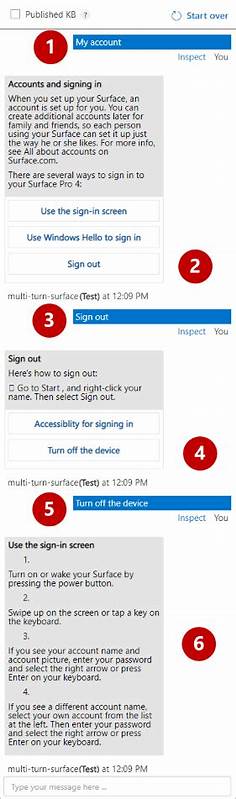
Die Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat einen Wendepunkt in der Künstlichen Intelligenz markiert. Von automatisierter Texterstellung über komplexe Analysen bis hin zu Chat- und Agentensystemen übernehmen LLMs eine zunehmend wichtige Rolle. Doch trotz des Fortschritts zeigt sich in der Praxis eine klar erkennbare Schwäche: LLMs verlieren häufig den roten Faden in mehrstufigen, also sogenannten multi-turn, Gesprächen. Dieses Phänomen stellt Entwickler wie Nutzer vor Herausforderungen und führt oft zu frustrierenden Ergebnissen. Es ist daher essenziell, die Ursachen dieses Verhaltens zu verstehen und Strategien zu dessen Überwindung zu entwickeln.
Untersuchungen aus jüngster Forschung belegen eine deutliche Leistungsminderung von LLMs in mehrstufigen Gesprächsszenarien. Während Modelle in einzelnen, klar formulierten Eingaben beeindruckende Genauigkeiten von über 90 Prozent erzielen, sinkt diese Rate bei fortlaufenden Dialogen auf etwa 60 Prozent. Die durchschnittliche Leistungsminderung über unterschiedliche Aufgaben und Modelle hinweg beträgt rund 39 Prozent, was die massive Komplexität widerspiegelt, die durch eine schrittweise Aufklärung von Anforderungen entsteht. Ursächlich für diesen Leistungsabfall ist vor allem eine stark erhöhte Unzuverlässigkeit. Die Modelle zeigen zwar nur eine moderate Verringerung in ihrer grundsätzlichen Fähigkeit (etwa 15 Prozent), doch ziehen mehrstufige Konversationen eine massive Schwankung in der Konsistenz nach sich.
Antworten sind unvorhersehbarer, ihre Qualität stellt sich zwischen besten und schlechtesten Resultaten als sehr inkonsistent dar. Besonders auffällig ist, dass hochperformante Modelle in Einzelschritten oft genauso unzuverlässig agieren wie im Grundsatz kleinere Modelle, sobald mehrere Gesprächsphasen hinzukommen. Das Kernproblem lässt sich vor allem auf fehlerhafte Annahmen während der Interaktion zurückführen. LLMs tendieren dazu, zu früh vollständige Lösungen anzubieten, ohne alle nötigen Informationen abgefragt zu haben. Dies führt zu überfrachteten oder falschen Antworten, die den weiteren Gesprächsverlauf negativ beeinflussen.
Die Modelle setzen zudem häufig auf ihre vorherigen — potentiell fehlerhaften — Ausgaben als Basis für neue Antworten, was Fehler akkumuliert und verstärkt. Ein weiteres Phänomen besteht darin, dass die Antworten meist sehr ausführlich ausfallen, was die Klarheit und Nachvollziehbarkeit der Kommunikation erschwert. Dadurch „verwässert“ sich der Kontext zunehmend, was zu noch mehr Missverständnissen führen kann. Darüber hinaus zeigen LLMs im Verlauf des Dialogs eine unangemessene Gewichtung der einzelnen Gesprächsabschnitte. Insbesondere wird den Anfangs- und Endphasen viel zu viel Bedeutung beigemessen, während wichtige Informationen, die in den mittleren Schritten gegeben werden, oft verloren gehen bzw.
nicht angemessen verarbeitet werden. Diese sogenannte „loss-in-the-middle“-Effekt verschärft die Probleme bei mehrstufigen Interaktionen. Trotz der inhärenten Komplexität dieses Verhaltens ist es bemerkenswert, dass der Effekt über Modellgrößen, Anbieter und verschiedene Aufgaben hinweg sehr robust auftritt. Selbst Spezialmodelle, die auf tiefergehendes Argumentieren und mehrstufige Deduktion ausgelegt sind, können die Probleme nicht vollständig eliminieren. Tests mit sogenannten „reasoning models“ zeigen zwar kleinere Verbesserungen, aber auch hier bleibt die Zuverlässigkeit keine Selbstverständlichkeit.
Versuche, den Herausforderungen mit systemseitigen Strategien zu begegnen, zeigen gemischte Erfolge. Ansätze wie die Wiederholung, also die explizite Zusammenfassung aller vorhergehenden Nutzeranweisungen bei jedem Schritt, können die Leistung geringfügig stabilisieren, bringen aber keine vollständige Lösung. Die Senkung der sogenannten „Temperatur“ (ein Parameter, der die Zufälligkeit der Generierung steuert) hilft ebenfalls nur begrenzt: Auch bei einer deterministischen Ausgabe (Temperatur Null) bleiben Inkonsistenzen bestehen. Dies weist darauf hin, dass das Problem tiefer liegt als nur in probabilistischen Antwortvariationen. Die Verwaltung des Kontexts und der Speichermechanismen über den Gesprächsverlauf wird als Schlüsselfaktor für eine nachhaltige Verbesserung betrachtet.
Optimierte Systeme, die Informationen strukturiert und effizient über mehrere Interaktionen hinweg speichern, können die Zuverlässigkeit in mehrstufigen Dialogen erhöhen. Hier sind jedoch sowohl technische als auch konzeptionelle Innovationen nötig, um die Herausforderung langfristig zu bewältigen. Für Nutzer bedeutet dies vor allem eines: Es ist ratsam, wenn immer möglich, alle Anforderungen und Informationen möglichst präzise in einem einzigen, vollständigen Prompt zusammenzufassen. Das schränkt zwar die natürliche Gesprächsdynamik etwas ein, stellt aber sicher, dass das Modell alle relevanten Daten unmittelbar vorliegen hat und seine Antwort maximal zielgerichtet erstellen kann. Wenn ein Gespräch dann doch einmal komplex wird oder vom Weg abkommt, empfiehlt es sich, eine neue Sitzung mit einer zusammengefassten Übersicht der bisherigen Kommunikation zu beginnen, um die Gesprächsbasis wieder zu stabilisieren.
Entwickler und Systembauer sollten den Fokus bei der Entwicklung von multi-turn-systemen stärker auf Verlässlichkeit legen und dabei weniger auf reine Spitzenleistung in Einzelschritten achten. Gerade bei komplexen Agentensystemen oder in Anwendungen, bei denen fehlerhafte Antworten gravierende Folgen haben können, ist eine robuste, konsistente Modellperformance von höchster Wichtigkeit. Abschließend lässt sich sagen, dass große Sprachmodelle zwar enorm leistungsfähig sind, aber im Umgang mit komplexen, sich entwickelnden Gesprächen weiterhin mit der Herausforderung kämpfen, den Kontext über mehrere Schritte präzise und konsistent zu bewahren. Dieses Verhalten ist bei den neuesten Modellen nicht verschwunden, sondern zeigt sich eher subtil und dennoch signifikant. Die erkenntnisreiche Untersuchung dieser Problematik liefert eine wertvolle Orientierung für Entwickler und Anwender gleichermaßen, um bessere, verlässlichere LLM-basierte Anwendungen zu gestalten und mögliche Fallstricke frühzeitig zu erkennen.
Die Zukunft wird zeigen, welche Fortschritte bei Kontextmanagement, Speichertechnologien und systemischer Integration möglich sind, um dieses fundamentale Problem der mehrstufigen Kommunikation mit KI-Modellen zu lösen. Bis dahin sind Bewusstsein, sorgfältige Planung und gezielte Anwendung essentiell, um die Interaktion mit LLMs so effektiv und vertrauenswürdig wie möglich zu gestalten.




![Hash Collisions and the Birthday Paradox [video]](/images/107D1194-52B5-40F2-BA92-98373B789CD5)