Im Zeitalter der Digitalisierung wächst das Volumen an erzeugten und gespeicherten Daten exponentiell. Dies betrifft besonders sicherheitstechnische Bereiche wie die Certificate Transparency (CT) Logs, welche eine zentrale Rolle bei der Prüfung und Sicherstellung von SSL-Zertifikaten im Web spielen. Die Herausforderung besteht darin, enorme Mengen an Datensätzen effizient zu speichern, zu verwalten und in Echtzeit abzufragen. Ein Unternehmen, das dieses Problem beispielhaft bewältigt, ist Merklemap. Ihr Ansatz bei der Skalierung zeigt, wie sich über 100 Milliarden Zeilen an Daten in einer einzigen PostgreSQL-Datenbank handhaben lassen – ein Meilenstein, der viele Mythen über relationales Datenbank-Management in einer so großen Dimension infrage stellt.
Die Kombination aus bewährter Software und moderner Hardware spielt dabei eine entscheidende Rolle. Die Wahl der richtigen Datenbanklösung bildet die Basis für den Erfolg im Bereich massiv skalierbarer Anwendungen. Während viele Entwickler auf verteilte NoSQL-Systeme oder spezialisierte Datenbanken für Big Data vertrauen, leistet PostgreSQL unter fachkundiger Optimierung erstaunliches. Merklemap setzte bewusst auf PostgreSQL, nicht zuletzt aufgrund seiner bewährten Stabilität, robusten ACID-Eigenschaften und einer Vielzahl von Funktionen, die insbesondere Integrität und Sicherheit der Daten gewährleisten. Diese Entscheidung ermöglicht es, auf einfache Weise strenge Datenhaltungsvorschriften einzuhalten und gleichzeitig durchdachte relationale Strukturen zum Einsatz zu bringen, die eine effiziente und konsistente Datenhaltung gewährleisten.
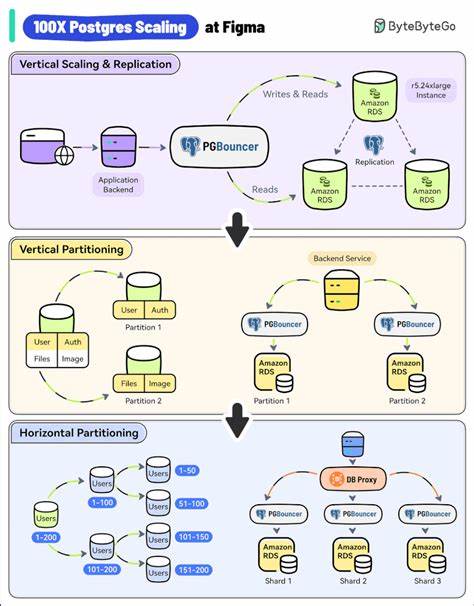
Eine wesentliche technische Herausforderung liegt in der Größe und dem Umfang der Datenbank. Die Menge von mehr als 100 Milliarden Datenzeilen und einem Speicherbedarf von ca. 20 Terabyte ist enorm. Doch Merklemap nutzt aktuelle Hochleistungs-Hardware, etwa AMD EPYC 9454P Prozessoren, NVMe-Flash-Speicher und großzügige Arbeitsspeicher von einem Terabyte pro Replikat, um die Datenbanken performancestark zu betreiben. Diese Hardware gewährleistet schnelle Zugriffe auf die Daten und entlastet durch parallele Verarbeitung die wesentlichen Ein- und Ausgabeprozesse.
Zwei Replikate sorgen darüber hinaus für Ausfallsicherheit und erleichtern Wartungen. Doch Hardware allein reicht nicht aus. Die Speicherung der Daten erfolgt auf ZFS-basiertem Speicher, welcher mit seiner Kompressionsfähigkeit und flexiblen Snapshot-Funktionalitäten besonders gut für große Datenmengen geeignet ist. Die Standardeinstellung von ZFS mit einer Recordgröße von 128 Kilobyte steht im Gegensatz zu PostgreSQLs traditionellem 8-Kilobyte-Page-Size. Ein solcher Unterschied kann beim Lesen und Schreiben zu erheblicher Mehrarbeit führen, da für jede Page-Operation ein ganzes ZFS-Record geladen werden muss, was eine sechzehnfache Verstärkung des Datenverkehrs verursacht.
Das typische Vorgehen, ZFS an die kleinere Datenbankseite anzupassen, würde jedoch den Kompressionsvorteil stark beeinträchtigen und unnötigen Verwaltungsaufwand erzeugen. Deshalb entschied sich Merklemap für eine gegenläufige Strategie und erhöhte die Blockgröße von PostgreSQL auf 32 Kilobyte mittels eines einfachen Konfigurationsschrittes bei der Kompilierung. So nähert sich die Datenbank der ZFS-Recordgröße an, was die Effizienz bei Lese- und Schreibvorgängen deutlich verbessert und Speicherplatz spart. Es handelt sich dabei um einen eher unkonventionellen Weg, der sich bei ihrer spezifischen Datenmenge als sehr effektiv herausstellte. Weiterhin optimiert Merklemap die Schema-Struktur hin zu einem append-only Design.
Das bedeutet, dass vorhandene Datensätze so gut wie nie aktualisiert oder gelöscht werden, sondern neue Informationen angehängt werden. Diese Strategie minimiert den Aufwand für die sogenannten VACUUM-Prozesse in PostgreSQL, die für das Aufräumen toter Datensätze und das Verhindern von Problemen mit Transaktions-IDs zuständig sind. VACUUM ist ein essenzielles System-Feature, das sonst erheblichen I/O-Aufwand verursachen kann, gerade bei derart großen Datenbeständen. Das append-only Prinzip bringt noch einen weiteren Vorteil mit sich: Es reduziert die Gefahr des Transaction-ID-Wraparounds, einem kritischen Zustand, bei dem die begrenzte Bitgröße von Transaktionsnummern zu Fehlern führen kann. Um diese Herausforderung zu managen, setzt Merklemap auf eine aggressive Autovacuum-Konfiguration, die in Kombination mit Monitoring-Mechanismen dynamisch die Schreiblast steuert.
So wird in Phasen hoher Belastung die Datenaufnahme verlangsamt und mit zunehmender Stabilität wieder hochgefahren. Ein verbreiteter Ratschlag in der PostgreSQL-Community zur Skalierung von großen Schreiblasten ist die Minimierung von Relationen, Constraints und Indexen zugunsten einer schnellen „Datenpipeline“. Merklemap hat diesen Weg jedoch bewusst nicht gewählt. Stattdessen stand für sie die Datenintegrität an erster Stelle, was zu einem wohlstrukturierten, normalisierten Datenbankschema führte. Dieses setzt auf robuste ACID-Transaktionen und komplexe Beziehungen, was zusätzliche Lese- und Commit-Operationen erfordert, jedoch die Qualität und Verlässlichkeit der Daten sichert – ein essenzieller Faktor bei sicherheitsrelevanten Anwendungen.
Um die Auswirkungen eines hohen Commit-Frequenz auf die Leistung zu dämpfen, nutzt Merklemap die Commit-Gruppierungsmechanismen von PostgreSQL mittels der Parameter commit_delay und commit_siblings. Diese Einstellungen erlauben es, mehrere Transaktionen zusammenzufassen und gemeinsam abzuschließen, wodurch die Systembelastung reduziert wird. Eine Feineinstellung dieser Parameter ermöglicht einen ausgewogenen Kompromiss zwischen Performance und Aktualität. Ein weiterer Aspekt, der bei konstant wachsender Datenbank häufig diskutiert wird, ist die Partitionierung. Konzeptuell kann die Aufteilung großer Tabellen in kleinere Partitionen Performancesteigerungen sowie Wartungserleichterungen ermöglichen.
Dennoch entdeckte das Merklemap-Team, dass die damit verbundenen Komplexitäten in Form von schwierigeren Constraints, Index- und Fremdschlüssel-Management sowie komplexerer Abfrageoptimierung ihre Vorteile überwiegen. Die ausgewogene Indexierung auf regulären Tabellen erwies sich als pragmatischer und wartungsfreundlicher Weg. Im Bereich Abfragen ist bei derart riesigen Datenmengen Disziplin gefragt. Willkürliche Scans sind nicht praktikabel. Merklemap verfolgt eine Strategie, bei der nur strikt über Indizes verfügbare Daten abgefragt und existierende Filtermechanismen rigoros eingehalten werden.
Durch den gezielten Einsatz von partiellen, abdeckenden und Ausdrucksindizes werden häufige Zugriffsmuster optimiert. Materialisierte Views unterstützen die Praxis, aggregierte Daten schnell bereitzustellen. Zudem kommen Richtlinien zum Query-Governoring zur Anwendung, die teure Abfragen während hoher Lastzeiten verhindern. Der eingesetzte Kompressionsalgorithmus für ZFS ist lz4, der eine gute Balance zwischen Performance und Kompressionsrate bietet. Obwohl modernere Verfahren wie zstd bessere Kompressionsraten erreichen können, ist lz4 aufgrund seiner geringen CPU-Belastung für Merklemap die bevorzugte Wahl.
Eine Kompressionsrate von ca. 2-fach stellt eine signifikante Einsparung des Speicherplatzes dar. Die Strategie im Bereich Datenaufnahme ist durch hohe Resilienz gekennzeichnet. Logs, von denen die Daten bezogen werden, sind zwar generell zuverlässig, unterliegen jedoch gelegentlichen Ausfällen oder Performanceproblemen. Merklemap operiert wie eine Suchmaschine mit einer ausgefeilten dynamischen Drosselung, die sich an der aktuellen System- und Log-Performance orientiert.
Sogenannte fail-fast und retry-mechanismen sichern die Nachholung verpasster Daten und sorgen für vollständige und konsistente Informationsbestände. Die Implementierung der Ingest-Worker basiert auf der asynchronen Tokio-Bibliothek von Rust, was die Verbindungskonzepte und Ressourcennutzung gegenüber klassischen synchronen Verfahren optimiert. Mit einer kleinen Anzahl von CPU-Kernen und begrenzten Verbindungen kann eine hohe Datenrate erzielt werden – bis zu acht Millionen Einträge pro Stunde – was die Effizienz und Skalierbarkeit der Lösung unterstreicht. Die enorme Datenmenge erklärt sich auch historisch: Merklemap hat von Anfang an die Daten der Certificate Transparency Logs aufgezeichnet, die seit ihrer Einführung kontinuierlich wachsen. Aktuelle Raten von etwa einer Million Zertifikaten pro Stunde summieren sich über Jahre zu den gegenwärtigen Hunderten Milliarden von Datensätzen.
Die Erfahrungen von Merklemap eröffnen wichtige Erkenntnisse für den Betrieb großer Datenbanken mit PostgreSQL: Die vermeintlichen Skalierungsgrenzen einer einzelnen relationalen Datenbank können durch gezielte Software- und Hardware-Optimierungen deutlich erweitert werden. Anstatt frühzeitig auf verteilte Systeme oder NoSQL-Datenbanken auszuweichen, lohnt es sich, das volle Potenzial vorhandener Technologien auszuschöpfen. Zudem zeigt der Fall Merklemap, dass das Festhalten an relationalen Modellen und Datenintegrität nicht zwangsläufig Leistungseinbußen bedeutet, wenn die Architektur sorgsam auf die Anforderungen angepasst wird. Indem Append-Only-Schemas, angepasste Parameter sowie robuste Indexierungs- und Monitoringsysteme kombiniert werden, entsteht ein performantes und verlässliches Rückgrat für Anwendungen mit extremen Datenmengen. Abschließend stellt Merklemap mit ihrer Lösung ein Beispiel dar, wie moderne Hardware verbunden mit kluger Softwarekonfiguration es ermöglicht, auch hochvolumige und sicherheitskritische Daten in einer einzigen Datenbank effektiv zu verwalten.
Für Branchen und Projekte, die vor ähnlichen Herausforderungen stehen, bieten die hier gefundenen Antworten wertvolle Orientierung und ermutigen dazu, nicht automatisch auf verteilte Systeme zu setzen, wenn relationale Datenbanken mit sauberer Architektur ans Ziel führen.