In der Welt der künstlichen Intelligenz und des maschinellen Lernens gewinnen große Sprachmodelle, sogenannte Large Language Models (LLMs), zunehmend an Bedeutung. Sie sind in der Lage, natürliche Sprache zu verstehen, zu verarbeiten und selbstständig Texte zu generieren. Während sie ursprünglich auf enormen Mengen an allgemeiner Textdatensätze trainiert wurden, stellt sich die Frage, ob und wie man diese Modelle auf spezifische Daten, die man ihnen „merken“ möchte, feinjustieren kann. Besonders relevant wird dies für Entwickler, die etwa große Codebasen besitzen und ein KI-Modell möchten, das spezielles Wissen daraus abruft, ohne ständig den gesamten Code in einen Prompt einfügen zu müssen. Ein solches Vorgehen könnte viele Prozesse optimieren und den Zugang zu komplexen Informationen erleichtern.
Doch wie lässt sich das in der Praxis umsetzen? Ist das Fine-Tuning von LLMs auf individuell gewünschte Daten ein gangbarer Weg, oder gibt es bessere Alternativen?Das Grundprinzip des Fine-Tunings besteht darin, ein bereits vortrainiertes Sprachmodell auf einem kleineren, spezifischeren Datensatz weiter zu trainieren. Auf diese Weise lernt das Modell, sich besser an die Charakteristika der neuen Daten anzupassen und relevantere Antworten zu generieren. In Theorie klingt das vielversprechend. Praktisch ist es jedoch mit einigen Herausforderungen verbunden. Zum einen sind große Sprachmodelle extrem komplex und benötigen für ein erfolgreiches Fine-Tuning erhebliche Rechenressourcen.
Dies betrifft vor allem neuere, leistungsfähigere Modelle wie GPT-3, GPT-4 oder deren Nachfolger. Die notwendigen GPUs und ausreichend Speicher sind nicht immer leicht zugänglich und können erhebliche Kosten verursachen. Außerdem erfordert das Fine-Tuning eine sorgfältige Kontrolle, um das Modell nicht durch Überanpassung zu degradieren oder seine allgemeinen Sprachfähigkeiten einzuschränken.Ein weiteres Problem ergibt sich durch die Größe der Daten, die oft verarbeitet werden sollen, wie beispielsweise sehr umfangreiche Codebasen, die aus Millionen von Zeilen bestehen können. Soll der gesamte Code wirklich in das Modell integriert werden, würde dies enorme Mengen an Trainingsdaten bedeuten und den Prozess verkomplizieren.
Auch die anschließende Leistung des Modells könnte beeinträchtigt werden, da es eventuell Schwierigkeiten hätte, zwischen allgemeinem Wissen und projektspezifischen Details zu unterscheiden.Eine pragmatischere Herangehensweise, die sich in der Praxis zunehmend etabliert, ist die Nutzung von sogenannten Retrieval-Augmented Generation (RAG) oder die Kombination von LLMs mit externen Wissensdatenbanken. Hierbei wird das Sprachmodell nicht direkt auf die spezifischen Daten trainiert, sondern arbeitet mit einem Such- oder Indexierungssystem zusammen. Wenn eine Anfrage gestellt wird, durchsucht dieses System die Datenbank oder den Code, extrahiert relevante Informationen und fügt sie kontextuell in den Prompt an das Modell ein. So werden die Einschränkungen der Kontextlänge umgangen, da nicht der gesamte Datenbestand im Prompt enthalten sein muss, sondern nur die tatsächlich relevanten Ausschnitte.
Das hat den großen Vorteil, dass die Modellparameter unangetastet bleiben und trotzdem gezielt auf hochspezifische Daten zugegriffen wird.Für Entwickler, die mit großen Codebasen arbeiten, bedeutet das, dass sie Ingestionswerkzeuge verwenden können, um den Quellcode in eine durchsuchbare Form zu bringen, wie zum Beispiel Vektor-Datenbanken auf Basis von Embeddings, die es ermöglichen, ähnlich zu bedeutende Textteile schnell zu finden. Diese Vektoren spiegeln die semantische Bedeutung der Daten wider und können dadurch sehr gezielt relevante Codeabschnitte anfragen. Das Sprachmodell erhält dann – ohne selbst fine-getuned zu sein – die Möglichkeit, Wissen aus dem Projekt abzurufen, ohne die Beschränkung der Token-Limits im Prompt zu sprengen.Das Fine-Tuning bleibt dennoch in bestimmten Szenarien sehr wertvoll, etwa wenn es darum geht, ein Modell an den Sprachstil eines Unternehmens anzupassen, firmenspezifische Formulierungen einzuarbeiten oder auf eine begrenzte Domäne hoch spezialisiert zu werden, wo die Datenmenge überschaubar ist.
Gerade hier lohnt sich die Investition in Rechenleistung und Zeit. Für sehr große oder ständig wachsende Datensätze ist die Kombination aus Retrieval und generativen Modellen allerdings effizienter und flexibler.Ein weiterer Aspekt ist die Verfügbarkeit von Open-Source-Modellen, die sich leichter selbst fine-tunen lassen als proprietäre. Mit Modellen wie LLaMA, Falcon oder Code LLMs, die eine offenere Lizenz besitzen, können mehr Freiräume für individuelles Training und Anpassungen genutzt werden. Diese Modelle sind oft kleiner und benötigen weniger Ressourcen, bieten aber mit der richtigen Architektur und Trainings-Engine sehr gute Ergebnisse für spezifische Anwendungsfälle.
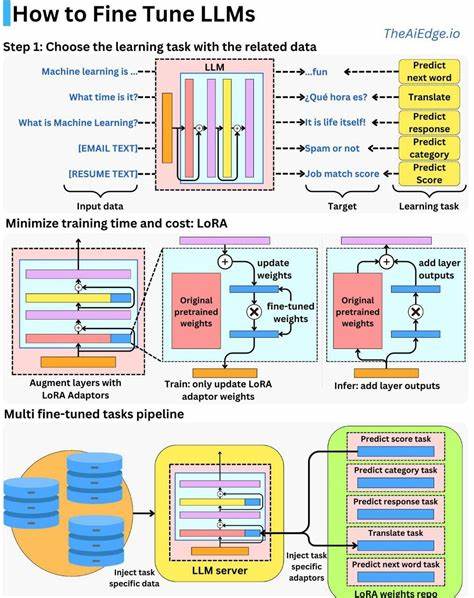
Darüber hinaus entwickelten sich auch Methoden wie LoRA (Low-Rank Adaptation), die das Fine-Tuning effizienter und ressourcenschonender gestalten, indem sie nur ausgewählte Teilbereiche der Modelparameter modifizieren. So ist es möglich, auf kleineren Datenmengen und mit reduzierter Rechenpower Anpassungen vorzunehmen, ohne ein komplettes Retraining durchzuführen. Dies eröffnet insbesondere Startups und kleineren Teams Möglichkeiten, personalisierte Sprachmodelle zu erzeugen, die auf spezielle Daten abgestimmt sind.Zusammengefasst lässt sich festhalten, dass Fine-Tuning auf individuelle Daten grundsätzlich möglich und in gewissen Fällen auch sinnvoll ist, aber nicht immer die optimale Herangehensweise darstellt. Gerade bei sehr großen Codebasen und komplexen Wissensbeständen ist der Einsatz hybrider Systeme aus Retrieval und generativer KI oft praktischer und nachhaltiger.
Diese hybride Lösung skaliert besser, spart Ressourcen und ist flexibler im Umgang mit ständig wechselnden Dateninhalten.Die Zukunft wird vermutlich noch weitere Innovationen bringen, wie das «In-Context Learning» oder gar spezialisierte KI-Hardware, die das Fine-Tuning großer Modelle effizienter ermöglichen. Für den Moment sollten Entwickler jedoch sorgfältig abwägen, welche Anwendungsfälle ein direktes Fine-Tuning wirklich erfordern und wann externe Wissensdatenbanken, semantische Suche und Retrieval-basierte Systeme die bessere Wahl sind. Nur so lassen sich die Stärken der KI effizient für individuelle Bedürfnisse ausschöpfen.