In der heutigen Datenlandschaft zeichnet sich eine fundamentale Veränderung ab, die das Zusammenspiel von Speicher, Datenformate und Rechenleistung neu definiert. Open Table Formate wie Apache Iceberg haben sich als zentrale Technologie herauskristallisiert, die es ermöglicht, strukturierte Daten in verteilter Form kostengünstig und gleichzeitig datenbankähnlich zu speichern und zu verwalten. Große Cloudanbieter, sogenannte Hyperscaler, investieren massiv in Managed Iceberg-Lösungen, um Unternehmen eine skalierbare, flexible und dennoch standardisierte Datenplattform bereitzustellen. Doch warum gewinnt gerade Managed Iceberg so stark an Bedeutung? Und was bedeutet das für die Zukunft der Datenarchitektur? Die Antworten liegen in der Kombination aus Offenheit, Performance und Kostenoptimierung, die Managed Iceberg nachhaltig ermöglicht. Traditionell wurden Daten entweder in teuren Data Warehouses oder kostengünstig aber unstrukturiert in Object Storage-Systemen abgelegt.
Die Herausforderung lag darin, die Vorteile beider Welten zu vereinen: die Skalierbarkeit und Kosteneffizienz von Object Stores wie Amazon S3 oder Cloudflare R2 mit den mächtigen Query-Fähigkeiten und Transaktionssicherheit von Datenbanken. Open Table Formate stellen genau diese Verbindung her, indem sie einen strukturierten, transaktionsfähigen Layer auf verteilten Dateien etablieren. Dabei sind sie nicht an proprietäre Systeme gebunden, sondern nutzen offene Standards und ermöglichen eine Interoperabilität zwischen unterschiedlichen Analyse- und Verarbeitungstools. Apache Iceberg ist dabei eine der führenden Technologien im Bereich der Open Table Formate. Mit seiner Fähigkeit, große Datenmengen in Parquet- oder Avro-Dateien organisiert und durch ein ausgefeiltes Metadaten-Management effizient abzufragen, hat sich Iceberg als Quasi-Standard etabliert.
Im Gegensatz zu alternativen Formaten wie Delta Lake oder Apache Hudi zeichnet sich Iceberg durch hohe Flexibilität aus und wird zunehmend in Managed-Services angeboten, was den Einstieg und Betrieb für Unternehmen stark vereinfacht. Besonders spannend ist hierbei die Entwicklung des sogenannten ICE Stacks, eines Architekturkonzepts, das Interoperabilität, Komposabilität und Effizienz miteinander vereint. Der ICE Stack steht für Interoperable, Composable und Efficient und beschreibt eine modulare Datenarchitektur, in der Speicher, Rechenleistung, Table-Format sowie das Katalogmanagement voneinander entkoppelt sind und flexibel kombiniert werden können. Dies bedeutet konkret, dass Unternehmen Daten in einem offenen Format auf günstigen Object Storage-Systemen speichern, dabei aber jederzeit verschiedene Query Engines wie Spark, DuckDB, Athena oder Snowflake nutzen können. Die Daten selbst bleiben unverändert und austauschbar, wodurch Vendor Lock-In-Probleme der Vergangenheit angehören.
Diese Offenheit ist einer der Hauptgründe, warum Hyperscaler massiv in Managed Iceberg investieren – sie wollen ihren Kunden maximale Freiheit und Wahlmöglichkeiten bieten, ohne die Komplexität aus den Augen zu verlieren. Ein weiterer bedeutender Vorteil des ICE Stacks ist die Komposabilität. Kunden können die besten Komponenten unterschiedlicher Anbieter kombinieren und so ihre Datenplattform individuell an ihre Bedürfnisse anpassen. Beispielsweise lässt sich Cloudflare R2 als kostengünstiger Object Storage mit einem Iceberg-Katalog integrieren, während die eigentlichen Abfragen über eine spezialisierte Rechenengine wie Snowflake oder Databricks ausgeführt werden. Gleichzeitig sorgt die hohe Effizienz der Architektur dafür, dass Kosten durch intelligente Komprimierung, automatisierte Datei-Compaction sowie optimiertes Snapshot-Management gering gehalten und Performance-Engpässe minimiert werden.
Hyperscaler wie Amazon AWS haben mit ihrem jüngsten Angebot von S3 Tables einen großen Schritt in Richtung vollwertiger Managed Iceberg-Lösungen gemacht. AWS S3 Tables kombinieren Object Storage direkt mit Iceberg-Table-Formaten und einem integrierten Katalogservice. Das Besondere dabei ist, dass sie nicht nur die Daten speichern, sondern auch automatisch Abfrageoptimierungen, Datei-Compaction und Snapshot-Management übernehmen. Dadurch werden nicht nur Geschwindigkeit und Skalierbarkeit erheblich verbessert, sondern auch die Verwaltung stark vereinfacht. Darüber hinaus führt AWS eigene APIs ein, die den Zugang zu den Tabellen steuern und eine sichere Mehrbenutzerumgebung unterstützen.
Trotz dieser Vorteile bestehen Bedenken seitens der Community. Kritiker weisen darauf hin, dass AWS bei seinen S3 Tables eine proprietäre API implementiert, was die Offenheit des Systems einschränkt und potenziell den Wechsel zu anderen Systemen erschwert. Die Implementierung einer proprietären Schnittstelle steht im Widerspruch zum Open-Source-Gedanken von Apache Iceberg und könnte langfristig zu Fragmentierungen führen. Hier zeigen sich die Herausforderungen der Balance zwischen Managed Services und echter Offenheit sehr deutlich. Parallel dazu bringt Cloudflare mit seinem R2 Data Catalog eine weitere Alternative ins Spiel, die stark auf Offenheit und Kostenoptimierung setzt.
Der R2 Data Catalog unterstützt Apache Iceberg vollständig in einem offenen Managed-Katalog, der die Nebenkosten wie Ausgabekosten bei Datentransfers eliminiert. Die Nutzung einer offenen REST-Schnittstelle ermöglicht eine einfache Integration mit verschiedenen Analyse- und Abfragewerkzeugen ohne Vendor Lock-In. Allerdings liefert Cloudflare nur den Katalog und den Speicher, die Rechenleistung muss separat bereitgestellt werden. Für viele Unternehmen stellt das dennoch eine attraktive Option dar, um kostengünstig eine offene und skalierbare Lakehouse-Architektur zu realisieren. Der Trend deutet klar auf eine Konsolidierung der Open Table Formate um Apache Iceberg hin.
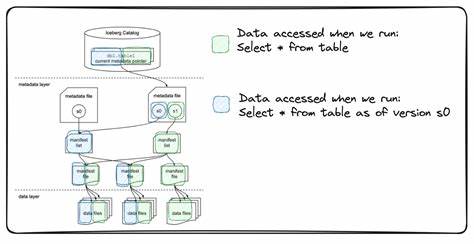
Während Formate wie Delta Lake lange Zeit ihre Daseinsberechtigung hatten, insbesondere bei großen Cloud-Plattformen wie Microsoft Fabric oder Databricks, gewinnt Iceberg mit seiner fortschrittlichen Architektur und zunehmend besseren Integration immer mehr Marktanteile. Die Akquisition von Tabular durch Databricks für mehrere Milliarden USD verdeutlicht den strategischen Wert von Iceberg und unterstreicht das Commitment zur Standardisierung und Offenheit. Neben der technologischen Komponente spielt das Thema Datenkatalog eine immer wichtigere Rolle. Ein Iceberg-Katalog dient als zentraler Index, der die Metadata-Verwaltung optimiert und zugleich den Zugriff auf die Tabellen sicher regelt. Dadurch wird die Daten-Governance deutlich verbessert, was für den Einsatz in Unternehmen mit hohen Compliance-Anforderungen unerlässlich ist.
Die Entwicklung hin zu einheitlichen Katalogen, wie beispielsweise dem Unity Catalog von Databricks, zeigt, dass Anbieter die Fragmentierung der Datenlandschaft überwinden und eine einheitliche Sicht auf Datenassets ermöglichen wollen. Der Einsatz von Managed Iceberg bringt außerdem den entscheidenden Vorteil mit sich, dass Unternehmen ihre Daten in einer echten Open-Source-Struktur speichern und flexibel mit verschiedenen Computekomponenten bearbeiten können. Der traditionelle Weg bedeutete oft hohen Aufwand bei der Migration oder Umstellung, weil Datenformate und APIs eng an den jeweiligen Anbieter gebunden waren. Mit Iceberg schaffen es Unternehmen hingegen, Daten in einem standardisierten, erweiterbaren Format abzulegen und nur die Compute Engine je nach Bedarf auszutauschen. Dieser Paradigmenwechsel senkt die Betriebskosten erheblich und verhindert gerade in Zeiten von Multi-Cloud-Strategien unliebsame Abhängigkeiten.
Allerdings ist die Nutzung von Managed Iceberg auch mit Herausforderungen verbunden. Die Verteilung der Daten auf viele kleine Dateien bringt Performance-Aspekte mit sich, die durch automatisierte Datei-Compaction und intelligente Abfragemethoden adressiert werden müssen. Zudem ist das Thema Daten-Governance komplexer, da mehrere Systeme an der Oberfläche koordiniert werden müssen. Nicht zuletzt erfordert die Einführung der ICE Stack-Architektur eine Umstellung der bestehenden Prozesse und eine enge Zusammenarbeit zwischen Dateningenieuren, Architekten und Anwendern. Aus Sicht der Dateningenieure ist Managed Iceberg dennoch ein wichtiger Schritt in Richtung moderner und flexibler Datenplattformen.
Die Möglichkeit, Daten einfach „time-travel“-fähig zu machen, also in der Zeit zurück zu unterschiedlichen Versionen zu springen, steigert die Zuverlässigkeit der Datenverarbeitung und macht Backup-Prozesse überflüssig oder zumindest deutlich einfacher. Darüber hinaus eröffnen sich dank offener Standards viele Synergien in der Entwicklung von Tools oder der Nutzung spezialisierter Analyseplattformen. Auch das Entwickler-Ökosystem um Apache Iceberg wächst rapide. Neue Plattformen wie ClickHouse oder MotherDuck unterstützen zunehmend Iceberg nativ, was eine reibungslose Integration von SQL-basiertem Analytics auf offenen Daten ermöglicht. Das bedeutet, dass Unternehmen auf vielfältige Weise analysieren und visualisieren können, ohne ihre Datensilos zu sprengen oder eigene Konnektoren entwickeln zu müssen.