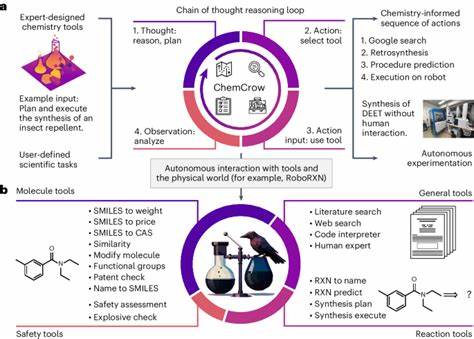
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat zuletzt in vielen Fachgebieten für Aufmerksamkeit gesorgt, darunter auch in der Chemie. Während diese Modelle ursprünglich hauptsächlich zur Verarbeitung und Generierung natürlicher Sprache entwickelt wurden, widmet sich die aktuelle Forschung zunehmend der Frage, inwiefern sie auch komplexe fachliche Aufgaben meistern können. Besonders im Bereich der Chemie, einem wissenschaftlichen Feld, das stark auf Wissen, präzises Denken und Experimentierpraxis angewiesen ist, stellt sich die Frage, wie gut LLMs im Vergleich zur menschlichen Expertise abschneiden und welche Rolle sie künftig im Arbeitsalltag von Chemikern spielen können. Im Zentrum der jüngsten Untersuchungen steht das Projekt ChemBench, eine automatisierte Bewertungsplattform, die speziell dafür entwickelt wurde, die chemischen Kenntnisse und die Fähigkeit zur logischen Schlussfolgerung moderner LLMs anhand eines umfangreichen Fragenkatalogs zu evaluieren. ChemBench umfasst mehr als 2700 Fragen, die von einfacheren gegenständlichen Fakten bis hin zu komplexen Denkaufgaben und intuitiven Bewertungen reichen.
Die Bandbreite dieser Fragen spiegelt dabei viele Themenbereiche der Chemie wider, von allgemeiner und technischer Chemie über Organische und Anorganische Chemie bis hin zu analytischen Fragestellungen. Die Ergebnisse von ChemBench offenbaren eine faszinierende Tatsache: Einige der besten aktuellen Sprachmodelle übertreffen im Durchschnitt die Leistung erfahrener Chemiker bei der Beantwortung eines breiten Spektrums chemischer Fragen deutlich. Dieses Resultat überrascht, ist jedoch mit Vorsicht zu interpretieren. Denn bei näherer Betrachtung zeigen die Modelle auch Schwächen bei grundlegenden Aufgaben und neigen dazu, ihre Antworten mit zu hoher Selbstsicherheit zu präsentieren. Die Grenzen ihres Wissens sind häufig schwer einzuschätzen, was wiederum die Bedeutung einer kritischen Begleitung durch menschliche Experten unterstreicht.
Die hohe Leistungsfähigkeit moderner LLMs resultiert aus ihrer Trainingsmethodik. Sie wurden mit enormen Mengen an Textdaten aus unterschiedlichsten Quellen versorgt, darunter wissenschaftliche Publikationen, Lehrmaterialien, Datenbanken und sogar altes Lehrbuchwissen. So speichern sie eine immense Wissensbasis und können Muster in Sprache und Information erkennen, die ihnen erlauben, eine Vielzahl von Fragen zu beantworten, ohne explizit für jede einzelne Fragestellung trainiert worden zu sein. Dies verleiht ihnen eine Flexibilität und Adaptivität, die viele Nutzer als „künstliche Allgemeine Intelligenz“ interpretieren. Trotz dieser beeindruckenden Fähigkeiten zeigt sich aber auch, dass LLMs insbesondere bei der Bearbeitung von Aufgaben, die tiefere strukturelle oder intuitive chemische Erkenntnisse erfordern, ins Stocken geraten.
Beispielsweise sind Fragen zur Interpretation von Kernspinresonanz-Spektren, umfangreichen Molekülstrukturen oder toxikologischen Bewertungen für die Maschinen oft eine Herausforderung. Das liegt unter anderem daran, dass die Modelle Molekülinformationen beispielsweise nur in einer textbasierten Notation, wie SMILES, vorliegen haben und diese nicht in der Art visueller oder räumlicher Vorstellungen verarbeiten können, wie es menschliche Chemiker tun. Ein weiterer wesentlicher Aspekt der Studie ist die Erkenntnis, dass viele LLMs Schwierigkeiten haben, ihre eigene Unsicherheit oder Fehlerquote richtig einzuschätzen. Sie geben oft sehr zuversichtlich falsche Antworten, was für praktische Anwendungen, bei denen Sicherheit und Verlässlichkeit essenziell sind, problematisch ist. Im Gegensatz dazu können menschliche Chemiker meist besser abschätzen, wann sie eine Antwort mit Vorbehalt geben und wann sie umfangreichere Recherche oder Experimente benötigen.
Die Untersuchung von ChemBench verdeutlicht zudem, dass offene Modelle wie Llama-3.1-405B-Instruct in einigen Fällen mit kommerziellen Produkten konkurrieren können, was eine spannende Entwicklung im Bereich der freien und offenen Forschung bedeutet. Gleichzeitig wird auch sichtbar, dass alle Modelle in ihrer Leistungsfähigkeit teilweise stark von der jeweiligen Chemiedisziplin abhängig sind. So schneiden sie in Bereichen wie technischer Chemie oder allgemeinen Fragestellungen oftmals besser ab als bei Spezialgebieten wie analytischer Chemie oder chemischer Sicherheit. Die Implikationen dieser Ergebnisse reichen weit.
Zum einen legen sie nahe, dass die Art und Weise, wie Chemie gelehrt und geprüft wird, überdacht werden muss. Bisherige Prüfungsformate, die sich auf das Abfragen von Fakten oder das Lösen standardisierter Aufgaben konzentrieren, reichen möglicherweise nicht mehr aus, um menschliche Kompetenzen gegenüber automatisierten Systemen abzugrenzen. Künftiger Lehrplan und Ausbildung sollten daher vermehrt auf kritisches Denken, tiefere Verständnisfähigkeit und die Bewertung von Unsicherheiten setzen. Zum anderen eröffnet die Kombination aus menschlichem Wissen und maschineller Schnelligkeit neue Chancen in der Forschung und Entwicklung. Chemiker könnten durch KI-gestützte Assistenten einen Zugriff auf einen weit größeren Fundus an Informationen und eine schnellere Interpretation komplexer Daten erhalten.
Sie könnten so nicht nur Routinefragen effizienter bearbeiten, sondern auch neue Hypothesen generieren und potenzielle Experimente vorschlagen, die sonst durch Zeit- oder Wissensmangel übersehen würden. Allerdings sind auch ethische und sicherheitstechnische Herausforderungen nicht zu vernachlässigen. Da LLMs aufgrund ihrer Trainingsdaten auch Informationen zur Synthese von gefährlichen Stoffen besitzen können, besteht das Risiko einer unerwünschten Nutzung. Zudem besteht das Problem der „Dual Use“-Technologie, bei der Werkzeuge für Umweltschutz oder Medizin gleichzeitig für schädliche Zwecke missbraucht werden können. Transparenz, sorgfältiges Monitoring und verantwortungsbewusste Verwendung sind daher unabdingbar.
Die ChemBench-Plattform stellt einen wichtigen Schritt dar, um solche Herausforderungen zu adressieren. Sie liefert eine strukturierte und standardisierte Möglichkeit zur Evaluierung und vergleichenden Beurteilung von Modellen und kann so als Maßstab dienen, der zukünftige Entwicklungen transparent macht. Darüber hinaus unterstützt sie die Integration verschiedener Modellsysteme und fördert die Zusammenarbeit zwischen KI-Forschern und Chemieexperten. Die Forschung zeigt auch, dass die Kombination von Sprachmodellen mit externen Tools, etwa Datenbanken oder Suchmaschinen, die Modellleistung weiter verbessern kann. Dennoch weist die Studie darauf hin, dass allein durch das Hinzufügen von Literaturquellen die Wissenslücken nicht vollständig geschlossen werden können.
Chemisch spezialisierte Datenbanken und strukturierte Informationen sind notwendig, um die Tiefe und Präzision der Modelle spürbar zu erhöhen. Abschließend lässt sich die Situation als eine noch junge, aber vielversprechende Symbiose zwischen menschlichem Expertenwissen und künstlicher Intelligenz beschreiben. Die derzeitigen LLMs sind beeindruckende Werkzeuge, die Chemiker unterstützen und teilweise sogar übertreffen können, insbesondere bei datenbasierter Wissensabfrage und Standardaufgaben. Doch die Notwendigkeit für kritisch denkende, erfahrene Menschen, die die Modelle steuern, hinterfragen und interpretieren, bleibt unverzichtbar. Die Zukunft der chemischen Wissenschaft wird daher wahrscheinlich von interaktiven Systemen geprägt sein, die menschliche Intuition und Erfahrung mit maschineller Kapazität und Geschwindigkeit vereinen.
Der Weg dorthin ist durch Herausforderungen in der Modellentwicklung, Bewertung und ethischer Anwendung gekennzeichnet, doch Tools wie ChemBench helfen, diese Hindernisse systematisch zu überwinden. Für Chemiker, Ausbilder und Entwickler bietet dies eine Chance, das eigene Fachgebiet durch moderne Techniken zu bereichern und zugleich die eigene Rolle in einem sich wandelnden wissenschaftlichen Umfeld neu zu definieren.