Die rasante Entwicklung künstlicher Intelligenz hat in den letzten Jahren besonders im Bereich der großen Sprachmodelle (LLMs) für zunehmend viel Aufmerksamkeit gesorgt. Diese Systeme, die auf der Verarbeitung gigantischer Datenmengen aus Text basieren, zeigen beeindruckende Fähigkeiten in der Erzeugung von natürlichsprachlichen Antworten, der Interpretation komplexer Fragestellungen und auch der Durchführung von Aufgaben, für die sie nicht explizit trainiert wurden. Besonders im Bereich der Chemie stellen sich hierbei spannende Fragen: Wie gut sind solche Sprachmodelle wirklich in chemischem Wissen und Denken? Können sie mit der Expertise menschlicher Chemiker mithalten? Was bedeutet das für Forschung, Ausbildung und die Sicherheit im Umgang mit chemischen Substanzen? Eine neue Studie und der entwickelte Evaluationsrahmen ChemBench liefern dazu wertvolle Einblicke. Große Sprachmodelle und ihre Rolle in der Chemie LLMs sind Maschinenlernmodelle, die mithilfe riesiger Textdatensätze trainiert wurden, um Texte zu verstehen und zu generieren. Durch das sogenannte „skaling“ – das Vergrößern der Modellgröße und des Trainingsdatensatzes – haben sich ihre Fähigkeiten drastisch erweitert.
Sie bestehen nicht nur darauf, Worte und Sätze zu vervollständigen, sondern können zunehmend auch komplexe Aufgaben lösen, darunter das Bestehen professioneller Prüfungen, wie zum Beispiel die US-Medical-License-Exams, und sie können chemische Reaktionen entwerfen oder sogar automatisierte Laborexperimente unterstützen, wenn sie mit weiteren Tools verbunden werden. Das chemische Wissen von LLMs wurzelt dabei größtenteils in wissenschaftlichen Texten – Publikationen, Lehrbüchern, Patenten und Datenbanken. Diese Informationsbasis macht sie zu vielversprechenden Werkzeugen für die Chemie, weil die Experten viele ihrer Erkenntnisse aus der Interpretation solcher Texte ziehen und nicht nur aus numerischen Datensätzen. Doch trotz dieser Fortschritte gab es lange Zeit nur wenige systematische Vergleiche zwischen der Leistung von LLMs und der von echten Chemikern. Hier setzt das Projekt ChemBench an, das eine umfassende Benchmark mit mehr als 2700 Fragen entwickelt hat, die das chemische Wissen, die Rechenfähigkeiten, das Verständnis und die Intuition abdecken.
ChemBench – Ein neuer Standard zur Bewertung chemischer Kompetenz von Modellen Die eigens entwickelte Plattform ChemBench stellt eine Automatisierungslösung zur Evaluierung von Sprachmodellen bereit. Das Corpus der Benchmark-Fragen wurde aus verschiedensten Quellen kuratiert: von manuellen, eigens erstellten Fragen über Aufgaben aus Universitätsprüfungen bis hin zu semi-automatisch generierten Fragen aus spezialisierten Datensätzen. Dabei wurden alle Fragen von Chemieexperten auf Korrektheit geprüft. ChemBench geht bewusst über die sonst üblichen Multiple-Choice-Fragen hinaus und enthält auch offene Fragen, die der Wirklichkeit von Forschung und Ausbildung näherkommen. Die Fragen decken ein breites Spektrum an Chemiefachgebieten ab – von Allgemein- und Organischer bis hin zu Analytischer und Technischer Chemie.
Dabei werden zudem verschiedene Fähigkeiten geprüft: reines Faktenwissen, komplexes logisches Denken, mathematische Berechnungen und chemische Intuition. Ein kleines Teilset namens ChemBench-Mini bietet eine kompakte, dennoch vielseitige Auswahl von 236 Fragen für schnellere Testläufe an. Ein Teil der Benchmark wurde zudem von menschlichen Chemikern gelöst – teils mit Hilfsmitteln wie dem Internet – um eine realitätsnahe Vergleichsbasis zu bieten. Ergebnisse: Überlegenheit großer Sprachmodelle in vielen Aufgaben Die Evaluierung mehrerer führender LLMs zeigte, dass die Spitzenmodelle nicht nur durchschnittliche Chemiker, sondern sogar die besten menschlichen Fachleute in dieser Studie übertroffen haben. So erzielte beispielsweise das Modell o1-preview in der Gesamtwertung fast doppelt so viele korrekte Antworten wie der beste der befragten Experten.
Dies ist beachtlich, da die menschlichen Teilnehmer teils ebenfalls auf Hilfsmittel zurückgreifen durften. Auch offen zugängliche, nicht proprietäre LLMs wie die Version 3.1 von Llama erzielten eine Leistungsfähigkeit, die mit Spitzenmodellen mithalten konnte. Das deutet darauf hin, dass Open-Source-Modelle für die chemische Forschung zunehmend relevant werden können. Gleichzeitig zeigen die Ergebnisse, dass die Modelle mit speziellen Wissensgebieten wie der Toxikologie oder analytischer Chemie Probleme hatten.
Besonders schwierig waren Fragen zur Interpretation von NMR-Spektren, etwa die Bestimmung der Anzahl unterschiedlicher Signale. Die Modelle mussten hierfür aus der reinen Textform (z.B. SMILES-Aufzeichnungen), die für Menschen weniger intuitiv ist als eine graphische Darstellung, auf komplexe molekulare Strukturen schließen. Ein weiteres Defizit ergab sich bei der Abschätzung von chemischer Präferenz, also der Wahl zwischen zwei Molekülen auf Basis von Erfahrung und Intuition, wie sie etwa in der Wirkstoffforschung gebraucht wird.
Modelle rangierten hier oft nur knapp über Zufall, was zeigt, dass das Erfassen solcher subjektiv-qualitativer Entscheidungen noch wenig entwickelt ist. Schwierigkeiten bei Faktenwissen und Selbstbewertung Interessanterweise offenbaren die Tests Defizite bei der reinen Wissensspeicherung. Bei faktenintensiven Fragen, etwa zu Sicherheits- und Gefahrstoffkennzeichnungen, zeigten die Modelle Schwächen, obwohl diese Informationen theoretisch in den Trainingsdaten enthalten sein könnten. Ein Grund ist, dass manche Datenbanken und Fachinformationen nicht frei zugänglich oder in den Trainingssets wenig vertreten sind. Auch die Fähigkeit, ihre eigenen Antworten einzuschätzen, also eine angemessene Vertrauensbewertung vorzunehmen, zeigten LLMs bislang nur unzureichend.
Dies kann in der Praxis eine Gefahr darstellen, da falsche Antworten mit zu hoher Sicherheit ausgegeben werden. Menschliche Nutzer sollten sich dessen bewusst sein und Antworten stets kritisch hinterfragen. Auswirkungen auf Forschung, Lehre und Sicherheit Die Tatsache, dass moderne LLMs in bestimmten chemischen Aufgaben Superhuman-Performance erbringen, könnte weitreichende Konsequenzen für die chemische Wissenschaft haben. In der Forschung eröffnen intelligente Assistenten Möglichkeiten, große Mengen an Literatur effizient zu durchforsten, Hypothesen zu generieren und sogar Vorschläge für neue Experimente oder Synthesewege zu erarbeiten. In der Ausbildung hingegen stellt sich die Frage, wie Lehrinhalte und Prüfungsformen künftig gestaltet sein müssen.
Da Sprachmodelle Faktenwissen meist besser reproduzieren als Menschen, wird die Vermittlung und Prüfung von bloßem Auswendiglernen weniger relevant. Stattdessen gewinnt das Fördern von kritischem Denken, komplexem Problemlösen und experimenteller Intuition an Bedeutung. Ein ebenso wichtiger Aspekt ist die Sicherheit im Umgang mit Chemikalien. Unzuverlässige oder übermäßig selbstbewusste Antworten zu Gefahren können Schäden verursachen, zumal auch Laien häufig Sprachmodelle zu Rate ziehen. Eine verstärkte Aufklärung und die Entwicklung sicherheitsbewusster Lösungsansätze im Bereich der KI sind daher essenziell.
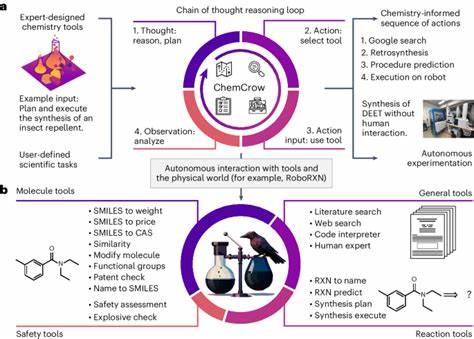
Perspektiven und Herausforderungen für die Weiterentwicklung Die Studie und ChemBench setzen einen neuen Maßstab für die Evaluierung chemischer Sprachmodelle. Sichtbar wird dabei eine ambivalente Situation: Große Sprachmodelle sind in vielen Bereichen bereits exzellent, gleichzeitig bleibt eine wichtige Lücke im Verständnis und Umgang mit komplexen chemischen Strukturen, Sicherheitsaspekten und subjektiven Präferenzen. Eine vielversprechende Richtung ist die Integration von LLMs mit spezialisierten Datenbanken, wie etwa PubChem oder Gefahrstoffdatenbanken, um die Wissensbasis zu erweitern. Auch die Kombination mit agentenbasierten Systemen, die Suchfunktionen, Kalkulationen oder grafische Darstellung einbinden, kann die Leistungsfähigkeit steigern. Darüber hinaus gewinnt die Feinabstimmung von Modellen auf chemiespezifische Aufgaben (Fein- oder Transferlearning) stark an Bedeutung.
Ebenso sollten zukünftige Modelle besser in der Lage sein, Unsicherheiten und Grenzen ihrer Antworten auszudrücken, womit die Vertrauenswürdigkeit signifikant erhöht werden kann. Schließlich zeigt sich auch, dass der Fortschritt der LLMs nach wie vor stark von Kosten und Ressourcen abhängt. Das Problem hoher Rechen- und Anwendungskosten könnte durch optimierte, kleinere aber spezialisierte Modelle teilweise ausgeglichen werden, wie die vergleichbare Leistung von Open-Source-Systemen nahelegt. Fazit Die Analyse des ChemBench-Benchmarks und der Vergleich mit Chemikerexpertise verweist auf ein spannendes Verhältnis zwischen Mensch und Maschine in der Chemie. Moderne große Sprachmodelle sind in der Lage, viele Aufgaben schneller und in großer Breite zu bearbeiten als einzelne Experten.