Tabellarische Daten sind in der Welt der Datenanalyse und des maschinellen Lernens allgegenwärtig. Von Finanz- und Gesundheitsdaten über Marketing-Daten bis hin zu wissenschaftlichen Messreihen liefern strukturierte, tabellarische Informationen die Grundlage für wichtige Entscheidungen. Trotz der Dominanz von Deep-Learning-Modellen bei Bild- und Sprachverarbeitung blieb die zuverlässige und effiziente Verarbeitung kleiner bis mittelgroßer tabellarischer Datensätze eine Herausforderung. Genau hier setzt TabPFN an – ein bahnbrechendes Foundation Model, das speziell zur Analyse tabellarischer Daten entwickelt wurde und bereits jetzt die Standards im maschinellen Lernen neu definiert.TabPFN, entwickelt von Prior Labs, ist ein transformatorbasiertes Modell, das kleine tabellarische Klassifikationsprobleme in Sekundenschnelle lösen kann.
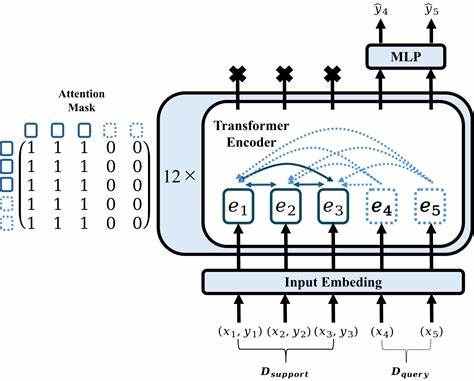
Es besticht durch seine unglaubliche Schnelligkeit und hohe Genauigkeit, die traditionelle Algorithmen wie Random Forests oder Gradient Boosting oft übertrifft. Die Besonderheit von TabPFN liegt in seinem Einsatzbereich: Es wurde für Datensätze mit bis zu 10.000 Zeilen optimiert, ein Bereich, in dem viele klassische Machine-Learning-Modelle entweder sehr lange Trainingszeiten benötigen oder nicht die gewünschte Genauigkeit liefern.Die Basis des Modells bildet ein Transformer-Netzwerk, das ursprünglich aus der Verarbeitung natürlicher Sprache bekannt ist. Durch eine neuartige Anpassung verarbeitet TabPFN jedoch tabellarische Daten effizienter als bisherige Ansätze.
Jedes Feature im Datensatz wird modelliert, so dass komplexe Wechselwirkungen zwischen Spalten berücksichtigt werden können, ohne auf umfangreiche Vorverarbeitung oder manuelle Feature-Engineering-Schritte angewiesen zu sein.Ein besonderer Vorteil von TabPFN ergibt sich aus der Schnelligkeit seiner Methodik kombiniert mit einem geringen Bedarf an Rechenressourcen. Obwohl das Modell von CUDA-optimierter PyTorch-Implementierung profitiert und die Nutzung von GPUs empfohlen wird, sind auch kleinere Datensätze auf CPUs bearbeitbar, was es zu einem flexiblen Werkzeug für verschiedene Umgebungen macht. Zudem können Anwender, die keine lokale GPU besitzen, die Cloud-basierte TabPFN Client API nutzen, um von der Leistungsfähigkeit des Modells zu profitieren.TabPFN ist jedoch nicht nur ein schneller Klassifikator.
Neben der klassischen Klassifikation bietet das Modell auch einen Regressor. Damit lassen sich numerische Vorhersageaufgaben, wie beispielsweise Schätzungen bei Immobilienpreisen oder die Prognose von medizinischen Messwerten, zuverlässig und präzise bearbeiten. Die Benutzerfreundlichkeit zeigt sich deutlich in der einfachen Integration in bestehende Python-Workflows mit bekannten Bibliotheken wie scikit-learn. Das Modell lässt sich mit wenigen Zeilen Code trainieren, bewerten und anwenden.Ein weiterer Meilenstein ist die Einführung von Post-Hoc-Ensembling über die AutoTabPFN-Klassen.
Hier werden mehrere TabPFN-Modelle kombiniert, um die Performance und Robustheit weiter zu steigern. Dieses Verfahren bietet insbesondere für kritische Anwendungsfälle einen deutlichen Vorteil, da es die Modellvariance reduziert und die Vorhersagen stabiler und aussagekräftiger macht.Die TabPFN-Erweiterungen bieten ein umfassendes Ökosystem mit vielfältigen Tools für ExpertInnen und EntwicklerInnen. Unter anderem ermöglicht die Integration von SHAP-Erklärungen tiefgreifende Interpretierbarkeit, was gerade im regulatorisch sensiblen Kontext von Medizin oder Finanzen von unschätzbarem Wert ist. Auch die Fähigkeit, mit Ausreißern umzugehen oder synthetische tabellarische Daten generieren zu können, erweitert die Einsatzmöglichkeiten erheblich.
Hybridmodelle, die traditionelle Ansätze wie Random Forest mit TabPFN kombinieren, schaffen optimale Voraussetzungen für verschiedenste Datenstrukturen und -verteilungen.Hinsichtlich der technischen Voraussetzungen empfiehlt sich aufgrund der hohen Performance ein Rechner mit GPU-Unterstützung. Selbst ältere GPUs mit etwa acht Gigabyte VRAM sind ausreichend, für größere Datensätze mit bis zu 16 GB VRAM ausgestattet werden sollte. Für NutzerInnen ohne eigene Hardware steht eine kostenfreie Hosted Inference zur Verfügung, sodass der Zugang zu diesen leistungsfähigen Modellen breit ermöglicht wird.TabPFN bewältigt auch Herausforderungen, die viele andere Modelle vor Probleme stellen.
Beispielsweise kann es mit fehlenden Werten sorgenfrei umgehen und benötigt keine komplexen Imputationsschritte. Im Gegensatz zu vielen anderen Algorithmen erfordert TabPFN keine aufwändigen Vorabtransformationen der Eingabedaten wie One-Hot-Encoding bei kategorialen Variablen. Dies ermöglicht eine deutlich einfachere und schnellere Vorbereitung der Daten.Das Team von Prior Labs veröffentlicht regelmäßig Updates und Verbesserungen, was in der aktiven Community und dem Open-Source-Charakter des Projekts widerspiegelt wird. Außerdem existieren umfassende Tutorials und Dokumentationen, die den Einstieg erleichtern und professionelle NutzerInnen die Anpassung an spezifische Anwendungsfälle ermöglichen.
Aufgrund seines innovativen Ansatzes wurde TabPFN bereits in renommierten wissenschaftlichen Publikationen vorgestellt und findet zunehmend Eingang in kommerzielle Lösungen. Die Kombination aus wissenschaftlicher Tiefe, praktischer Effizienz und breiter Anwendbarkeit macht es zu einem der spannendsten Werkzeuge im Bereich des maschinellen Lernens tabellarischer Daten.In Zukunft wird erwartet, dass TabPFN und seine Erweiterungen noch stärker in verschiedene Branchen Einzug halten. Besonders in Bereichen wie der Medizin, wo präzise Vorhersagen bei vergleichsweise kleinen Datenmengen essenziell sind, aber auch im Finanzwesen, bei Marketing-Analysen oder der technischen Prozessoptimierung, bietet TabPFN neue Perspektiven. Durch die Möglichkeit, Modelle schnell zu trainieren und anzupassen, können Unternehmen agiler werden und fundierte Entscheidungen auf Basis data-driven Insights treffen.
Zusammenfassend lässt sich sagen, dass TabPFN die Brücke schlägt zwischen den hochkomplexen, oft schwer interpretierbaren Deep-Learning-Modellen und den klassischen, aber teilweise langsamen oder weniger präzisen Machine-Learning-Methoden für tabellarische Daten. Es bietet eine skalierbare, zugängliche und hochperformante Lösung, die gerade für den wachsenden Bedarf an automatisierten, schnellen und zuverlässigen Datenanalysen maßgeschneidert ist. Wer im Bereich der tabellarischen Datenverarbeitung die Nase vorn haben möchte, sollte TabPFN definitiv auf dem Radar haben.