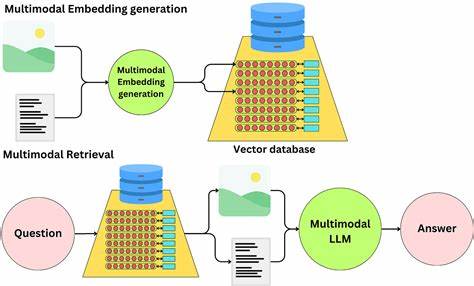
In der heutigen datengetriebenen Welt gewinnen multimodale Systeme immer mehr an Bedeutung, insbesondere wenn es darum geht, Informationen aus unterschiedlichen Quellen effizient zu verarbeiten und bereitzustellen. Retrieval-Augmented-Generation-Systeme, kurz RAG, stellen dabei eine innovative Kombination aus Information Retrieval und Textgenerierung dar. Sie ermöglichen das gezielte Abrufen relevanter Dokumentausschnitte, die als Grundlage für vom Modell generierte Antworten dienen. Besonders spannend ist die multimodale Erweiterung dieser Systeme, welche neben Text auch andere Dateiformate wie PDFs und Excel-Tabellen integriert. Wer sich mit diesem Thema auseinandersetzt, steht vor der Herausforderung, leistungsfähige, flexible und zugleich genau arbeitende Systeme zu implementieren, die neben präzisen Quellenangaben auch grafische Hervorhebungen oder Bounding-Box-Visualisierungen unterstützen.
Die Bedeutung einer solchen Funktionalität lässt sich kaum überschätzen, da gerade in professionellen Anwendungen die Nachvollziehbarkeit der Information eng mit der Vertrauenswürdigkeit des Outputs verknüpft ist. Doch während einzelne Frameworks heute zwar viele Möglichkeiten bieten, sind sie häufig durch proprietäre Designs oder eingeschränkte Modularität geprägt. Damit stellt sich die Frage, wie sich ein zeitgemäßer, unabhängiger und praktischer Multimodal-RAG-„Cookbook“ gestalten lässt, der nicht nur technische Anforderungen erfüllt, sondern auch Einsteigern den Zugang erleichtert. Zunächst ist zu klären, was genau unter multimodalem RAG zu verstehen ist. Klassische RAG-Modelle arbeiten meistens mit rein textbasierten Datenbanken oder Knowledge Bases.
Ein multimodales System hingegen verarbeitet unterschiedliche Datentypen gleichrangig, um eine breitere und realistischere Abdeckung von Anwendungsfällen zu ermöglichen. Das umfasst beispielsweise die Kombination von PDF-Dokumenten, die häufig als fixierte Informationsquellen in Firmen vorliegen, mit Daten aus Excel-Tabellen, die strukturierte Zahlenwerte enthalten. Um diese unterschiedlichen Formate in einem RAG-Kontext zu nutzen, müssen zunächst geeignete Methoden zur Datenextraktion gewählt werden. Bei PDFs geht es primär darum, Textinhalte zuverlässig zu erfassen – was keine triviale Angelegenheit ist, da PDF-Strukturen sehr heterogen sein können und oft neben Text auch Grafiken, Tabellen und Metadaten enthalten. Für eine genaue Zitatfunktion ist es entscheidend, nicht nur Absätze oder Seitenzahlen zu extrahieren, sondern den Ursprungspunkt im Dokument genau zu lokalisieren.
Bei Excel-Dateien ist das Einlesen von Zellinhalten und deren Struktur ähnlich relevant, daneben müssen aber auch Zeilen- und Spaltenhierarchien beachtet werden. Der Umgang mit sogenannten „Multi-Sheets“ stellt eine weitere Herausforderung dar, denn Informationen können sich über mehrere Blätter verteilen. Das Ziel ist, beide Datenquellen in einem gemeinsamen semantischen Raum zu repräsentieren. Dies erfordert geeignete Embedding-Modelle, die nicht nur den reinen Text, sondern auch tabellarische Strukturen und zusätzliche Kontextinformationen abbilden. Open-Source-Bibliotheken wie LangChain oder Haystack bieten erste Ansätze für solche multimodalen Pipelines, wobei der Nutzer dieses Ökosystem oft an spezifische Technologien gebunden ist.
Die Notwendigkeit, Framework-Unabhängigkeit zu bewahren, stellt somit eine zentrale Anforderung bei der Auswahl der Tools und beim Design des Systems dar. Hinsichtlich der Zitierfunktion sind im Idealfall nicht nur die verwendeten Dokumentquellen eindeutig erkennbar, sondern ebenso die genaue Position im Originaltext oder in der Tabelle. Dies erlaubt eine transparente Rückverfolgbarkeit und verhindert potenzielle Fake-Informationen, die bei generativen Modellen auftreten können. Moderne Ansätze gehen darüber hinaus und nutzen visuelle Hervorhebungen, beispielsweise durch farbige Markierungen oder Bounding-Boxen, die den Nutzer intuitiv an die exakte Quelle im Dokument verweisen. Dies erhöht die Benutzerfreundlichkeit und erleichtert die Validierung der gelieferten Auskünfte signifikant.
Bei der Implementierung ist es empfehlenswert, eine modulare Architektur zu wählen, bei der die Komponenten zur Datenextraktion, Embedding-Erstellung, Suche und Generierung klar getrennt sind. Dies ermöglicht nicht nur das einfache Austauschen von einzelnen Bausteinen, sondern auch die flexible Erweiterung um neue Dateiformate oder KI-Modelle. Ein sinnvolles Vorgehen besteht darin, Workflow-Schritte in unabhängig ausführbare Module zu unterteilen, die über standardisierte Schnittstellen kommunizieren. Darüber hinaus spielt auch die Speicherung der Indizes eine Schlüsselrolle. Vektorbasierte Datenbanken wie Pinecone, Weaviate oder FAISS bieten robuste Möglichkeiten das semantische Embedding effektiv zu speichern und performant abzufragen, wobei auch hier auf Interoperabilität und Offenheit geachtet werden sollte.
Auf dem Gebiet der visuellen Hervorhebung profitieren Entwickler von Rendering-Bibliotheken, die PDF- und Tabelleninhalte auf der Oberfläche in Echtzeit markieren können. Technologien aus dem Web-Bereich wie PDF.js oder Tabulator.js können hierfür dienen, vorausgesetzt, die Datenübergabe ist sauber implementiert. Alternativ existieren dedizierte Softwarepakete, die automatische Bounding-Box-Berechnungen ermöglichen und Schnittstellen für die Integration in eigenständige Anwendungen bieten.
Ein wichtiger Aspekt bei einem solchen RAG-Cookbook ist die ausführliche Dokumentation und Schritt-für-Schritt-Anleitung, idealerweise inklusive Beispielcode und Erklärungen, wie Zitate genau an den Output gekoppelt werden. Quellen sollten dabei nicht als reine URLs oder Dateinamen erscheinen, sondern mit kontextbezogenen Verweisen, etwa „Seite X, Absatz Y“ oder „Tabelle 2, Zelle D5“. So wird Transparenz und Glaubwürdigkeit gewährleistet. Die Herausforderung, die meisten Frameworks wie die von Google oder OpenAI derzeit haben, liegt darin, dass umfassende multimodale Demonstrationen mit Zitat- und Highlight-Funktion noch in der Entwicklung oder gar nur angefragt, aber noch nicht veröffentlicht sind. Häufig sind bestehende Ressourcen fragmentiert oder zeigen entweder nur Parts des Workflows ohne ganzheitlichen Ansatz.
Das Resultat ist, dass Anwender heute häufig auf eine Kombination aus Open-Source-Lösungen und selbst entwickelten Modulen setzen müssen. Für Anfänger kann dies zu einer steilen Lernkurve führen, weshalb ein gut strukturiertes, betreutes Cookbook mit klar definierten Schritten immens hilfreich wäre. Neben technischen Videos oder Tutorials lohnen sich Repositories auf Plattformen wie GitHub, die aktiv gepflegt werden und kommentierten Code bieten, der flexibel an verschiedene Projekte angepasst werden kann. Daneben existieren wissenschaftliche Veröffentlichungen, die theoretische Grundlagen legen, aber oft wenig praxisnahe Umsetzungsdetails transportieren. Für den deutschen Raum sind zudem Community-Foren und Meetups wertvolle Anlaufstellen, da hier Austausch und gegenseitige Hilfestellung möglich sind.
Zusammenfassend lässt sich sagen, dass ein zeitgemäßer Multimodal-RAG-Ansatz, der PDFs und Excel-Dateien verarbeitet, präzise Zitate liefert und visuelle Hervorhebungen integriert, eine Kombination aus passenden Extraktionsverfahren, modernen Embedding-Technologien, einem flexiblen Framework und benutzerfreundlichen Visualisierungskomponenten benötigt. Die Suche nach einem kompletten und unabhängigen Cookbook zeigt, dass es aktuell noch ein Desiderat in der Entwicklerlandschaft gibt. Dennoch existieren Bausteine und Best Practices, die dabei helfen, ein solches System schrittweise aufzubauen. Wer auf die Modularität achtet und Plattformoffenheit priorisiert, kann Tools und Frameworks kombinieren, um so eine individualisierte Lösung zu realisieren. In Zukunft kann man davon ausgehen, dass mit dem weiteren Fortschritt von KI und Open Source noch umfangreichere und benutzerfreundlichere Ressourcen entstehen werden, die den Einstieg in multimodale RAG-Systeme deutlich erleichtern.
Bis dahin ist die Kombination aus detaillierter Dokumentation, aktiver Community-Nutzung und experimentellem Selbstlernen die beste Strategie für Entwickler, die multimodale Dokumentenverarbeitung mit zuverlässiger Zitier- und Highlightfunktion umsetzen möchten.