In einer Welt, in der Mehrkernprozessoren und parallele Verarbeitung die Norm sind, stößt die herkömmliche Synchronisation von Threads schnell an Grenzen. Insbesondere beim Zugriff auf gemeinsame Ressourcen zeigt sich, dass einfache Mutexe oder klassische Read-Write-Locks nicht immer die erwartete Leistung bringen. Hier kommen linear skalierbare Read-Write Locks ins Spiel, die das Potenzial besitzen, die Leistung in Mehrkernumgebungen erheblich zu verbessern. Doch was verbirgt sich genau hinter diesem Konzept, welche technischen Herausforderungen gibt es und wie wird das Problem der sogenannten Cacheline Pingpong-Effekte gelöst? Das wollen wir im Folgenden eingehend betrachten. Ein klassischer Read-Write Lock stellt sicher, dass viele Reader gleichzeitig auf eine Ressource zugreifen können, während Writes exklusiven Zugriff benötigen.
Dieses Modell scheint auf den ersten Blick optimal, denn beim Lesen gibt es keine Konflikte, und die Leselast sollte linear mit der Anzahl der Reader skalieren. In der Praxis sieht es aber anders aus. Konkret verursacht das Verwalten der Anzahl der aktiven Reader häufige Mutationen der Lock-State-Variablen, wodurch Cachelines ständig zwischen den CPU-Kernen hin- und hergeschoben werden müssen, ein Phänomen, das als Cacheline Pingpong bezeichnet wird. Wenn beispielsweise mehrere Kerne gleichzeitig ihre Readerzahl erhöhen oder verringern wollen, lösen die Cache-Coherency-Protokolle im Prozessor eine teure Invalidierung der Cachelines aus. Das führt zu erheblichen Performance-Einbußen, vor allem bei einer großen Anzahl paralleler Threads.
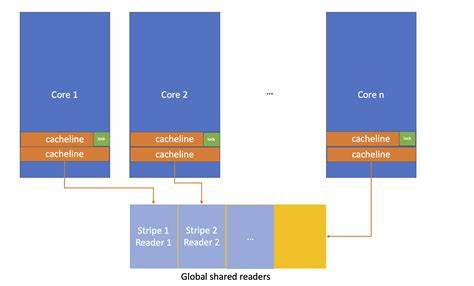
Als Resultat kann sich die Leistung sogar verschlechtern oder nur marginal verbessern, wenn mehr parallele Leser hinzukommen. Ein prominentes Beispiel, das diesen Engpass adressiert, ist das folly::SharedMutex aus der C++ Bibliothek folly von Facebook. Die Entwickler haben dort ein System entwickelt, das die aktiven Reader im globalen statischen Speicher in Form eines Arrays von sogenannten „Slots“ ablegt. Dabei wird das Shared Storage so gestreift, dass jeder Slot genau eine Cacheline umfasst. Diese clevere Aufteilung sorgt dafür, dass jeder Thread nur seine eigene Cacheline aktualisiert und so die Cache-Invalidate-Operationen bei anderen Kernen minimiert werden.
Zusätzlich wird jedem Kern eine feste Route zu einem Slot zugewiesen, um Suchaufwand zu reduzieren. Ein weiterer wichtiger Aspekt ist, dass die Adresse des Mutex in jedem Slot gespeichert wird, was die Lokalisierung von relevanten Daten beschleunigt. Durch diese Mechanik bleibt der eigentliche Lock-Zustand unverändert, wenn ein Reader hinzukommt – die Mutation erfolgt nur im Slot des entsprechenden Readers. Auf diese Weise wird das traditionellen Cacheline-Pingpong-Effekt entgegengewirkt und die Leseskalierung verbessert sich deutlich. Allerdings hat diese Technik auch ihre Nachteile.
Da alle Reader-Slots in einem gemeinsamen statischen Speicherbereich liegen, kann eine Operation im Schreibmodus dazu führen, dass die gesamte Reader-Blockierung betroffen ist. Das heißt, wenn ein Schreiber auf die Sperre zugreift, kann es trotz Nicht-Konkurrenz von Lesern anderer Mutex-Objekte durch Cacheline-Invalidierungen zu Performance-Verlusten kommen. Nichtsdestotrotz ist das Transaktionsmodell von folly::SharedMutex besonders dann effektiv, wenn viele gleichzeitige Leser auf denselben Lock zugreifen und tatsächlich Contention herrscht. In Szenarien mit nur gelegentlichen parallelen Lesezugriffen arbeitet ein simpler Spinlock oft besser. Deshalb besitzt folly::SharedMutex eine dynamische Eigenschaft: Bei fehlenden parallelen Lesern verwendet es eine inline Read-Write Lock Implementation, bei der die Readerzahl inline im Lock-State gezählt wird.
So wird der Overhead minimiert und die Leistung in unterschiedlichen Nutzungsszenarien optimiert. Eine weitere Herausforderung in der Implementierung von skalierbaren Read-Write Locks ist das Blockieren und Warten von Threads. Systemaufrufe wie FUTEX_WAIT sind teuer und sollten nur als letztes Mittel eingesetzt werden. folly::SharedMutex kombiniert eine mehrstufige Strategie: zunächst wird eine aktive Wartephase mit Pause-Instruction durchgeführt, die vor allem CPU-Reihenfolgeprobleme reduziert. Schlägt diese aus, folgt ein yield an den Scheduler, um anderen Threads Ausführungszeit zu geben.
Erst wenn auch das keinen Erfolg bringt, erfolgt der teure Schlaf über FUTEX_WAIT. Diese abgestufte Herangehensweise maxmiert die Effizienz und minimiert den System-Overhead. Das Lockschema selbst beruht auf einem einzigen 32-Bit atomaren Futex-Wert, der den Zustand des Locks kodiert und eine Reihe von Sonderbits für Statusinformationen enthält. Beim Erwerb eines Locks im Schreibmodus blockiert die Implementierung gegebenenfalls alle Reader, auch die sogenannten deferred readers, also die Leser, die ihren Zugriff in den globalen Slot ausgelagert haben. Bei Freigabe des Locks entscheidet folly::SharedMutex intelligent, welche wartenden Threads geweckt werden: Wenn Writer warten, wird nur einer aufgeweckt – um Kollisionen zu vermeiden.
Wenn Leser warten, werden alle gleichzeitig geweckt, um parallelen Zugriff zu ermöglichen. Sollte der globale statische Speicherbereich einmal erschöpft sein, so wird automatisch auf die klassische Inline-Zählung von Lesern zurückgegriffen. Trotz der Komplexität dieses Systems zeigt sich in Benchmarks, dass folly::SharedMutex auf modernen Systemen mit vielen Kernen und Hyperthreading eine deutlich bessere Skalierbarkeit und oft auch höhere absolute Leistung erreicht als herkömmliche Lösungen. Gerade bei realistischen Szenarien mit häufigem parallelem Zugriff erzielt es teilweise signifikante Geschwindigkeitsvorteile. Insgesamt verdeutlicht die Entwicklung linear skalierbarer Read-Write Locks, wie tiefgehendes Verständnis von Hardware-Architektur, Cache-Coherency-Protokollen und Synchronisationsmechanismen notwendig ist, um echte Performance-Verbesserungen bei parallelem Programmieren zu erreichen.
Der Weg vom einfachen Zähler im Lock-State hin zu ausgefeilten globalen Strukturen und hybriden Dynamiken macht deutlich, dass Synchronisation weit mehr als nur der Schutz vor Datenrennen ist. Es ist ein komplexes Zusammenspiel zwischen Hardware, Betriebssystem und Anwendungslogik, das bei richtiger Umsetzung non-lineare Skalierung realisieren kann. Wer in der Softwareentwicklung für Mehrkernsysteme maximale Performance in gleichzeitigen Zugriffs-Szenarien benötigt, darf das Potenzial linear skalierbarer Read-Write Locks nicht unterschätzen. Sie sind ein zentrales Werkzeug, um die Nutzererfahrung in hochparallelen Anwendungen auf ein neues Level zu heben.