Datenbanken sind das Herzstück moderner Anwendungen und Systeme. Sie ermöglichen es, große Datenmengen strukturiert zu speichern, abzufragen und zu manipulieren. Doch wie genau funktioniert eine Datenbank im Inneren? Welche Mechanismen bestimmen den Speicherort der Daten und die Effizienz bei deren Abfrage? Um diese Fragen zu beantworten und ein tieferes Verständnis für Datenbanksysteme zu erlangen, ist es hilfreich, eine einfache Datenbank von Grund auf selbst zu programmieren. In diesem Zusammenhang spielt die Arbeit an einem SQLite-Klon in C eine besondere Rolle, da SQLite eine der am weitesten verbreiteten, serverlosen Datenbank-Engines ist. Dieses Projekt geht über die reine Nutzung von SQLite hinaus und bietet Einblicke in die Architektur und Funktionsweise von Datenbanken im Allgemeinen.
Die Entwicklung eines solchen Klons ermöglicht nicht nur ein vertieftes technisches Verständnis, sondern fördert auch Programmierfähigkeiten und das Wissen über Datenstrukturen und Speicherverwaltung. Eine der grundlegendsten Fragen beim Aufbau einer Datenbank ist, wie Daten im Speicher und auf der Festplatte abgelegt werden. Dabei muss entschieden werden, in welchem Format die Daten intern gespeichert werden. Im Arbeitsspeicher ist es üblich, Daten strukturiert und oft als Rohbytes oder in speziellen Datenstrukturen abzulegen, die schnelle Lese- und Schreibzugriffe erlauben. Auf der Festplatte hingegen erfolgt die Speicherung in Dateien, die organisiert sind, um schnelle Zugriffe zu unterstützen und die Integrität der Daten sicherzustellen, selbst nach Systemabstürzen oder Stromausfällen.
Der Übergang vom Arbeitsspeicher zum dauerhaften Speicher erfolgt meist in Form von sogenannten Transaktionen oder Commit-Operationen, die sicherstellen, dass nur konsistente Daten geschrieben werden. Die Entscheidung, warum eine Tabelle nur einen einzigen Primärschlüssel haben darf, ist wesentlich für die Struktur und Leistungsfähigkeit einer Datenbank. Ein Primärschlüssel dient zur eindeutigen Identifikation jeder Zeile einer Tabelle und ermöglicht dadurch schnelle Lookup-Operationen. Würden mehrere Primärschlüssel erlaubt sein, wäre die Eindeutigkeit nicht mehr garantiert, was Datenkonsistenz und Suchoperationen erheblich erschweren würde. Das Design der Datenbank zielt daher darauf ab, mit möglichst wenig redundanten Daten zu arbeiten und eine klare Identifizierung jeder gespeicherten Einheit zu gewährleisten.
Transaktionen sind ein zentrales Konzept für die Konsistenz einer Datenbank. Sie ermöglichen es, eine Reihe von Operationen als untrennbare Einheit auszuführen. Sollte beispielsweise während einer Transaktion ein Fehler auftreten, so sorgt das Datenbanksystem dafür, dass alle Veränderungen rückgängig gemacht werden und der ursprüngliche Zustand wiederhergestellt wird. Dieses Vorgehen wird als Rollback bezeichnet und stellt sicher, dass die Datenbank zu keiner Zeit inkonsistente oder halb fertige Zustände annimmt, selbst bei unerwarteten Problemen. Indizes sind essenziell, um schnelle Suchvorgänge in großen Datenmengen zu gewährleisten.
Wie diese Indizes formatiert und implementiert sind, bestimmt maßgeblich die Performance der Datenbank bei Abfragen mit Bedingungen. Üblicherweise werden B-Bäume verwendet, um Indizes anzulegen, da sie eine balancierte Struktur bieten, die sowohl schnelle Suchoperationen als auch effizientes Einfügen und Löschen von Einträgen ermöglicht. Gelegentlich ist es dennoch notwendig, einen vollständigen Tabellenscan durchzuführen. Dies geschieht, wenn keine passenden Indizes vorhanden sind oder komplexe Abfragen stattfinden, bei denen mehrere Felder und Bedingungen miteinander kombiniert werden. In solchen Fällen liest die Datenbank jede einzelne Zeile aus, um die gewünschten Daten zu finden.
Obwohl ein vollständiger Scan in der Regel langsamer ist, gehört er zu den unvermeidbaren Operationen, die eine Datenbank leisten muss. Vorbereitete Anweisungen, auch Prepared Statements genannt, stellen eine Technik dar, bei der SQL-Befehle vor der Ausführung analysiert und in einer standardisierten internen Darstellung gespeichert werden. Dies erhöht die Sicherheit und Effizienz, da die Befehle nicht bei jeder Ausführung erneut geparst werden müssen und Parameter separat übergeben werden können. Die korrekte Speicherung und Verwaltung solcher Anweisungen sind daher ebenfalls Teil einer robusten Datenbankimplementierung. Die Entwicklung eines SQLite-Klons beginnt idealerweise mit einer einfachen Kommandozeilenanwendung, die Benutzereingaben entgegennimmt und verarbeitet.
Die Implementierung eines sogenannten REPL (Read-Eval-Print Loop) erleichtert das Testen und Experimentieren mit SQL-ähnlichen Befehlen. Im Rahmen eines solchen Projekts wird zunächst die grundlegendste Version einer Datenbank entwickelt, die nur eine Tabelle unterstützt und alle Operationen im Speicher durchführt. Diese Herangehensweise erlaubt iterative Verbesserungen und vereinfacht Fehlersuche und Testverfahren. Im Verlauf des Projekts folgt die Implementierung von Persistenzmechanismen, um die Daten nicht nur im flüchtigen Speicher, sondern dauerhaft auf der Festplatte ablegen zu können. Dies stellt höhere Anforderungen an die Konsistenz und die Fehlerresistenz des Systems.
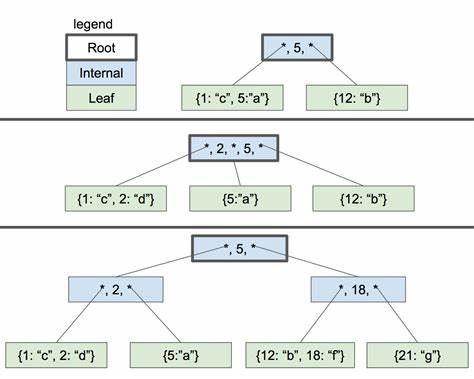
Zudem müssen Datenstrukturen wie Cursorn entwickelt werden, die das Navigieren durch Datensätze unterstützen und z.B. Aufsuchen, Lesen und Modifizieren von Tableinträgen ermöglichen. Ein zentrales Datenstrukturkonzept, das im Kern von SQLite und vielen anderen Datenbanken steht, ist der B-Baum. Diese selbstbalancierende Baumstruktur ermöglicht das effiziente Speichern und Suchen von Schlüssel-Wert-Paaren und reduziert die durchschnittliche Anzahl der benötigten Leseoperationen auf Platten erheblich.
Im Konstrukt eines SQLite-Klons gilt es zunächst, die Grundlagen eines B-Baums zu verstehen, wie Blatt- und interne Knoten aufgebaut sind und wie Suchoperationen und Einfügungen in diesen Bäumen durchgeführt werden. Eine besonders anspruchsvolle Aufgabe ist das Aufteilen von Knoten, wenn sie zu voll werden. Dieses sogenannte Splitting ist notwendig, um die Balance des Baumes zu erhalten und eine effiziente Datenverteilung zu gewährleisten. Zudem müssen dabei übergeordnete Knoten aktualisiert und gegebenenfalls ebenfalls aufgeteilt werden. Nur so bleiben Suchzeiten konstant niedrig, auch wenn die Datenbank wächst.
Ein wichtiger Aspekt ist auch, wie heutzutage moderne Datenbanken mit der vorgängigen Analyse von SQL-Anfragen umgehen. Die Erstellung eines einfachen SQL-Kompressors und virtuellen Maschinen als Teil des Projekts verdeutlicht, wie komplex die Verarbeitung von SQL-Befehlen sein kann, und wie sie in Maschinenbefehle übersetzt wird, die dann auf den konkreten Daten operieren. Dieses Zwischenschicht-Verfahren ermöglicht eine flexible Abstraktion und kann zur Optimierung der Ausführung genutzt werden. Die Entwicklung einer eigenen SQLite-Klon-Datenbank ist eine anspruchsvolle, aber auch enorm lehrreiche Aufgabe. Sie hilft, tiefergehende Kenntnisse über Datenstrukturierung, Speicherverwaltung und Datenbankarchitektur zu erlangen.
Dabei lernt man nicht nur theoretische Konzepte, sondern wendet praktische Programmiertechniken an, die auch in der professionellen Softwareentwicklung von großer Bedeutung sind. Für alle, die sich intensiver mit diesem Thema beschäftigen möchten, bietet sich eine Vielzahl von Ressourcen an. Neben dem Studium der SQLite-Architektur können weiterführende Projekte wie das Programmieren von Docker, Redis oder Git zur Vertiefung dienen. Einige Entwicklerplattformen bieten praktische Tutorials und Codelabs, die schrittweise beim Erstellen solcher Systeme unterstützen und dies teilweise mit modernen, interaktiven Lernumgebungen kombinieren. Die Investition in das Verstehen und selbständige Erstellen von Datenbanktechnologien wird langfristig belohnt.
Kein Werkzeug ist so zentral in der IT wie die Datenbank, und ein fundiertes Verständnis ihrer Funktionsweise ermöglicht das Entwickeln leistungsfähiger, effizienter und zuverlässiger Anwendungen – ob im Web-, Mobil- oder Enterprise-Bereich. Abschließend lässt sich sagen, dass der Bau einer einfachen Datenbank zwar eine komplexe Herausforderung darstellt, jedoch mit methodischem Vorgehen und dem richtigen Verständnis machbar ist. Die transparente Dokumentation des Entwicklungsprozesses unterstützt alle, die selbst in das Thema einsteigen wollen. Mit Geduld und Neugier wird die Welt der Datenbanken verständlich und lebendig – ein unverzichtbares Wissen für jeden Softwareentwickler und IT-Enthusiasten.