Maschinelles Lernen hat sich in den letzten Jahren als wesentliche Technologie in vielen Bereichen etabliert. Besonders im Bereich der Bild- und Spracherkennung, medizinischen Diagnosen oder automatisierten Entscheidungsfindung zeigt es beeindruckende Ergebnisse. Doch ein zentrales Problem vieler Machine-Learning-Modelle ist die Verfügbarkeit von echten, qualitativ hochwertigen Labels. Diese „wahren Labels“ sind notwendig, um die Modelle zu trainieren und zu validieren. In der Praxis ist es jedoch häufig der Fall, dass solche Labels teuer, zeitaufwendig oder schlichtweg nicht verfügbar sind.
Unternehmen oder Forschungsteams stehen so oft vor der Herausforderung, dass sie zwar große Mengen an Rohdaten besitzen, jedoch keine präzise Beschriftung der Datenpunkte vorliegt. Das erschwert die Anwendung konventioneller überwachter Lernmodelle erheblich. Genau hier setzt ein innovativer Ansatz an, der mit unsicheren Heuristiken und sogenannten schwachen Labels arbeitet und in den letzten Jahren zunehmend an Bedeutung gewonnen hat. Der methodische Durchbruch, den die sogenannte Datenprogrammierung (Data Programming) bietet, ist es, Maschinen das Lernen auch ohne wahrheitsgetreue Labels zu ermöglichen. Statt sich nur auf verlässliche, von Experten erstellte Klassifikationen zu verlassen, nutzt dieser Ansatz „labeling functions“ – also programmierte Heuristiken oder Regeln – welche auf den Rohdaten operieren und dabei mit einer gewissen Unsicherheit Vorhersagen treffen.
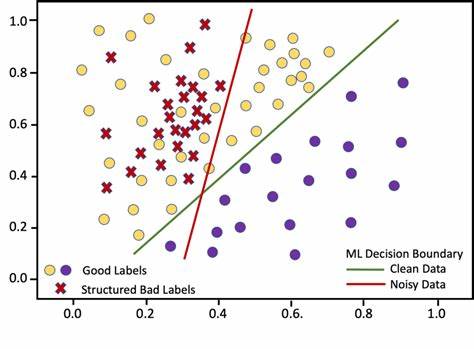
Diese Funktionen können auf verschiedensten Domänenwissen beruhen, beispielsweise Schwellenwerten für medizinische Messwerte oder linguistischen Regeln bei Textdaten. Wichtig zu verstehen ist, dass solche labeling functions nicht nur Vorhersagen liefern, sondern auch „abstainieren“ können, das heißt sie können sich dafür entscheiden, bei bestimmten Beispielen keine Aussage zu treffen. Dies ist ein großer Vorteil, da Funktionen nicht gezwungen sind, bei jedem Datenpunkt ein Label zu vergeben und somit weniger fehleranfällig sind. Die Labels, die sie erzeugen, können verschieden zuverlässig sein: Manche Heuristiken treffen häufiger zu, andere sind ungenauer oder gelten nur in speziellen Fällen. Ziel des Verfahrens ist es, trotz dieses Rauschens in den Heuristiken die zugrundeliegenden wahren Labels statistisch zu rekonstruieren.
Die mathematische Grundlage beruht auf einer Maximum-Likelihood-Schätzung, die die Wahrscheinlichkeitsverteilung der beobachteten Labels der heuristischen Funktionen in Bezug auf die unbekannten wahren Labels modelliert. Dabei werden zwei Parameter für jede labeling function geschätzt: Die Rate, mit der sie abstainiert, und ihre Genauigkeit, also die Wahrscheinlichkeit, dass sie korrekt das wahre Label trifft, wenn sie eine Aussage trifft. Unter der Annahme, dass diese Funktionen bedingt unabhängig voneinander sind, lässt sich so eine verborgene Variable – das wahre Label – inferieren. Dies resultiert schließlich in sogenannten weichen Labels oder probabilistischen Scores, die angeben, mit welcher Wahrscheinlichkeit ein Datenpunkt zu einer bestimmten Klasse gehört. Diese weichgewichteten Labels können direkt weiterverwendet werden, um traditionelle Machine-Learning-Modelle zu trainieren.
Man kann beispielsweise ein logistisches Regressionsmodell nehmen oder eine lineare Wahrscheinlichkeitsschätzung durchführen. Der Clou hierbei ist, dass das Modell nicht auf Einzel-Labels trainiert wird, die entweder richtig oder falsch sind, sondern auf probabilistischen Zuständen, die die Unsicherheit widerspiegeln. Durch den Einsatz von Regularisierungsmethoden wie der L2-Strafe (Ridge Regression) wird verhindert, dass Modelle durch die inhärente Unsicherheit überfitten. Die Gewichtungen der Modelle tendieren dazu, durch diese Methoden robuster gegenüber fehlerhaften Heuristiken zu werden. Ein exemplarisches Beispiel stammt aus dem medizinischen Bereich, in dem ein Datensatz zur Brustkrebsdiagnose mittels der beschriebenen Vorgehensweise analysiert wurde.
Hierbei wurden verschiedenartige heuristische Regeln definiert, die auf charakteristischen medizinischen Merkmalen wie Zellgröße, Nukleus-Eigenschaften und Zellteilung basierten. Die Heuristiken enthielten bewusst auch Bereiche, in denen keine Vorhersage getroffen wurde, um Unsicherheit zu modellieren. Nach der Schätzung der Wahrscheinlichkeitsparameter für jede Heuristik und der Berechnung der soft labels wurde ein einfaches lineares Modell trainiert, das im Anschluss für Klassifikationen verwendet wurde. Das Ergebnis zeigte eine hohe Genauigkeit mit einer präzisen Trennung zwischen gutartigen und bösartigen Fällen, obwohl keine echten Labels während des Lernprozesses zugrunde lagen. Diese Herangehensweise eröffnet viele praktische Vorteile.
Zum einen reduziert sich der Aufwand für die manuelle Kennzeichnung großer Datenbestände drastisch. Expertinnen und Experten müssen nicht jeden einzelnen Fall markieren, sondern können ihr Wissen in Form von Regeln und Heuristiken einbringen, die flexibel angepasst werden können. Zudem ermöglicht der Ansatz eine Erweiterung der Trainingsdaten, da Regeln unkompliziert neue Datenporben beschreiben können. Für Unternehmen mit großen Rohdatensätzen und begrenztem Labelbudget ist dies eine erhebliche Erleichterung. Weiterhin ist die Methode flexibel genug, um im semi-supervised Kontext eingebettet zu werden, wann immer einige wenige wahre Label vorliegen.
Diese können direkt in die Maximum-Likelihood-Schätzung mit eingebracht werden, um die Parameter noch robuster und besser zu schätzen. Die Kombination aus echten Labels und schwachen Heuristiken kann so die Modellqualität signifikant steigern. Allerdings gibt es auch Herausforderungen und Limitationen. Die Unabhängigkeitsannahme der labeling functions ist oft unrealistisch, da viele Heuristiken auf ähnlichen Merkmalen basieren oder korrelierte Fehler erzeugen können. Mehrschichtige Modelle, die beispielsweise Markov Random Fields oder faktorisierte Graphmodelle einsetzen, können solche Abhängigkeiten modellieren, sind aber rechnerisch aufwändiger.
Zudem liegt je nach Datenlage und Heuristik-Qualität eine gewisse Unsicherheit in den Schätzungen vor, die berücksichtigt werden sollte. Im technologischen Ökosystem gibt es bereits Implementierungen, welche die Konzepte der Datenprogrammierung nutzbar machen. Besonders bekannt wurde das Open-Source-Framework Snorkel, das viele Mechanismen bereitstellt, um labeling functions zu formulieren, zu evaluieren und die parametrisierte Labelgenerierung zu optimieren. Solche Tools erleichtern die praktische Anwendung für Data Scientists erheblich. Das Prinzip, Machine Learning neu zu denken – weg von der Abhängigkeit von teuren, oft limitierten echten Labels hin zu einer Kombination heuristischer Unsicherheiten und statistischer Modellierung – stellt einen Paradigmenwechsel dar.
Es demokratisiert den Zugang zu brauchbaren Trainingsdaten für komplexe Probleme und bietet gleichzeitig eine robuste Grundlage, um Modelle auf heterogenen, realitätsnahen Datensätzen zu trainieren. Wer sich mit den theoretischen und praktischen Aspekten dieser Methode auseinandersetzt, kann sowohl in der Forschung als auch in der Produktentwicklung von smarteren, effizienteren Machine-Learning-Lösungen profitieren. Gerade in Branchen mit hohem Labelbedarf und teurer Annotation öffnet sich hier eine Perspektive, nachhaltige und leistungsfähige Modelle auch ohne vollständige Labelverfügbarkeit zu realisieren. Zusammenfassend lässt sich sagen, dass das maschinelle Lernen ohne echte Labels mithilfe von unsicheren Heuristiken und Datenprogrammierung viel Potenzial für künftige Anwendungen birgt. Die Kombination von domänenspezifischem Wissen in Form von labeling functions mit statistischer Modellierung eröffnet neue Wege, um große Datenmengen nutzbar zu machen.
Innovative Frameworks und Algorithmen unterstützen diesen Ansatz, der gerade in datengetriebenen Branchen zunehmend an Bedeutung gewinnen wird.