In der Welt der Programmierung und Softwareentwicklung sind Kenntnisse über Latenzzeiten essenziell, um effiziente und leistungsstarke Anwendungen zu erstellen. Latenz bezeichnet die Verzögerung, die zwischen einer Aktion und der Reaktion darauf auftritt – sei es beim Zugriff auf den Speicher, das Senden von Daten über ein Netzwerk oder das Lesen von Daten von einem Laufwerk. Das Verständnis dieser Latenzzeiten ist für Entwickler unerlässlich, da es ihnen erlaubt, Engpässe zu erkennen, Ressourcen optimal zu nutzen und die Performance von Programmen signifikant zu verbessern. Zu Beginn ist es wichtig, die unterschiedlichen Ebenen zu verstehen, auf denen Latenz auftaucht. Von der schnellsten Komponente eines Computersystems, dem Prozessor, bis hin zu externen Datenspeichern oder Netzwerkverbindungen variieren die Latenzzeiten erheblich.
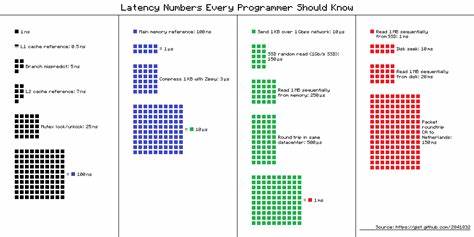
Dabei bewegt sich die Skalierung dieser Verzögerungen von Nanosekunden bis zu Millisekunden, sogar bis zu Sekunden oder Minuten, wenn man komplexe Systeme und externe Kommunikation berücksichtigt. Die schnellste und unmittelbarste Art der Datenzugriffe finden im Cache des Prozessors statt. Dort gibt es unterschiedliche Ebenen wie den L1- und L2-Cache, die den Prozessor mit blitzschnellen Daten versorgen. Die reine Zeit für einen Zugriff auf den L1-Cache liegt bei etwa 0,5 Nanosekunden. Diese Geschwindigkeit beruht auf der Nähe zum Prozessorkern und der begrenzten Datenmenge, die hier gespeichert wird.
Ein Zugriff auf den L2-Cache ist aufgrund der größeren Größe und etwas größeren Entfernung zum Kern mit ungefähr 7 Nanosekunden etwas langsamer, jedoch immer noch sehr schnell. Die Bedeutung dieser Cache-Latenzen liegt in der Tatsache, dass sie einen direkten Einfluss auf die Effizienz von Algorithmen und Datenverarbeitung haben. Optimierungen, die darauf abzielen, häufig benötigte Daten möglichst im Cache zu halten, können einen entscheidenden Performance-Vorteil bringen. Beim Überschreiten des Cache-Speichers wird der Zugriff auf den Hauptspeicher (RAM) notwendig, was mit einer spürbaren Verzögerung von ungefähr 100 Nanosekunden verbunden ist. Obwohl 100 Nanosekunden immer noch unvorstellbar kurz erscheinen mögen, ist diese Verzögerung im Vergleich zu Cache-Zugriffen erheblich und kann bei datenintensiven Anwendungen schnell zum Engpass werden.
Hier wird deutlich, wie wichtig es ist, den Speicherzugriff effizient zu gestalten und unnötige RAM-Zugriffe zu vermeiden, etwa durch Caching-Strategien oder speicherfreundliche Algorithmendesigns. Ein weiteres wichtiges Konzept in der Prozessorwelt ist die Verzweigungsvorhersage (Branch Prediction). Moderne CPUs versuchen, die logischen Pfade eines Programms vorauszuberechnen, um reibungslos und schnell zu arbeiten. Bei Fehleinschätzungen kommt es jedoch zu einer Strafverzögerung von etwa 5 Nanosekunden. Auch wenn dies auf den ersten Blick nur gering erscheint, summieren sich solche Fehlvorhersagen bei komplexen Berechnungen und können die Gesamtperformance deutlich beeinträchtigen.
Weitaus signifikante Verzögerungen treten beim Betriebssystem und der Thread-Synchronisation auf. Ein typisches Beispiel ist das Sperren und Aufheben von Mutexen, wofür ungefähr 25 Nanosekunden benötigt werden. Hierbei handelt es sich um Mechanismen zur Verhinderung von gleichzeitigen Datenzugriffen, die in mehrthreadigen Programmen essenziell sind. Das Verständnis dieser Latenz hilft Programmierern, kritische Sektionen so kurz und effizient wie möglich zu halten, um die Wartezeiten und Blockierungen zu minimieren. Wenn es um das Lesen und Schreiben von Daten außerhalb des Arbeitsspeichers geht, wird die Latenz spürbar höher.
Der Zugriff auf eine SSD weist durchschnittlich eine Latenz von 150 Mikroseunden auf, was im Gegensatz zum Hauptspeicher eine deutliche Verzögerung darstellt. Lese- und Schreibzugriffe auf mechanische Festplatten sind im Vergleich dazu mit einer Latenz von 10 Millisekunden bis 20 Millisekunden noch viel langsamer. Diese Werte sind maßgeblich, um zu verstehen, warum Speichertechnologien wie SSDs die Performance von Anwendungen in vielen Fällen drastisch verbessern können. Auch die Netzwerk-Latenzen spielen eine zentrale Rolle in verteilten Systemen und Cloud-Anwendungen. Beim Versenden von kleinen Datenpaketen über eine Gigabit-Verbindung liegt die Latenz in der Größenordnung von 20 Mikrosekunden.
Allerdings steigt diese Verzögerung je nach Entfernung und Anzahl der Knotenpunkte signifikant an. Eine Netzwerkrundreise innerhalb eines Rechenzentrums verlangt etwa 0,5 Millisekunden, während ein Paket von Kalifornien nach Europa und zurück durchaus 150 Millisekunden benötigen kann. Das Bewusstsein über diese Latenzzeiten ist für Entwickler von verteilten Systemen, Online-Spielen und Echtzeitanwendungen von kritischer Bedeutung, da sie direkte Auswirkungen auf die Benutzererfahrung und die Systemstabilität haben. Ein besonders anschauliches Beispiel für die Bedeutung von Latenz ist das menschliche Zeitempfinden, das im Gegensatz zu maschineninternen Operationen erheblich länger ist. Um sich die Dimensionen dieser Verzögerungen besser vorstellen zu können, kann man die einzelnen Latenzzeiten mit alltäglichen Lebensereignissen vergleichen.
So entspricht ein L1-Cache-Zugriff etwa der Dauer eines Herzschlags und das Warten auf eine Speicheroperation im RAM ist vergleichbar mit dem Zähneputzen. Das Warten auf eine SSD-Leseoperation von einem Megabyte entspricht in diesem Modell beinahe der Dauer eines Kurzurlaubs. Solche Analogien tragen dazu bei, ein besseres Gefühl für die Auswirkungen von Latenz zu bekommen und gezielt Performance-Optimierungen vorzunehmen. Programmierer sollten diese Latenzwerte nicht nur theoretisch kennen, sondern auch ihre Bedeutung im Alltagsgeschäft verinnerlichen. Wenn beispielsweise eine Anwendung hauptsächlich von langsamen Festplattenzugriffen gebremst wird, bringt es oft mehr, das I/O-Verhalten zu optimieren oder auf schnellere Speichertechnologien umzusteigen, als nur den Algorithmus zu verbessern.
Ebenso hilft das Verständnis von Cache-Latenzen bei der Entwicklung performanter Software, die Daten effizient und möglichst lokal verarbeitet. Darüber hinaus sind Latenzen ein entscheidender Faktor bei der Architektur von verteilten Systemen, wo es gilt, Latenzquellen durch geeignete Techniken wie Caching, Replikation oder parallele Verarbeitung zu minimieren. Auch in der Parallelprogrammierung spielen Latenzzeiten bei Synchronisationsmechanismen eine große Rolle: Je kürzer kritische Abschnitte gehalten werden, desto geringer ist die Verzögerung im Gesamtprozess. Moderne Prozessoren und Systeme werden stetig schneller, aber die Grundprinzipien und relativen Größenordnungen der Latenzzeiten bleiben nach wie vor gültig. Für Entwickler im Jahr 2024 gilt es daher umso mehr, mit einem tiefen Verständnis der Latenzen zu arbeiten und diese für eine optimale Software-Performance einzusetzen.








