. Allerdings ist es wichtig zu betonen, dass der Umstieg auf columnare Formate nicht für jedes Unternehmen oder jeden Anwendungsfall sinnvoll ist. Gerade bei kleinen Datenmengen oder Anwendungen mit vielen transaktionalen Schreibvorgängen kann der Mehrwert gering sein. Die Komplexität einer Umstellung sollte mit dem konkreten Nutzen maßvoll abgewogen werden, um Investitionen in Infrastruktur und Schulungen zu rechtfertigen. Zusammenfassend lässt sich sagen, dass Columnar Storage ein essentieller Baustein moderner Datenanalyseplattformen ist.
Durch die spaltenweise Speicherung profitieren analytische Workloads von einer drastischen Reduzierung der zu lesenden Datenmenge, effizienter Kompression und besserer Nutzung moderner CPU-Architekturen. In Verbindung mit Formaten wie Parquet und ORC werden diese Vorteile für riesige Datenmengen ideal nutzbar gemacht. Unternehmen mit großvolumigen Daten profitieren besonders von den Performance- und Kostenersparnissen, die sich aus columnaren Speicherlösungen ergeben. Gleichzeitig sollten Organisationen die Entscheidung für Columnar Storage auf Basis ihrer Datenstrategie und individuellen Anforderungen differenziert treffen, um optimale Ergebnisse im Datenbetrieb zu erzielen.