Der IBM-PC und sein charakteristischer Zeichensatz, bekannt als Code Page 437, haben eine bewegte Geschichte hinter sich, die bis in die frühen 1980er Jahre zurückreicht. Trotz ihrer zentralen Bedeutung in der Entwicklung moderner Computertechnik bleibt die genaue Definition und Umsetzung dieses Zeichensatzes für viele Nutzer und Entwickler ein Geheimnis. Die sogenannte „Verwirrung“ um Code Page 437 ist nicht nur ein technisches Detail aus der Vergangenheit, sondern beeinflusst auch heute noch diverse Systeme, Software-Anwendungen und digitale Kulturen. Dieser Text beleuchtet die Ursprünge, Besonderheiten und die anhaltenden Missverständnisse rund um den IBM-PC-Zeichensatz und erklärt, warum eine genaue Klärung wichtig ist – nicht nur für Historiker, sondern auch für alle, die sich mit moderner Softwareentwicklung und digitaler Textverarbeitung beschäftigen. Die Geburtsstunde des IBM-PC-Zeichensatzes Der IBM-PC wurde 1981 auf den Markt gebracht und stellte eine neue Ära der Personal Computer dar.
Wichtig war dabei nicht nur die Hardware, sondern auch die Frage, wie Texte, Symbole und grafische Elemente als Zeichen gespeichert, dargestellt und verarbeitet werden. Unterstützt wurde dies durch einen Zeichensatz, der auf der damals üblichen 8-Bit-Codierung beruhte. Code Page 437, auch unter dem Namen IBM-PC-8 oder OEM 437 bekannt, war die ursprüngliche Zeichentabelle, die den Bildschirmzeichen des IBM-PCs zugrunde lag. Diese Zeichentabelle enthielt neben den klassischen ASCII-Zeichen eine Vielzahl von Sonderzeichen, darunter grafische Elemente wie Rahmenlinien, diverse Symbol-Glyphen und mathematische Zeichen. Die Auswahl reflektierte den Bedarf an Spielcharakteren, Textverarbeitungshinweisen und speziellen Symbolen, die für damalige Anwendungen wie DOS-Programme, BBS-Systeme und einfache Grafikdarstellungen unverzichtbar waren.
Die Diskrepanz zwischen Spezifikation und Praxis Trotz ihrer elementaren Rolle gibt es bis heute keine offiziell umfassende, einheitliche Beschreibung des IBM-PC-Zeichensatzes, die von IBM selbst detailliert veröffentlicht wurde. Das offizielle „Technical Reference Manual“ enthielt zwar eine Tabelle mit den Glyphen, aber diese entsprach nicht immer exakt der tatsächlichen Darstellung auf den Bildschirmen. Die technische Umsetzung der Schriftzeichen entsprach insbesondere auf den frühen Videoausgabeadaptern (z.B. MDA und CGA Karte) teilweise nicht den dokumentierten Glyphen.
Verschiedene Hersteller, Software und Emulatoren legten die Zeichentabelle unterschiedlich aus, wodurch es zwangsläufig zu Verwirrungen kam. Viele der als Sonderzeichen verwendeten Glyphen hatten mehrere mögliche Interpretationen, die im Kontext nicht immer eindeutig waren. Zum Beispiel sehen sich das griechische kleine Beta und das lateinische scharfe S (ß) sehr ähnlich, sie sind jedoch unterschiedliche Zeichen mit unterschiedlichen Verwendungszwecken. Die ursprünglichen Designer der Zeichentabelle waren sich womöglich dessen nicht in jedem Fall bewusst, oder schufen bewusst eine hybride Form, die funktional war, aber nicht klar klassifiziert werden konnte. Die Persistenz der Verwirrung im digitalen Zeitalter Diese historische Unklarheit um den IBM-PC-Zeichensatz wirkt sich auch heute noch aus.
Moderne Betriebssysteme, Emulatoren und Software greifen häufig noch auf Code Page 437 zurück, besonders wenn es um die Darstellung von Kommandozeilen, Konsolen oder legacy-Daten geht. Selbst moderne Plattformen benutzen teilweise fehlerhafte Unicode-Mappings, welche nicht exakt die ursprünglichen IBM-PC-Glyphen abbilden. Unicode als universeller Zeichensatz wurde entwickelt, um unterschiedliche ältere Zeichensätze wie Code Page 437 unter einen Hut zu bringen. Das Ziel ist es, konsistente Zahlenwerte (Codepoints) für Symbole anzubieten, die weltweit und systemübergreifend lesbar und nutzbar sind. Allerdings sind einige Mappings für Code Page 437 in der heutigen Standard-Implementierung fehlerhaft oder ungenau, weil sie mehr auf optische Ähnlichkeiten setzen als auf die ursprünglichen Zeichenbedeutungen und Absichten.
Diese falschen Mappings führen beim Datenumwandeln und bei der Interpretation von Texten dazu, dass Zeichen falsch angezeigt oder falsch interpretiert werden können. Beispielsweise sind einige Musik-Symbole wie das Sechzehntelnoten-Glyphen falsch zugeordnet, was in elektronischen Musikeditoren oder in der Anzeige von ASCII-Art zutiefst störend sein kann. Weitere Verwirrungen gibt es bei richtungsweisenden Dreiecken, mathematischen Symbolen und Anführungszeichen, deren korrekte Unicode-Entsprechungen von den gebräuchlichen Windows-Mappings abweichen. Die Bedeutung der präzisen Zeichensatzdefinition Die genaue Zuordnung von IBM-PC-Zeichen zu Unicode ist nicht nur eine akademische Frage, sondern von praktischem Nutzen. Wer alte DOS-Programme emuliert, historische Dateien interpretiert oder ANSI-Art-Dateien (grafische Kunst aus Zeichen) korrekt darstellen möchte, benötigt die präziseste Mappingsituation.
Ebenso ist es für Entwickler von Font-Sets, Terminal-Emulatoren und POS-Software essentiell, dass die Zeichensatzdefinition auf Fakten und originalen Bitmaps basiert und nicht auf mutmaßlichen oder optischen Vereinfachungen. Eine zukünftige Korrektur der Fehler und die Offenlegung einer definitiven Mappings-Tabelle werden helfen, den digitalen Kulturschatz der frühen PC-Ära besser zu bewahren und für neue Systeme kompatibel zu machen. Solche Schritte fördern zudem das Verständnis von Historikern, Softwareingenieuren und Designern, die sich mit den Ursprüngen des digitalen Schriftsatzes beschäftigen. Mythen und Missverständnisse rund um Code Page 437 Neben technischen Unklarheiten gibt es auch viele Bezeichnungen und Begriffsverwendungen, die zur Verwirrung beitragen. Der IBM-PC-Zeichensatz wird oft fälschlicherweise als „ANSI Charakterset“ bezeichnet, was historisch betrachtet inkorrekt ist.
Der Begriff „ANSI“ stammt aus einem Dateitreiber namens ANSI.SYS, der bestimmte Steuersequenzen für die Textdarstellung auf DOS-Systemen ermöglichte. Diese Steuersequenzen basierten auf ANSI-Standards, doch der IBM-PC-Zeichensatz selbst hat nichts direkt mit den ANSI-Codes zu tun. Darüber hinaus haben Microsoft Windows-Benutzer den Ausdruck „ANSI Codepage“ für Windows-Zeichensätze wie Windows-1252 etabliert. Diese sind jedoch anders als der alte IBM-PC-Zeichensatz.
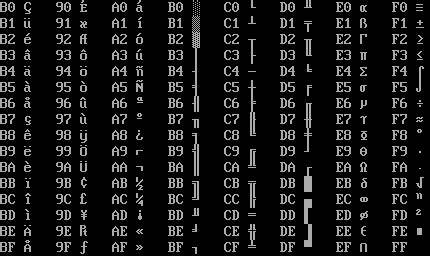
So entstanden zwei parallele Missverständnisse: der eine im DOS-/BBS-Umfeld und der andere im Windows-Zusammenhang. Das Verständnis und die richtige Zuordnung der Begriffe sind wichtig, um Fehlinterpretationen zu vermeiden, insbesondere bei der Entwicklung plattformübergreifender Software. Technische Details und Korrekturen – ein Blick auf Beispielcharaktere Ein Blick auf konkrete Zeichen illustriert die Schwierigkeiten bei der genauen Zuordnung. Das IBM-PC-Zeichen mit dem Hexcode 0x0D zum Beispiel ist ursprünglich ein Sechzehntelnoten-Symbol, das jedoch häufig fälschlich als Achtelnote interpretiert wird, weil Letzteres in modernen Schriftarten besser unterstützt wird. Andere Zeichen wie das „Broken Bar“ – ein senkrechter Strich mit Kerbe – werden oft einfach als senkrechter Strich dargestellt, obwohl die visuelle Differenz wichtig ist.
Ebenso ist das Haus-Symbol (0x7F), das im IBM-PC-Set als kleines Haus dargestellt wurde, vielfach mit dem griechischen Großbuchstaben Delta verwechselt worden. Die korrekte Darstellung spiegelt ein Haus wider und ist damit ein eindeutiges Symbol, das sich von anderen Zeichen unterscheiden lässt. Mathematische Symbole innerhalb von Code Page 437 wurden von vielen Mappings weiterhin falsch interpretiert, beispielsweise das leere Mengenzeichen oder verschiedene griechische Buchstaben, die wegen optischer Ähnlichkeit fehlerhaft zugeordnet wurden. Je tiefer man in die Zeichen hineinschaut, desto klarer wird die Notwendigkeit für eine ehrliche und faktisch korrekte Zuordnung, die auch den historischen Kontext berücksichtigt. Das Erbe von Code Page 437 in heutigen Systemen Obwohl Code Page 437 sein Alter von über vier Jahrzehnten trägt, ist die Zeichenkodierung nach wie vor präsent.
DOS-Schnittstellen, Konsolenanwendungen unter Windows, Linux-Konsolen, Terminalemulationen und historische Archivformate nutzen weiterhin den Umfang dieses Zeichensatzes. Die sogenannte ASCII-Kunst, die oft mit ANSI- oder Code Page 437-Glyphen erstellt wird, lebt von der korrekten Darstellung dieser Zeichen. Aktuelle Lösungen, die vor allem auf Unicode setzen, müssen daher die korrekten Mappings gewährleisten, um historische Daten originalgetreu zu bewahren und eine sinnvolle Weiterverarbeitung zu ermöglichen. Fontdesigner orientieren sich ebenfalls an der Original-Pixeldarstellung der IBM-MDA-Karte, um retro-kompatible Schriften und Darstellungen zu schaffen. Fazit und Ausblick Die Klärung der Verwirrung rund um den IBM-PC-Zeichensatz Code Page 437 ist ein wichtiger Schritt, um den technischen und kulturellen Wert dieser Symbolsammlung zu bewahren.